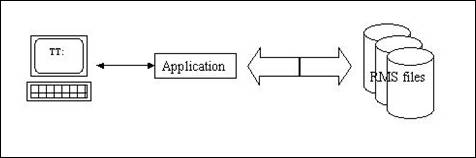
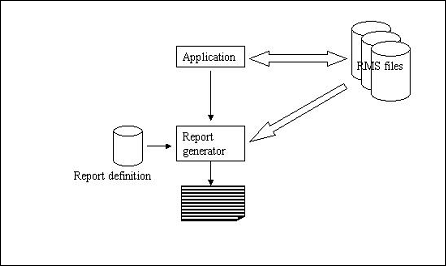
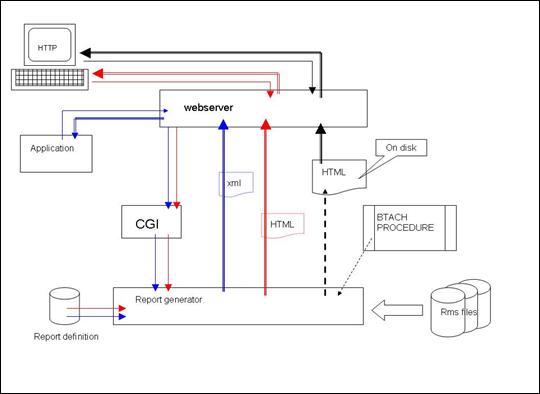
|
Installing different web servers is not a big problem
because their root directories are different, as are their logical names. The main issue is their configuration - each
should have its own set of ports to listen to.
The "reference" system - that is, the system that has been
delivered - gets a port on each server.
Since each programmer will use each of the three web
servers, each programmer was assigned a port on each server, to be used in the
URL to access the specific environment.
Added to these was the need for a port to access the web
interface in the DVLP environment, and one for a test environment (the version
to be delivered) to allow regression and acceptance testing on each server.
Actually, this is what "multiple webs" is all about: one web
server serving a number of different, unrelated webs. All three servers support
multiple webs, even though their naming differs.
It was decided that one machine - separate from DVLP and,
therefore, from the programmers - would be set up for testing and research.
On the DVLP system, configuration for each web server was as
follows:
- A virtual web for the reference system
- A virtual web for the DVLP system
- A virtual web for each of the developers
On the test system, the configuration contained:
- A virtual web for testing HTML interface
- A virtual web for testing application access
- At least one virtual web for research
Because of development of a common CGI procedure, and the
requirement to start with renewal of the reports, we started with the development
machine. Here, only SWS 1.3 was installed, and testing on the OSU web server
could be done on another machine.
For maintenance reasons, the web servers were installed off
the system disk under a single root directory, as shown in the following
example:

The next point was to map the structures for the web server in such a way that
it would be identical for each of them: Each web server needed to see the
identical structure. That meant only a single CGI procedure could handle all
requests. Another requirement was that the URL used could not contain any data
that was specific for one server, implying that any differences would need to
be handled by the CGI procedure. Furthermore, changing the URL was out of the
question.
The mapping of the structure meant correct definition of
logical names. This was already present in both the OSU and SWS web server
environments in the production environment, and so needed to be set up in the
DVLP and the programmers' environments. Because a single command procedure was
to handle all three servers, this issue was moved to the development of that
procedure.
First the structure that is immediately accessed by the web
server (that is, the CGI directory and the content below it) was to be set up.
Because the access of the web interface requires authentication on first
access, the standard [CGI-BIN] directory cannot be used, in stead CGI is a
different directory outside the server structure: it is located in the
environment it belongs to. The same applies to the web-interface files -
however, these are physically located in the application environment as
described earlier. The logical names however give it a look as a different
application, as if it was a production environment.
This works fine for one version, but if different versions
were to be accessed, a different CGI directory tree would be required for each
version of the application. This does not conform to the production environment
- one CGI procedure would have to be used for all versions. (The URL contains
all the needed data.) Changing the configuration is not an acceptable solution
because the process is error prone, and because it might disrupt existing
connections by requiring the server to be restarted.
The solution was found by creating an alias for the
directory into each of the web server roots (SET FILE /ENTER). That way, only
one physical CGI directory tree is used by all three the web servers, as shown
in the following figure:
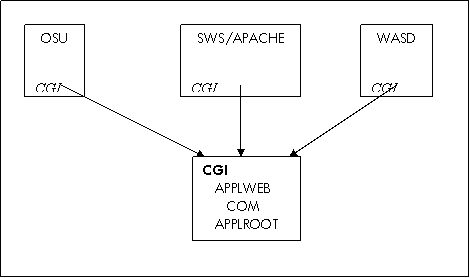
Any changes anywhere in this
directory tree can be directly accessed by any web server, so the whole
environment can be tested in parallel. Access to this central location has
become part of the procedures used by the deveolpment team.
On this system, just one environment was foreseen initially,
so this structure was examined in that environment first. Each web server
served on its own port: OSU on port 80 (because that was found to be the
hardest to configure), SWS on port 82, and WASD on port 84.
We installed a very simple web application on the CGI
directory - just a few HTML files and one procedure - as a proof of concept to
show this method would work. After that, we started converting the existing SWS
configuration on the development machine. The version that was last delivered
was already installed on port 80, and we kept it there. Its configuration,
however, was moved to the first "Virtual Host" entry in the configuration, as
shown in the following example:

Ports 81 to 90 were also mentioned as ports to listen to,
and for each port a configuration file was created to be included in the
server's configuration file. These files would hold the information of the
programmer's location, so each programmer had a separate web.
Each programmer was to have a separate CGI directory tree
that would resemble the live version I structure and files - including the CGI
procedure used. Starting with the current SWS-related procedure, only one
change was needed: where the live CGI procedure creates a logical to access the
local definition of working environment, the setup for the programmer's
environment could be served by a fixed one. Otherwise, a number of logicals
would have to be defined, one for each programmer and this is not needed
because the structure is well defined in this environment. This single
procedure actually mimics the user's login when setting up the programmer's
development area, causing the application logicals to be defined like the
programmer would have them defined. That is, the logicals refer first to the
programmer's directory, and second, to the DVLP area. Any procedure or image
running would now be run as if the programmer started it, as shown in the
following example:

In this case, the programmer is working on two different
versions of the application.
The next step was development
of a single CGI procedure to access the web interface, regardless of the web
server used. In the current configuration, two web servers were used: one for
OSU and one for SWS. These two needed to be joined to form one procedure that
was easily adapted to use with WASD (and any other web server). One big
advantage with the procedures for OSU and SWS web servers was the significant
similarity between them: The code examining and interpreting the URL to set up
the environment, to do some consistency and sanity checks, and actual running
the report generator were only minor issues. These parts were extracted and
placed in separate command files that were then called by the main procedure.
For development and testing, a few other command files were created, one of
them showing all symbols that are set up by the web server.
Major differences that showed
up are based on the difference in servers, and first could be partly solved by
determining the existence of the logicals that refered the root directories of
the server. That would be fine if either one or the other server was running.
However, in this construction, all three servers were active, so using these
logicals was not an option. The first possible solution was to
define a logical outside the server specifying the server used, but that was
abandoned because it was not feasible in this test configuration. In a live
system, this solution would require the intervention of a system manager or
operator in case the server was switched --- a task that is easily overlooked.
In the end, the solution was
to use process information. Since the CGI procedure is run in a subprocess of
the server, the name is derived from it. For SWS, its name would contain the
string "APACHE", and for WASD, the name would contain the string "HTTPD". If
neither is true, the server is OSU. That way, some primary setup can be done,
as shown in the following example:

The type of web server is
also important in the retrieval of server data. For instance, the OSU web
server uses a different method than SWS or WASD. For OSU, the URL up to the
question mark ("?") is passed as a second parameter to the CGI procedure, the
rest as a symbol. So the full URL needs to be contructed. On the other hand,
SWS and WASD get the full URL by symbols set by the server, but the names
differ.
For WASD, we found another
difference: data embedded in a <FORM> was found to be named differently
than the way SWS names the symbols. To be able to retrieve these arguments, an
extra translation was found to be necessary, as shown in the following example:

Otherswise, the program that
needs these values is unable to locate them (this image used the same library
that is included with WASD, and it worked with both SWS and WASD), as shown in
the following example:

