使用 CMGR
本章会示范如何选择一个数据库作为当前数据库、如何建立一些用户定义字符、如何把对应的属性文件更新到当前的系统属性数据库中, 并如何建立字符属性列表文件以供参考。然后, 会简要描述其他 CMGR 命令, 如 REMOVE、EXTRACT 和 CONVERT FONT_SIZE。本章不会谈及诸如 CONVERT DATABASE 和 CONVERT FONT_SIZE 的命令。这些命令在第 3 章中已有描述。用户应参阅第 5 章的命令参考以了解每个 CMGR 命令的详细描述。
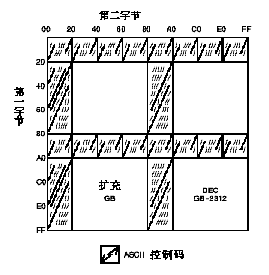
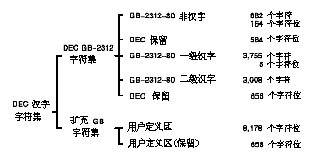
4.1 CMGR 中的字符代码和区说明
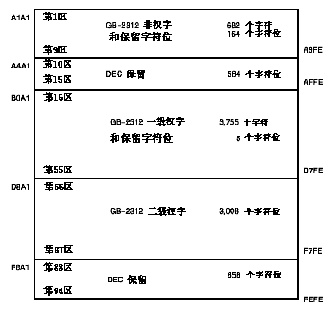
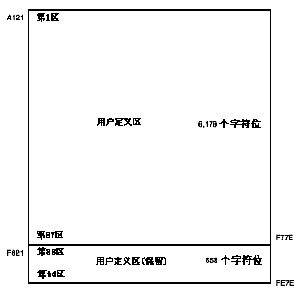
字符代码由区位码或字符的内码指定。在 CMGR 中, 内码以十六进制代码表示,首个字符为 "H"。例如, 如果具有两个八位字节的用户定义字符的第一个字节等于 161, 而使它的第二个字节等于 33 (两者均为十进制), 它的内码便应为"HA121"。此外, 这代码是在 DEC 汉字字符平面内左下象限的第一区中。在图 2-4中, 用户可看到用户定义区域是从 "HA121" 至 "HF77E", 而保留用户定义区域是 从 "HF821" 至 "HFE7E"。
另一个普遍地用以指定字符代码的方法是使用它的 "区位"。DEC 汉字字符平面的每个象限可以再分成 94 区, 每区有 94 个位置 (位)。图 2-3 和图 2-4 所示,每一区对应于象限中的一行。因此, 第一行便是第 1 区, 而最后一行是第 94 区。要区分在两个象限的代码, 右下象限中的区位码以 "0" 开头, 左下象限中的区位码则以 "1" 开头。如果不是以 "0" 或 "1" 开头, 默认为 "0" (右下象限)。
因此, 区位码 "00101" 或 "0101" 等于内码 "HA1A1"。区位码 "10101" 等于 "HA121"。注意, 如果区号或位号是单个数字, 便会添加一个零。
如果使用区位, 用户定义区域的范围是从 10101 至 18794, 而保留用户定义区域则从 18801 至 19494。
用户必须注意, 区位码输入方法与 VT382 终端所提供的输入方法相同。
区号是以 /QUADRANT 限定词来指定的。限定词可取 LOWER_RIGHT、LR 或 0 作为值来指定右下象限。也可取 LOWER_LEFT、LL 或 1 作为值来指定左下象限。/QUADRANT 的默认值是
/QUADRANT=LOWER_LEFT。
有关象限和平面的详情, 请参阅本手册的第 2 章或 OpenVMS/Hanzi 用户手册的第 2 章。
4.2 选择当前数据库
CMGR 共有三个系统属性数据库, 即 CMGR_DEFAULT、SONG 和 HEI 数据库。在任何时候, 其中一个数据库会成为当前数据库, CMGR 命令便在该当前数据库上操作。除非系统经理另行设置, 否则注册后的当前数据库应为默认数据库CMGR_DEFAULT。用户可以使用下述命令来转换到另一个数据库:
CMGR> SET DATABASE HEI
这命令把当前数据库设置为 HEI。
要转换回默认数据库, 用户可以使用:
CMGR> SET DATABASE/DEFAULT
要展示当前数据库是哪一个, 用户可以使用:
SHOW DATABASE
或者, 如果要知道系统中所有数据库的名称, 可使用下列命令:
CMGR> SHOW DATABASE/ALL
数据库名
-------------------------------
CMGR_DEFAULT
SONG
-> HEI
注意, 在数据库名左边的箭头指明该数据库是当前数据库。
