$ verify = 'f$verify(0)
$
$! Get initial values for stats (this removes SPAWN overhead or the current
$! process values).
$
$ bio1 = f$getjpi (0, "BUFIO")
$ dio1 = f$getjpi (0, "DIRIO")
$ pgf1 = f$getjpi (0, "PAGEFLTS")
$ vip1 = f$getjpi (0, "VIRTPEAK")
$ wsp1 = f$getjpi (0, "WSPEAK")
$ dsk1 = f$getdvi ("sys$disk:","OPCNT")
$ tim1 = f$time ()
$
$ set noon
$ tik1 = f$getjpi (0, "CPUTIM")
$ set noverify
$
$! User command being timed:
$
$ 'p1' 'p2' 'p3' 'p4' 'p5' 'p6' 'p7' 'p8'
$
$ tik2 = f$getjpi (0, "CPUTIM")
$
$ bio2 = f$getjpi (0, "BUFIO")
$ dio2 = f$getjpi (0, "DIRIO")
$ pgf2 = f$getjpi (0, "PAGEFLTS")
$ vip2 = f$getjpi (0, "VIRTPEAK")
$ wsp2 = f$getjpi (0, "WSPEAK")
$ dsk2 = f$getdvi ("sys$disk:","OPCNT")
$ tim2 = f$time ()
$
$ tim = f$cvtime("''f$cvtime(tim2,,"TIME")'-''f$cvtime(tim1,,"TIME")'",,"TIME")
$ thun = 'f$cvtime(tim,,"HUNDREDTH")
$ tsec = (f$cvtime(tim,,"HOUR")*3600) + (f$cvtime(tim,,"MINUTE")*60) + -
f$cvtime(tim,,"SECOND")
$
$ bio = bio2 - bio1
$ dio = dio2 - dio1
$ pgf = pgf2 - pgf1
$ dsk = dsk2 - dsk1
$ vip = ""
$ if vip2 .le. vip1 then vip = "*" ! Asterisk means didn't change (from parent)
$ wsp = ""
$ if wsp2 .le. wsp1 then wsp = "*"
$
$ tiks = tik2 - tik1
$ secs = tiks / 100
$ huns = tiks - (secs*100)
$ write sys$output ""
$!
$ time$line1 == -
f$fao("Execution (CPU) sec!5UL.!2ZL Direct I/O !7UL Peak working set!7UL!1AS", -
secs, huns, dio, wsp2, wsp)
$ write sys$output time$line1
$!
$ time$line2 == -
f$fao("Elapsed (clock) sec!5UL.!2ZL Buffered I/O!7UL Peak virtual !7UL!1AS", -
tsec, thun, bio, vip2, vip)
$ write sys$output time$line2
$!
$ time$line3 == -
f$fao("Process ID !AS SYS$DISK I/O!7UL Page faults !7UL", -
f$getjpi(0,"pid"), dsk, pgf)
$ write sys$output time$line3
$ if wsp+vip .nes. "" then write sys$output -
" (* peak from parent)"
$ write sys$output ""
$
$! Place these output lines in the job logical name table, so the parent
$! can access them (useful for batch jobs to automate the collection).
$
$ define /job/nolog time$line1 "''time$line1'"
$ define /job/nolog time$line2 "''time$line2'"
$ define /job/nolog time$line3 "''time$line3'"
$
$ verify = f$verify(verify)
|
This example command procedure accepts multiple parameters, which include the RUN command, the name of the executable image to be run, and any parameters to be passed to the executable image.
$ TIMER RUN PROG_TEST $ $! User command being timed: $ $ RUN PROG_TEST.EXE; Execution (CPU) sec 45.39 Direct I/O 3 Peak working set 2224 Elapsed (clock) sec 45.96 Buffered I/O 18 Peak virtual 15808 Process ID 20A00999 SYS$DISK I/O 6 Page faults 64 |
If your program displays a lot of text, you can redirect the output from the program. Displaying text increases the buffered I/O count. Redirecting output from the program will change the times reported because of reduced screen I/O.
About system-wide tuning and suggestions for other performance
enhancements on OpenVMS systems, see the HP OpenVMS System Manager's Manual, Volume 2: Tuning, Monitoring, and Complex Systems.
5.2.2 Performance and Coverage Analyzer (PCA)
To generate profiling information, you can use the optional Performance and Coverage Analyzer (PCA) tool.
Profiling helps you identify areas of code where significant program execution time is spent; it can also identify those parts of an application that are not executed (by a given set of test data).
