HP OpenVMS Systems Documentation |
VAX MACRO and Instruction Set Reference Manual
10.10 Vector Memory Access Instructions
There are alignment, stride, address specifier context, and access mode
considerations for the vector memory access instructions.
Vector memory access instructions require their vector operands to be naturally aligned in memory. Longwords must be aligned on longword boundaries. Quadwords must be aligned on quadword boundaries. If any vector element is not naturally aligned in memory, an access control violation occurs. For further details, see Section 10.6.1, Vector Memory Management Exception Handling.
The scalar operands need not be naturally aligned in memory.
A vector's stride is defined as the number of memory locations (bytes)
between the starting address of consecutive vector elements. A
contiguous vector that has longword elements has a stride of four; a
contiguous vector that has quadword elements has a stride of eight.
The base address specifier used by the vector memory access
instructions is of byte context, regardless of the data type. Arrays
are addressed as byte strings. Index values in array specifiers are
multiplied by one, and the amount of autoincrement or autodecrement,
when either of these modes is used, is one.
A vector memory access instruction is executed using the access mode in
effect when the instruction is issued by the scalar processor.
This section describes VAX vector architecture memory instructions. VLD
Load Memory Data into Vector Register FormatVLDL [/M[0|1]] base, stride, VcArchitecture opcode cntrl.rw, base.ab, stride.rl
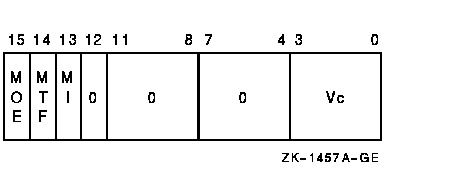
access control violation DescriptionThe source operand vector is fetched from memory and is written to vector destination register Vc. The length of the vector is specified by VLR. The virtual address of the source vector is computed using the base address and the stride. The address of element i (0 LEQU i LEQU (VLR-1)) is computed as {base+{i*stride}}. The stride can be positive, negative, or zero. VGATH
Gather Memory Data into Vector Register FormatVGATHL [/M[0|1]] base, Vb, VcArchitecture opcode cntrl.rw, base.ab
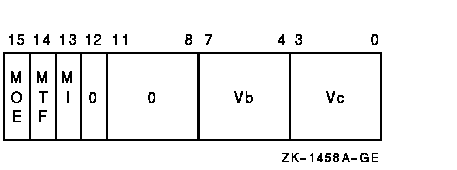
access control violation DescriptionThe source operand vector is fetched from memory and is written to vector destination register Vc. The length of the vector is specified by VLR. The virtual address of the vector is computed using the base address and the 32-bit offsets in vector register Vb. The address of element i (0 LEQU i LEQU (VLR-1)) is computed as {base+Vb[i]}. The 32-bit offset can be positive, negative, or zero. VST
Store Vector Register Data into Memory FormatVSTL [/0|1] Vc, base, strideArchitecture opcode cntrl.rw, base.ab, stride.rl

access control violation DescriptionThe source operand in vector register Vc is written to memory. The length of the vector is specified by the Vector Length Register (VLR). The virtual address of the destination vector is computed using the base address and the stride. The address of element i (0 LEQU i LEQU (VLR-1)) is computed as {base+{i*stride}}. The stride can be positive, negative, or zero. VSCAT
Scatter Vector Register Data into Memory FormatVSCATL [/0|1] Vc, base, VbArchitecture opcode cntrl.rw, base.ab
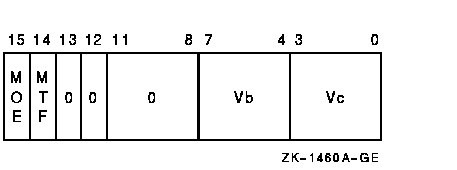
access control violation DescriptionThe source vector operand Vc is written to memory. The length of the vector is specified by the Vector Length Register (VLR) register. The virtual address of the destination vector is computed using the base address operand and the 32-bit offsets in vector register Vb. The address of element i (0 LEQU i LEQU (VLR-1)) is computed as {base+Vb[i]}. The 32-bit offset can be positive, negative, or zero. 10.11 Vector Integer InstructionsThis section describes VAX vector architecture integer instructions. VADDL