在选择一个数据库作为当前数据库后, 用户便可开始使用其他 CMGR 命令来操纵该数据库。
4.3 使用 CMGR 字形编辑程序
第 1 步:
在 CMGR 中输入以下命令以调用编辑程序。由于 EDIT 命令的默认限定词是 /FULL/SIZE=ALL/LOG/LOAD_GLYPH, 因此允许您编辑用户定义字符的所有字符属性。请注意, 由于 CMGR 会自动添加 .PRE 和 .CVD 两个默认扩充名到两个输出文件, 因此不得在 /FULL 限定词中使用文件扩充名。
CMGR> EDIT TEMP
然而, 用这命令来调用的字形编辑程序不允许用户编辑保留用户定义区域的属性。如果需要编辑或使用保留用户定义字符, 应该发出以下命令:
CMGR> EDIT/RESERVED TEMP
如果不需要编辑整理特征, 输入以下命令:
CMGR> EDIT/FONT TEMP
这样, 便撤销所有与整理特征有关的特性, 只建立一个输出入文件 -- TEMP.PRE。
由于默认是 /SIZE=ALL, 因此用户可编辑任何一种可支持其大小的字形, 如 24x24、32x32 和 40x40。如果不需要编辑 32x32 和 40x40 大小的字形, 便应使用下列命令:
CMGR> EDIT/FONT/SIZE=24 TEMP
在启动编辑程序时, 编辑程序会装入一些字块模式以作显示。除非曾重置终端或关掉电源, 否则只需装入一次。为节省时间, 用户可在第二次 (或以后) 启动编辑程序时指定 /NOLOAD_GLYPH。
假定没有 TEMP.PRE 和 TEMP.CVD, 编辑程序便会在 EXIT 编辑程序时建立这两个文件。如果用户选择放弃编辑程序, 便不会建立输出文件。如果目录已包含其中一个或这两个文件, 编辑程序便把文件的内容读入内存 (称为内存记录) 以供编辑。在 EXIT 时, 便给这些文件建立新版本。
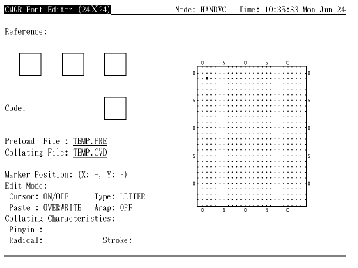
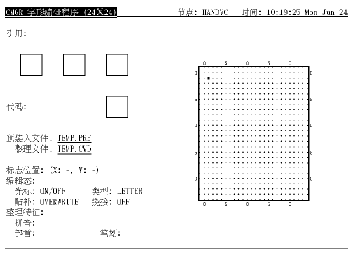
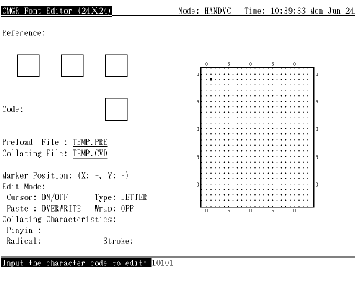
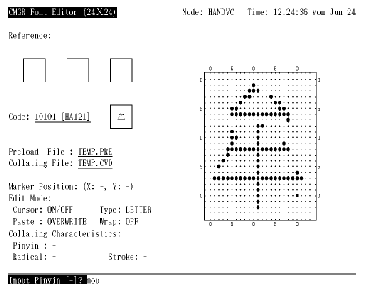
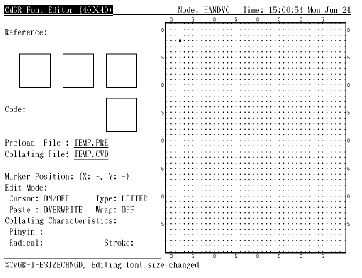
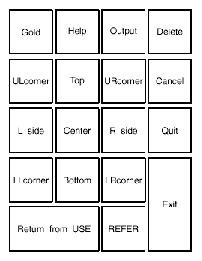
调用编辑程序以后, 便会在屏幕上显示象图 1-1 (或图 1-2, 取决于语言设置)所示的屏幕显示。用户可在任何时间按 <PF2> 以取得关于小键盘的求助资料。
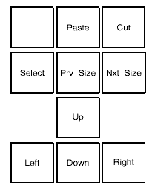
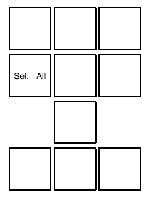
小键盘
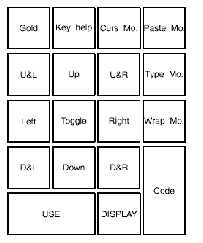
<====== 编辑小键盘 ======> <=========== 应用小键盘 ===========>
+--------+--------+--------+ +--------+--------+--------+--------+
| | | | | Gold | Help | Output | Delete |
| | Paste | Cut | | |Key Help|Curs Mo.|Past Mo.|
+--------+--------+--------+ +--------+--------+--------+--------+
|Sel. All| | | |ULcorner| Top |URcorner| Cancel |
| Select |Prv Size|Nxt Size| | U&L | Up | U&R |Type Mo.|
+--------+--------+--------+ +--------+--------+--------+--------+