PCA has two components:
- The Collector gathers performance or test coverage
data on the running program and writes that data to a performance data
file. You can specify the image to be used (image selection) and
characteristics of the data collection (measurement and control
selection). Data collection characteristics include:
- Program counter (PC) sampling
- CPU sampling data
- Counts of program execution at a location
- Coverage of program locations
- Other information
- The Analyzer reads and processes the performance data file and displays the collected data graphically in the form of histograms, tables, and annotated source listings.
PCA works with related DECset tools LSE and the Test Manager. PCA provides a callable routine interface, as well as a command-line and DECwindows Motif graphical windowing interface. The following examples demonstrate the character-cell interface.
When compiling a program for which PCA will record and analyze data, specify the /DEBUG qualifier on the FORTRAN command line:
$ FORTRAN /DEBUG TEST_PROG.F90 |
On the LINK command line, specify the PCA debugging module PCA$OBJ using the Linker /DEBUG qualifier:
$ LINK /DEBUG=SYS$LIBRARY:PCA$OBJ.OBJ TEST_PROG |
When you run the program, the PCA$OBJ.OBJ debugging module invokes the Collector and is ready to accept your input to run your program under Collector control and gather the performance or coverage data:
$ RUN TEST_PROG PCAC> |
You can enter Collector commands, such as SET DATAFILE, SET PC_SAMPLING, GO, and EXIT.
To run the Analyzer, type the PCA command and specify the name of a performance data file, such as the following:
$ PCA TEST_PROG PCAA> |
You can enter the appropriate Analyzer commands to display the data in the performance data file in a graphic representation.
- On the windowing interface for PCA, see the Guide to Performance and Coverage Analyzer for VMS Systems.
- On the character-cell interface for PCA, see the Performance and Coverage Analyzer Command-Line Reference.
5.3 Data Alignment Considerations
The HP Fortran compiler aligns most numeric data items on natural boundaries to avoid run-time adjustment by software that can slow performance.
A natural boundary is a memory address that is a multiple of the data item's size (data type sizes are described in Table 8-1). For example, a REAL (KIND=8) data item aligned on natural boundaries has an address that is a multiple of 8. An array is aligned on natural boundaries if all of its elements are.
All data items whose starting address is on a natural boundary are naturally aligned. Data not aligned on a natural boundary is called unaligned data.
Although the HP Fortran compiler naturally aligns individual data items when it can, certain HP Fortran statements (such as EQUIVALENCE) can cause data items to become unaligned (see Section 5.3.1).
Although you can use the FORTRAN command /ALIGNMENT qualifier to ensure
naturally aligned data, you should check and consider reordering data
declarations of data items within common blocks and structures. Within
each common block, derived type, or record structure, carefully specify
the order and sizes of data declarations to ensure naturally aligned
data. Start with the largest size numeric items first, followed by
smaller size numeric items, and then nonnumeric (character) data.
5.3.1 Causes of Unaligned Data and Ensuring Natural Alignment
Common blocks (COMMON statement), derived-type data, and Compaq Fortran 77 record structures (STRUCTURE and RECORD statements) usually contain multiple items within the context of the larger structure.
The following declaration statements can force data to be unaligned:
- Common blocks (COMMON statement)
The order of variables in the COMMON statement determines their storage order.
Unless you are sure that the data items in the common block will be naturally aligned, specify either /ALIGNMENT=COMMONS=STANDARD or /ALIGNMENT=COMMONS=NATURAL) (set by specifying /FAST), depending on the largest data size used.
For examples and more information, see Section 5.3.3.1. - Derived-type (user-defined) data
Derived-type data members are declared after a TYPE statement.
If your data includes derived-type data structures, you should avoid specifying the FORTRAN command qualifier /ALIGNMENT= RECORDS=PACKED unless you are sure that the data items in derived-type data structures (and Compaq Fortran 77 record structures) will be naturally aligned.
If you omit the SEQUENCE statement (and /ALIGNMENT= RECORDS=PACKED), the /ALIGNMENT=RECORDS=NATURAL qualifier ensures all data items are naturally aligned. This is the default.
If you specify the SEQUENCE statement, the /ALIGNMENT= RECORDS=NATURAL qualifier is prevented from adding necessary padding to avoid unaligned data (data items are packed). When you use the SEQUENCE statement, you should specify data declaration order such that all data items are naturally aligned, or add the /ALIGNMENT=RECORDS=SEQUENCE compiler qualifier.
For an example and more information, see Section 5.3.3.2. - Compaq Fortran 77 record structures (RECORD and STRUCTURE statements)
Compaq Fortran 77 record structures usually contain multiple data items. The order of variables in the STRUCTURE statement determines their storage order. The RECORD statement names the record structure.