Vector Integer Add Formatvector + vector:Architecture vector + vector: opcode cntrl.rw scalar + vector: opcode cntrl.rw, addend.rl
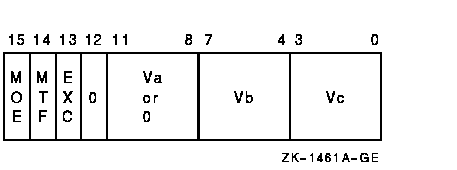
integer overflow DescriptionThe scalar addend or Va operand is added, elementwise, to vector register Vb and the 32-bit sum is written to vector register Vc. Only bits <31:0> of each vector element participate in the operation. Bits <63:32> of the elements of vector register Vc are UNPREDICTABLE. The length of the vector is specified by the Vector Length Register (VLR). VCMPL
Vector Integer Compare Formatvector--vector:Architecture vector--vector: opcode cntrl.rw scalar--vector: opcode cntrl.rw, src.rl
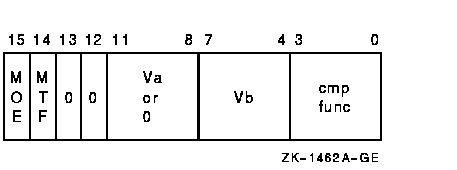
The condition being tested is determined by cntrl<2:0>, as follows:
1Vector integer compare instructions that specify reserved values of cntrl<2:0> produce UNPREDICTABLE results. DescriptionThe scalar or Va operand is compared, elementwise, with vector register Vb. The length of the vector is specified by the Vector Length Register (VLR). For each element comparison, if the specified relationship is true, the Vector Mask Register bit (VMR<i>) corresponding to the vector element is set to one; otherwise, it is cleared. If cntrl<MOE> is set, VMR bits corresponding to elements that do not match cntrl<MTF> are left unchanged. VMR bits beyond the vector length are left unchanged. Only bits <31:0> of each vector element participate in the operation. VMULL
Vector Integer Multiply Formatvector * vector:Architecture vector * vector: opcode cntrl.rw scalar * vector: opcode cntrl.rw, mulr.rl
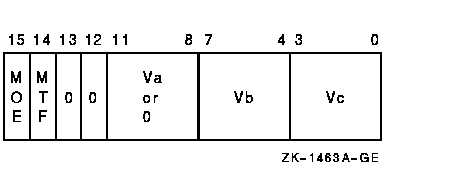
integer overflow DescriptionThe scalar multiplier or vector operand Va is multiplied, elementwise, by vector operand Vb and the least significant 32 bits of the signed 64-bit product are written to vector register Vc. Only bits <31:0> of each vector element participate in the operation. Bits <63:32> of the elements of vector register Vc are UNPREDICTABLE. The length of the vector is specified by the Vector Length Register (VLR). VSUBL
Vector Integer Subtract Formatvector--vector:Architecture vector--vector: opcode cntrl.rw scalar--vector: opcode cntrl.rw, min.rl
integer overflow DescriptionThe vector operand Vb is subtracted, elementwise, from the scalar minuend or vector operand Va. The 32-bit difference is written to vector register Vc. Only bits <31:0> of each vector element participate in the operation. Bits <63:32> of the elements of vector register Vc are UNPREDICTABLE. The length of the vector is specified by the Vector Length Register (VLR). 10.12 Vector Logical and Shift InstructionsThis section describes VAX vector architecture logical and shift instructions. VBIC, VBIS, and VXOR
Vector Logical Functions Formatvector op vector:Architecture op vector: opcode cntrl.rw op scalar: opcode cntrl.rw, src.rl
None. DescriptionThe scalar src or vector operand Va is combined, elementwise, using the specified Boolean function, with vector register Vb and the result is written to vector register Vc. Only bits <31:0> of each vector element participate in the operation. Bits <63:32> of the elements of Vb are written into bits <63:32> of the corresponding elements of Vc. The length of the vector is specified by the Vector Length Register (VLR). VSL
Vector Shift Logical Formatvector shift count:Architecture vector shift count: opcode cntrl.rw scalar shift count: opcode cntrl.rw, cnt.rl
None. DescriptionEach element in vector register Vb is shifted logically left or right 0 to 31 bits as specified by a scalar count operand or vector register Va. The shifted results are written to vector register Vc. Zero bits are propagated into the vacated bit positions. Only bits <4:0> of the count operand and bits <31:0> of each Vb element participate in the operation. Bits <63:32> of the elements of vector register Vc are UNPREDICTABLE. The length of the vector is specified by the Vector Length Register (VLR).
|