| | | L side | Center | R side | Quit |
| Up | | Left | Toggle | Right |Wrap Mo.|
+--------+--------+--------+ +--------+--------+--------+--------+
| | | | |LLcorner| Bottom |LRcorner| |
| Left | Down | Right | | D&L | Down | D&R | Exit |
+--------+--------+--------+ +--------+--------+--------| |
| Return from USE | REFER | Enter |
| USE |DISPLAY | Code |
+-----------------+--------+--------+
Additional information available:
Application-keypad Editing-keypad Control-keys
Main-keypad
KEYPAD Subtopic?
第 2 步:
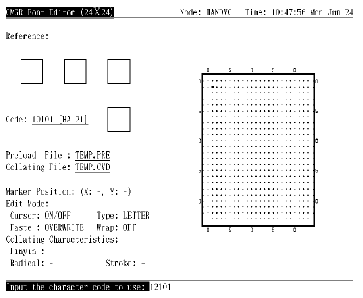
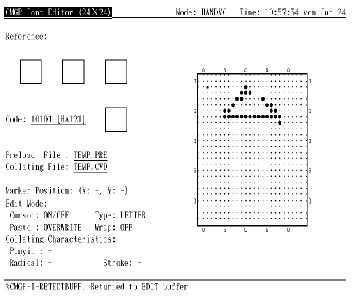
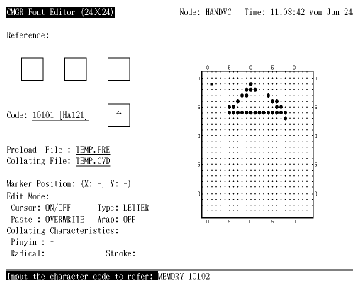
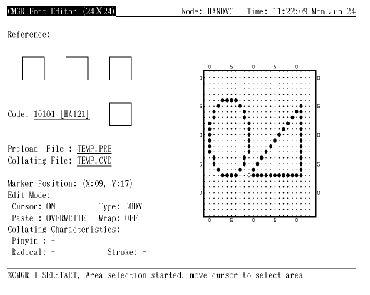
在编辑字形之前, 用户必须输入字符代码以作编辑。字符代码以区位码或内码格式指定 (第 4.1 节)。按 <ENTER> 来输入字符代码 (见图 4-1)。如果命令行中没用指定 /RESERVED, 用户只可输入用户定义区域内的代码, 否则会有出错信息显示出来。如果指定了 /RESERVED, 便可同时使用用户定义和保留用户定义字符代码。
有关用户定义字符的有效代码范围的详情, 请参阅第 2 章或在 CMGR 输入以下的命令:
CMGR> show character_set
DEC GB-2312 汉字字符集
代码范围 象限 区范围 字符种类
-------------- -------- ------------- ---------------
00101 - 00994 LR 1 - 9 DEC GB-2312 字符
01001 - 01594 LR 10 - 15 DEC GB-2312 保留字符
01601 - 08794 LR 16 - 87 DEC GB-2312 字符
08801 - 09494 LR 88 - 94 DEC GB-2312 保留字符
10101 - 18794 LL 1 - 87 用户定义字符
18801 - 19494 LL 88 - 94 保留用户定义字符
图4-1 按 <Enter> 输入代码
第 3 步:
用户现在可以使用小键盘、功能键、或控制键的各种功能来执行编辑。用户应注意所有 EDIT 态的默认设置: 光标态的 ON/OFF、贴补态的 OVERWRITE、字符类型的 LETTER 和绕回态的 OFF。这设置会影响编辑功能的大部分操作。用户可按小键盘功能键来更改任何一个 EDIT 态, 如按 <PF3> 来更改光标态。
EDIT 态:
|
1
|
光标态 -
有四种光标态 : ON/OFF、ON、OFF 和 MOVE。ON/OFF 态互换光标移过的象素。用户可利用应用小键盘来移动光标。ON 和 OFF 态分别用以开关光标移过的象素。MOVE 态仅允许光标移动, 对象素没有任何影响。
光标态也影响画几何图形。详情请参阅 6.6.10 节。
|
|
2
|
贴补态 -
贴补态可以是 OVERWRITE 或 OVERLAY。OVERWRITE 贴补态把贴补缓冲区重写到现有的象素上, 而 OVERLAY 贴补态则贴补到现有的象素上而不清除原来的象素。