If your data includes Compaq Fortran 77 record structures, you should avoid specifying the FORTRAN command qualifier /ALIGNMENT=RECORDS= PACKED unless you are sure that the data items in derived-type data and Compaq Fortran 77 record structures will be naturally aligned.
For an example and more information, see Section 5.3.3.3. - EQUIVALENCE statements
EQUIVALENCE statements can force unaligned data or cause data to span natural boundaries. For more information, see the HP Fortran for OpenVMS Language Reference Manual.
To avoid unaligned data in a common block, derived-type data, or record structure (extension), use one or both of the following:
- For new programs or for programs where the source code declarations can be modified easily, plan the order of data declarations with care. For example, you should order variables in a COMMON statement such that numeric data is arranged from largest to smallest, followed by any character data (see the data declaration rules in Section 5.3.3).
- For existing programs where source code changes are not easily done or for array elements containing derived-type or record structures, you can use command line qualifiers to request that the compiler align numeric data by adding padding spaces where needed.
Other possible causes of unaligned data include unaligned actual arguments and arrays that contain a derived-type structure or Compaq Fortran 77 record structure.
When actual arguments from outside the program unit are not naturally aligned, unaligned data access will occur. HP Fortran assumes all passed arguments are naturally aligned and has no information at compile time about data that will be introduced by actual arguments during program execution.
For arrays where each array element contains a derived-type structure or Compaq Fortran 77 record structure, the size of the array elements may cause some elements (but not the first) to start on an unaligned boundary.
Even if the data items are naturally aligned within a derived-type structure without the SEQUENCE statement or a record structure, the size of an array element might require use of the FORTRAN /ALIGNMENT qualifier to supply needed padding to avoid some array elements being unaligned.
If you specify /ALIGNMENT=RECORDS=PACKED (or equivalent qualifiers), no padding bytes are added between array elements. If array elements each contain a derived-type structure with the SEQUENCE statement, array elements are packed without padding bytes regardless of the FORTRAN command qualifiers specified. In this case, some elements will be unaligned.
When /ALIGNMENT=RECORDS=NATURAL is in effect (default), the number of padding bytes added by the compiler for each array element is dependent on the size of the largest data item within the structure. The compiler determines the size of the array elements as an exact multiple of the largest data item in the derived-type structure without the SEQUENCE statement or a record structure. The compiler then adds the appropriate number of padding bytes.
For instance, if a structure contains an 8-byte floating-point number followed by a 3-byte character variable, each element contains five bytes of padding (16 is an exact multiple of 8). However, if the structure contains one 4-byte floating-point number, one 4-byte integer, followed by a 3-byte character variable, each element would contain one byte of padding (12 is an exact multiple of 4).
On the FORTRAN command /ALIGNMENT qualifier, see Section 5.3.4.
5.3.2 Checking for Inefficient Unaligned Data
During compilation, the HP Fortran compiler naturally aligns as much data as possible. Exceptions that can result in unaligned data are described in Section 5.3.1.
Because unaligned data can slow run-time performance, it is worthwhile to:
- Double-check data declarations within common block, derived-type data, or record structures to ensure all data items are naturally aligned (see the data declaration rules in Section 5.3.3). Using modules to contain data declarations can ensure consistent alignment and use of such data.
- Avoid the EQUIVALENCE statement or use it in a manner that cannot cause unaligned data or data spanning natural boundaries.
- Ensure that passed arguments from outside the program unit are naturally aligned.
- Check that the size of array elements containing at least one derived-type data or record structure (extension) cause array elements to start on aligned boundaries (see Section 5.3.1).
There are two ways unaligned data might be reported:
- During compilation
During compilation, warning messages are issued for any data items that are known to be unaligned (unless you specify the /WARN=NOALIGNMENTS qualifier). - During program execution by using the debugger
On Alpha systems, compile the program with the /SYNCHRONOUS_EXCEPTIONS (Alpha only) qualifier (along with /DEBUG and /NOOPTIMIZE) to request precise reporting of any data that is detected as unaligned.
Use the debugger (SET BREAK/UNALIGNED) command as described in Section 4.7 to check where the unaligned data is located.
On the /WARNINGS qualifier, see Section 2.3.51.
5.3.3 Ordering Data Declarations to Avoid Unaligned Data
For new programs or when the source declarations of an existing program can be easily modified, plan the order of your data declarations carefully to ensure the data items in a common block, derived-type data, record structure, or data items made equivalent by an EQUIVALENCE statement will be naturally aligned.