The same symbol is used to do
some preparation of the output.
The preparation for HTML output was found to be different in
original procedures. The OSU-based procedure did not contain anything
particular for this, but the SWS procedure has the following defined:
$ write sys$output f$fao("!/<HTML>")
$!
|
This definition seemed to be
a requirement, and removing it caused a "Server Error", even when coded inside
a report. The definition was also found to be a requirement when using the
internally present debug mode output. This could again be solved by executing this
code only when required, and bypassing it when not applicable.
For XML output, the page
needed to be prepared differently for OSU and SWS as well. Both need to have
the header defined properly but in a different way, regardless of the server,
as shown in the following example:

The OSU web server requires
that the processing is "closed down" before continuing. Again, this is done based on
the symbol HTTP_SERVER, as shown in the following example:
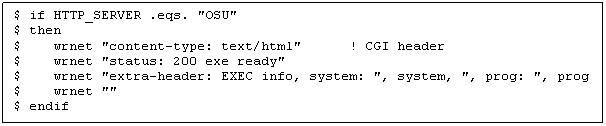
With some other
server-specific processing, the server-independent CGI procedure was completed
and could be used for processing plain HTML, generated reports, execution of
executables that produce and handle forms, as well as for displaying any type
of data.
However, WASD was found to
have one more drawback: If the disk accessed was an ODS-5 disk, it explicitly
changed the process parse style to "extended". This caused problems with the
report generator, which didn't recognize options passed in lowercase.
Investigations revealed that the routine that retrieved the options from the
command line used the LIB$GET_FOREIGN library function to retrieve the
options and parameters, and checked the
occurrence of its parameters - after converting the passed arguments to uppercase.
With traditional parsing, LIB$GET_FOREIGN converts the read lowercase data to
uppercase, so expected command-line options are indeed found. With an extended
parseing style, however, LIB$GET_FOREIGN does not perform this transformation,
so the same lowercase option is not recognized. This problem was solved simply by setting the parsing style to
"traditional" for all servers.
Once this procedure was
running, the translation of special characters in the URL data, as well as the
HTML and XML output, needed to be reviewed. This was the only change to be made
to the report definitions. Originally,
the existence of the logical APACHE$COMMON was sufficient to determine whether
translations were required or not, but again, in this configuration it was not
applicable. Because the symbol
HTTP_SERVER has been set up by the CGI procedure based on the calling server,
we can now use that symbol to perform, or bypass, the conversions.

The programmers were now able
to change files in their own environments without intefering with other
programmers' work, and the redesign of the web interface could be performed
separately from other activities.
Once this was set up, work
began on the second system. The work was hastened by the breakdown of the one
OSU server, which required a new server to be configured. This system was to be
used as a demonstration, test, and research system. Only one environment would
be active at a time, which made the configuration somewhat less complex.
Again, the web servers are installed off the
system disk, in their own directory, as on the development system. However, the
root directories are one level deeper, since it should be possible to
have multiple versions of a server at hand - though only one version of a
particular server can be active at a time, as shown in the following example:

In this example, OSU version 3.10, SWS version 2.1 and WASD
version 9.2 are active.
In this way, the active version can be easily switched, by
stopping the server, redefining the logical referring the root directory, and
restarting the server.
Installation off the system disk is required on this system
because of its nature: that is, it is destined to be used to test the
application on new versions of OpenVMS, as well as to test the web interface
under new versions of the web servers. One of the system's disks is kept free
for testing alone, so installing a new OpenVMS version would not require a
reinstallation of server software, and switching between versions would be as
easy as rebooting.
Like the development system, the CGI directory tree is
located outside the web server structure, but a link is made in each of them,
so here as well, the CGI directory seems to reside directly below the web
server. That allows the internal structure of the web interface to be exactly
the same as on the development system - no matter from what environment it is
copied. (If different environments were required, the construction within each
of the web servers would be similar as the configuration on the development
system. This however has not been installed at this moment.)
The CGI procedure that was created on the development
machine was copied to this machine and tested with all three servers. Changes
were applied on the development system and were copied back afterward. Once the procedure was finalized, both the
application and the web interface were copied to this machine.
|