贴补态也影响画几何图形。详情请参阅 6.6.10 节。
|
|
3
|
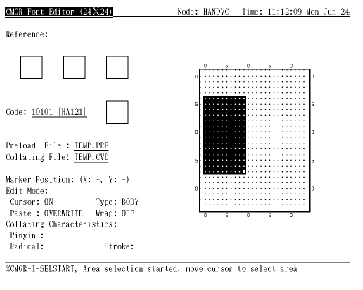
字符类型 -
在 CMGR 中定义了两种字符类型, 即 LETTER 类型和 BODY 类型。LETTER 类型不允许用户在位映象的最外边界 (24x24 大小的是一个象素, 而 32x32 及 40x40 大小的是两个象素) 编辑。BODY 类型则允许用户编辑整个位映象而没有任何限制。
|
|
4
|
绕回态 -
绕回态可以是 ON 或 OFF。它决定在光标移动超过边界时是否绕回。
|
用户可从当前的系统属性数据库中取出位映象字形模式来执行 CUT 功能, 然后使用 PASTE 功能把贴补缓冲区 (里面包含从字形剪切出来的部分) 插入正编辑的字形模式。USE 功能有助于执行这操作。
如果用户要使用的字形存储于默认数据库以外的另一个数据库内, 在启动编辑程序之前必须执行以下命令:
CMGR> SET DATABASE HEI
此命令把当前数据库设置为 HEI, 随后的 CMGR 命令都将在 HEI 数据库上操作(在这情形下, 编辑程序的 USE 功能将从 HEI 数据库读取字形)。
要调用 USE, 用户应按 <KP0> 键并输入关键字 (任选的) 和用户定义字符代码(或如果在命令行中指定了 /RESERVED, 亦可输入保留用户字符代码)。关键字可以是 "DATABASE" 或 "MEMORY", 默认是 "DATABASE"。它指定字形模式的源。 如果关键字是 "DATABASE" 或没有指定, CMGR 会从当前系统属性数据库中检索指定的用户定义字形模式。如果关键字是 "MEMORY", CMGR 便会从内存记录取出字形。
然后, 用户便可执行 SELECT 和 CUT 操作, 把合适的字形部分放进贴补缓冲区。最后, 按 <GOLD + <KP0> 返回原来的位映象, 并把该部分贴补 (按 <INSERT HERE>) 到当前编辑的位映象。在执行 PASTE 操作之前, 用户必须按光标移动功能键 (如 <GOLD> + <KP7>), 把光标移到适当的位置。
图 4-2、图 4-3、图 4-4、图 4-5、图 4-6 和 图 4-7 展示每一操作的屏幕显示。字形是从 HEI 系统属性数据库取出的。
图 4-8 和图 4-9 展示字形从内存记录取出时的情形。
用户可以执行类似的操作来组合最终的字形模式, 或使用编辑程序功能来建立新的字形模式。完成字形模式后或在编辑期间, 用户可以按 <KP.> 来在 DISPLAY窗口以实际大小显示字形 (见图 4-10)。
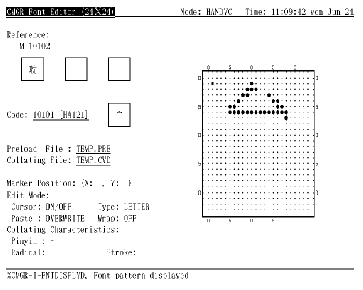
此外, 用户可能希望看到其他字符代码的实际大小字形。REFER 可提供这方面功能,它最多可显示当前系统属性数据库或内存记录中的三个字形。按 <GOLD> + <KP.>, 便有提示要求提供字符代码, 用类似 USE 功能那样的关键字和字符代码来回答, 字形便在其中一个 REFER 窗口内显示出来 (见图 4-11 和图 4-12)。
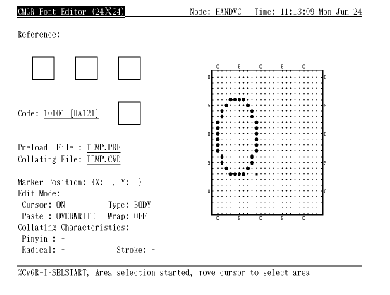
字形编辑程序也提供画几何图形或重新编排字形模式的功能。例如,用户可以首先 SELECT 一个区域并按 <O> 来画一个椭圆。图 4-13 和 图 4-14 展示此例子。
CMGR 编辑程序提供 MARK 功能以协助编辑。用户按 <GOLD> + <M> 便可在当前光标位置作标记。标记座标会展示出来。然后, 用户可以把光标移到任何位置。如有需要, 便可在任何时候按 <GOLD> + <G> 来跳回到标记的位置。图 4-15、图4-16、图 4-17、图 4-18 和图 4-19 展示使用标记功能来画三角形的例子。