Use the following rules to prevent unaligned data:
- Always define the largest size numeric data items first.
- Add small data items of the correct size (or padding) before otherwise unaligned data to ensure natural alignment for the data that follows.
- If your data includes a mixture of character and numeric data, place the numeric data first.
Using the suggested data declaration guidelines minimizes the need to
use the /ALIGNMENT qualifier to add padding bytes to ensure naturally
aligned data. In cases where the /ALIGNMENT qualifier is still needed,
using the suggested data declaration guidelines can minimize the number
of padding bytes added by the compiler.
5.3.3.1 Arranging Data Items in Common Blocks
The order of data items in a COMMON statement determines the order in which the data items are stored. Consider the following declaration of a common block named X:
LOGICAL (KIND=2) FLAG INTEGER IARRY_I(3) CHARACTER(LEN=5) NAME_CH COMMON /X/ FLAG, IARRY_I(3), NAME_CH |
As shown in Figure 5-1, if you omit the appropriate FORTRAN command qualifiers, the common block will contain unaligned data items beginning at the first array element of IARRY_I.
Figure 5-1 Common Block with Unaligned Data

As shown in Figure 5-2, if you compile the program units that use the common block with the /ALIGNMENT=COMMONS=STANDARD qualifier, data items will be naturally aligned.
Figure 5-2 Common Block with Naturally Aligned Data

Because the common block X contains data items whose size is 32 bits or smaller, you can specify the /ALIGNMENT=COMMONS qualifier and still have naturally aligned data. If the common block contains data items whose size might be larger than 32 bits (such as REAL (KIND=8) data), specify /ALIGNMENT=COMMONS=NATURAL to ensure naturally aligned data.
If you can easily modify the source files that use the common block data, define the numeric variables in the COMMON statement in descending order of size and place the character variable last. This provides more portability, ensures natural alignment without padding, and does not require the FORTRAN command /ALIGNMENT=COMMONS=NATURAL (or equivalent) qualifier:
LOGICAL (KIND=2) FLAG INTEGER IARRY_I(3) CHARACTER(LEN=5) NAME_CH COMMON /X/ IARRY_I(3), FLAG, NAME_CH |
As shown in Figure 5-3, if you arrange the order of variables from largest to smallest size and place character data last, the data items will be naturally aligned.
Figure 5-3 Common Block with Naturally Aligned Reordered Data

When modifying or creating all source files that use common block data,
consider placing the common block data declarations in a module so the
declarations are consistent. If the common block is not needed for
compatibility (such as file storage or Compaq Fortran 77 use), you can
place the data declarations in a module without using a common block.
5.3.3.2 Arranging Data Items in Derived-Type Data
Like common blocks, derived-type data may contain multiple data items (members).
Data item components within derived-type data will be naturally aligned on up to 64-bit boundaries, with certain exceptions related to the use of the SEQUENCE statement and FORTRAN qualifiers. See Section 5.3.4 for information about these exceptions.
HP Fortran stores a derived data type as a linear sequence of values, as follows:
- If you specify the SEQUENCE statement, the first data item is in
the first storage location and the last data item is in the last
storage location. The data items appear in the order in which they are
declared. The FORTRAN qualifiers have no effect on unaligned data, so
data declarations must be carefully specified to naturally align data.
The /ALIGNMENT=SEQUENCE qualifier specifically aligns data items in a SEQUENCE derived-type on natural boundaries. - If you omit the SEQUENCE statement, HP Fortran adds the padding bytes needed to naturally align data item components, unless you specify the /ALIGNMENT=RECORDS=PACKED qualifier.
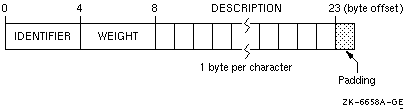
Consider the following declaration of array CATALOG_SPRING of derived-type PART_DT:
MODULE DATA_DEFS
TYPE PART_DT
INTEGER IDENTIFIER
REAL WEIGHT
CHARACTER(LEN=15) DESCRIPTION
END TYPE PART_DT
TYPE (PART_DT) CATALOG_SPRING(30)
.
.
.
END MODULE DATA_DEFS
|
As shown in Figure 5-4, the largest numeric data items are defined first and the character data type is defined last. There are no padding characters between data items and all items are naturally aligned. The trailing padding byte is needed because CATALOG_SPRING is an array; it is inserted by the compiler when the /ALIGNMENT=RECORDS=NATURAL qualifier (default) is in effect.
Figure 5-4 Derived-Type Naturally Aligned Data (in CATALOG_SPRING : ( ,))
| Previous | Next | Contents | Index |