有关详细的编辑程序功能列表和描述, 请参阅第 6 章。
图4-2 按 <KP0> 调用 USE 功能
图4-3 从 HEI 数据库装入字形模式
图4-4 按 <SELECT> + <KP3> X 6 + <KP6> X 11 选择区域
图4-5 按 <REMOVE> 把选定部分剪切到 Paste 缓冲区
图4-6 按 <GOLD> + <KP0> 返回到原来的位映象
图4-7 按 <GOLD> + <KP7> 前去适当的位置并按 <INSERT HERE> 贴补该 Paste 缓冲区
图4-8 键入关键字 "MEMORY" 使用内存记录
图4-9 内存字形装入 USE 缓冲区
图4-10 按 <KP.> 以实际大小显示当前字形
图4-11 按 <Gold> + <KP.> 并键入 "MEMORY 10102" 以在其中一个 REFER 窗口显示内存字形
图4-12 内存记录的 10102 字形显示在最左面的 REFER 窗口中
图4-13 按 <O> 之前首先选择区域
图4-14 按 <O> 画椭圆
图4-15 按 <Gold> + <M> 标记当前光标位置
图4-16 使用 <KP6> 和 <KP8> 画三角形的两边
图4-17 按 <Select> 开始选择
图4-18 通过按 <Gold> + <G> 完成选择, 光标会直接跳到标记位置
图4-19 按 <L> 完成三角形
第 4 步:
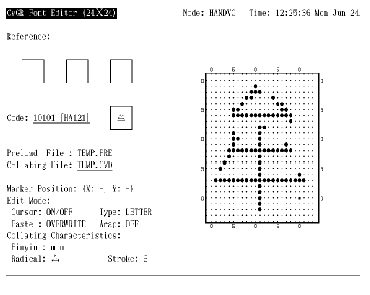
在 24x24 大小的字形模式的编辑完成之后, 用户可能希望编辑其他大小的字形。要这样做, 可按 <Next Screen>, 编辑程序的编排设计便更改成图 4-20 那样。现在, 用户可以编辑 32x32 大小的字形。
大小的次序是 24x24、32x32 和 40x40。按 <Next Screen> 便从 24x24 大小向前去到 40x40 大小, 然后再回到 24x24 大小。按 <Prev Screen> 便从 40x40大小反向前去到 24x24 大小, 然后再回到 40x40。用户可使用这两个键来转换到任一个大小并编辑该大小的字形。
为了帮助用户建立不同大小的字形, CMGR 提供了一个转换大小的功能。用户可以把同一代码另一大小的字形转换成当前大小。例如, 在使用 <Next Screen> 来转换成 32x32 大小之后, 按 <F18>, 便有提示询问转换前的大小。输入 24 并按<Return>, 24x24 大小的字形便会转换成 32x32 大小并装入 EDIT 缓冲区。图4-21 和图 4-22 说明整个过程。
图4-20 用于编辑 32x32 大小字形的屏幕编排设计
图4-21 按 <F18> 并键入 24
图4-22 把 24x24 大小的字形转换成 32x32
第 5 步:
编辑字形后, 按 <F17> 以输入整理特征。如果用户需要排序/合并字符, 此步骤是必需的。用户会收到提示要求他输入每个整理特征的值 (图 4-23)。输入所有整理特征后, 便会象图 4-24 所示的那样显示出来。
参阅附录 A 以了解有效整理值的完整列表。
图4-23 按 <F17> 输入整理特征
图4-24 显示的整理特征
第 6 步:
用户完成编辑后, 他可以选择:
-
按 <ENTER> 来把当前字形保存到内存记录, 并编辑另一个字形。
-
按 <GOLD> + <KP-> 来取消当前的编辑, 自上次按 <ENTER> 以来的更改都会丢失。例如, 用户先建立代码为 10101 的字形, 然后编辑代码为 10102 的字形。之后, 他回去编辑 10101 字形, 但对该字形作了一些更改之后, 他按 <GOLD> + <PF->。他所作的这些更改都会丢失, 但原来的内存字形模式则不受影响。
-
按 <GOLD> + <PF4> 来删除内存记录, 当前字符代码的所有数据都会丢失。
-
按 <GOLD> + <KP,> 来放弃编辑程序, 而不把驻留在内存中的当前编辑结果写入文件。
-
按 <GOLD> + <ENTER> 来退出编辑程序, 并把驻留在内存中的编辑结果保存到文件。
请参阅第 6 章以了解更多选项。
假定再编辑了两个用户定义字符 10102 和 10103, 然后输入 EXIT (<GOLD> + <ENTER>), 便产生 TEMP.PRE 和 TEMP.CVD 两个输出文件。这两个输出文件保存了用户的编辑结果 ( TEMP.PRE 保存位映象字形模式, 而 TEMP.CVD 保存整理特征)。之后, 编辑对话期便结束, 用户也返回 CMGR> 提示符。
4.4 CMGR UPDATE 命令
在产生用户属性文件 (TEMP.PRE 和 TEMP.CVD) 以后, 用户便可以用下述命令以这两个文件来更新当前的系统属性数据库:
CMGR> UPDATA TEMP
默认限定词是 /FULL/SIZE=ALL/CONFIRM=ALL/LOG, 意思是会按输入文件更新用户定义字符的所有属性, 并要求确认将要执行的所有更新。实际上, 用户可以输入 /NOCONFIRM 来撤销确认, 或输入 /CONFIRM=CONFLICT 来表示只在当前系统属性数据库中已有对应字符代码的属性时才需要确认。此外, 用户可以指定 /NOLOG 来撤销在更新操作期间显示通知信息。请注意, 此命令必须有 SYSPRV 特权才可执行。
与 EDIT 命令相同, 使用 /FULL 限定词时不能指定文件扩充名, 原因是 CMGR 会自动添加这两个扩充名。这说明这命令会以 TEMP.PRE 和 TEMP.CVD 来更新当前的系统属性数据库。
如果用户属性文件包含保留用户定义字符的属性, 用户便必须使用 /RESERVED 限定词, 否则, 更新操作便会失败。
如果用户只想更新预装入文件, 可输入:
CMGR> UPDATE/FONT TEMP
如果用户只要更新整理特征, 可输入:
CMGR> UPDATE/COLLATING TEMP
以下展示该 UPDATE 操作 (假定当前系统属性数据库是 CMGR_DEFAULT 并且已包含字符 10102 的两个属性)。
CMGR> UPDATE TEMP
%CMGR-I-UPGFONT,正在用文件DISK$:[USER]TEMP.PRE;1更新CMGR_DEFAULT
数据库的字形模式
更新代码 10101 的 24x24 大小的字形模式吗 ? [N]: Y
%CMGR-I-FONTUPD, 已更新代码 10101 的 24x24 大小的字形模式
%CMGR-I-FONTEXIST, 代码 10102 的 24x24 大小的字形模式已存在
更新代码 10102 的 24x24 大小的字形模式吗 ? [N]: ALL
%CMGR-I-FONTUPD, 已更新代码 10102 的 24x24 大小的字形模式
%CMGR-I-FONTUPD, 已更新代码 10103 的 24x24 大小的字形模式
%CMGR-I-FONTUPD, 已更新代码 10101 的 32x32 大小的字形模式
%CMGR-I-FONTEXIST, 代码 10102 的 32x32 大小的字形模式已存在
%CMGR-I-FONTUPD, 已更新代码 10102 的 32x32 大小的字形模式
%CMGR-I-FONTUPD, 已更新代码 10103 的 32x32 大小的字形模式
%CMGR-I-FONTUPD, 已更新代码 10101 的 40x40 大小的字形模式
%CMGR-I-FONTEXIST, 代码 10102 的 40x40 大小的字形模式已存在
%CMGR-I-FONTUPD, 已更新代码 10102 的 40x40 大小的字形模式
%CMGR-I-FONTUPD, 已更新代码 10103 的 40x40 大小的字形模式
%CMGR-I-UPGCOLL,正在用文件DISK$:[USER]TEMP.CVD;1更新 CMGR_DEFAULT
数据库的整理值 ...
%CMGR-I-COLLUPD, 已更新代码 10101 的整理值
%CMGR-I-COLLEXIST, 代码 10102 的整理值已存在
%CMGR-I-COLLUPD, 已更新代码 10102 的整理值
%CMGR-I-COLLUPD, 已更新代码 10103 的整理值
%CMGR-I-DBUPD, 已更新 CMGR_DEFAULT 系统数据库
用户可以看到通知信息, 这些信息说明您当前系统属性数据库已经包含字符10102 的属性。
4.5 CMGR SHOW TABLE 和 CMGR SHOW BITMAP 命令
CMGR SHOW TABLE 命令允许用户建立字符属性表, CMGR SHOW BITMAP 命令建立字形位映象的输出。这两个命令的主要目的是以表或位映象的格式展示系统属性数据库和用户属性文件的内容。使用 SHOW TABLE 命令来展示系统属性数据库中的字形属性表时, 可显示 DEC 汉字字符集内的所有区。至于在数据库上的其他SHOW TABLE 和 SHOW BITMAP 操作, 只限于展示用户定义字符或保留用户定义字符 (如果指定了 /RESERVED)。
4.5.1 展示用户属性文件的属性资料
如果用户只要展示属性文件 (TEMP.PRE 和 TEMP.CVD) 的内容但不展示位映象,他们可以输入:
CMGR> SHOW TABLE/USER=TEMP/OUTPUT=LIST1.LIS
/USER 限定词是指属性资料要从用户属性文件取出, 而不是从系统属性数据库取出。用户属性文件说明是这限定词的值。同样地, 如果指定 /FULL 限定词 (是默认限定词), 便不允许给用户属性文件指定扩充名。
如果用户要在屏幕上显示资料, 由于 /OUTPUT 的默认是 /OUTPUT=SYS$OUTPUT,因此他们可以省略限定词 /OUTPUT=LIST1.LIS。
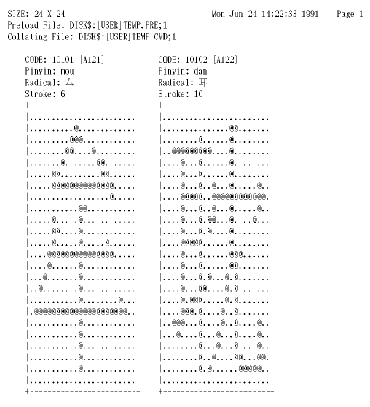
图 4-25 展示输出列表文件 LIST1.LIS 的内容。
图4-25 LIST1.LIS 的输出
如果用户只以字形编辑程序建立预装入文件而不建立整理数据文件,他们必须添加限定词 /FONT:
CMGR> SHOW TABLE/USER=TEMP/OUTPUT=LIST1.LIS/FONT
要展示预装入文件 TEMP.PRE 的位映象字形模式及其对应的整理特征, 用户可以输入:
CMGR> SHOW BITMAP/USER=TEMP/OUTPUT=LIST2.LIS/WIDTH=80
而且, /FULL/SIZE=ALL 会是默认。图 4-26 展示此命令中输出列表 LIST2.LIS部分。注意, 限定词 "/WIDTH=80" 限制输出列表的宽度为 80 列。宽度的有效值是 132 和 80, 默认是 132。
图4-26 LIST2.LIS 的输出列表
4.5.2 展示系统属性数据库的属性资料
要展示 HEI 系统属性数据库的属性表而不展示位映象, 用户应输入:
CMGR> SET DATABASE HEI
CMGR> SHOW TABLE/OUTPUT=LIST3.LIS 1-87
要展示 CMGR_DEFAULT 系统属性数据库的字符位映象, 应输入:
CMGR> SET DATABASE/DEFAULT
CMGR> SHOW BITMAP/OUTPUT=LIST4.LIS 10101-18794
再一次, /FULL/SIZE=ALL 是这两个命令的默认。如果用户要在终端屏幕上显示资料, 由于 /OUTPUT 的默认是 /OUTPUT= SYS$OUTPUT, 因此他们可以省略限定词 /OUTPUT。
每一个命令都接受一个参数。SHOW TABLE 的参数是区号, 而 SHOW BITMAP 的参数是字符代码。
用户可以指定区的列表或区的范围, 如下所述:
CMGR> SHOW TABLE 1-10, 30-40/QUADRANT=1
"1-10" 和 "30-40" 指定区的范围。用户必须使用连字符 "-" 来分隔该范围的上下限。
SHOW BITMAP 的参数是一个代码列表或代码范围:
CMGR> SHOW BITMAP 10101-11094, 13001-14094
同样地, 代码范围的上下限必须以连字符 "-" 分隔。
注意, 没有 /RESERVED 限定词, 便不能显示保留用户定义区域内的代码属性 (仅用 SHOW TABLE 的字形除外)。因此, 如果用户要展示保留用户定义区域内有关属性的资料, 应使用下列命令:
CMGR> SHOW TABLE/RESERVED 88-94/QUADRANT=1
CMGR> SHOW BITMAP/RESERVED 18801-19494
用户应该尝试指定不同组合的 /FULL、/FONT、/COLLATING、/SIZE、/USER、/SYSTEM 和 /RESERVED 来看看输出有什么差别。
4.6 CMGR REMOVE 和 COPY 命令
REMOVE 和 COPY 命令都需要有 SYSPRV 特权来执行, 它们在当前系统属性数据库上操作。REMOVE 用以除去当前系统属性数据库的字符属性, 而 COPY 则用以把字符属性从一个代码复制到另一个代码。
这两个命令都以 /FULL/SIZE=ALL 和 /LOG 作为默认。另外, REMOVE 命令以/CONFIRM 作为默认, 而 COPY 命令则以 /CONFIRM=ALL 为默认。
REMOVE 命令接受代码列表或代码范围作为其参数。COPY 命令只接受两个参数。第一个是源代码列表, 第二个是目的地代码列表。当源代码列表和目的地代码列表中的代码数目不同时, CMGR 便截断较长的那个参数。注意, 除非指定/RESERVED 限定词, 否则两个命令都不允许处理保留用户定义字符。
以下展示每个命令的例子, 当前数据库已设置为 CMGR_DEFAULT。
CMGR> REMOVE 10101-10103
%CMGR-I-RMGFONT, 正在从 CMGR_DEFAULT 数据库除去 24x24 大小的字形 模式...
除去代码 10101 的 24x24 大小的字形模式吗 ? [N]: Y
%CMGR-I-FONTRMD, 已除去代码 10101 的 24x24 大小的字形模式
除去代码 10102 的 24x24 大小的字形模式吗 ? [N]: N
除去代码 10103 的 24x24 大小的字形模式吗 ? [N]: ALL
%CMGR-I-FONTRMD, 已除去代码 10103 的 24x24 大小的字形模式
%CMGR-I-RMGFONT, 正在从 CMGR_DEFAULT 数据库除去 32x32 大小的字形 模式 ...
%CMGR-I-FONTRMD, 已除去代码 10101 的 32x32 大小的字形模式
%CMGR-I-FONTRMD, 已除去代码 10102 的 32x32 大小的字形模式
%CMGR-I-FONTRMD, 已除去代码 10103 的 32x32 大小的字形模式
%CMGR-I-RMGFONT, 正在从 CMGR_DEFAULT 数据库除去 40x40 大小的字形模式 ...
%CMGR-I-FONTRMD, 已除去代码 10101 的 40x40 大小的字形模式
%CMGR-I-FONTRMD, 已除去代码 10102 的 40x40 大小的字形模式
%CMGR-I-FONTRMD, 已除去代码 10103 的 40x40 大小的字形模式
%CMGR-I-RMGCOLL, 正在从 CMGR_DEFAULT 数据库除去整理值 ...
%CMGR-I-COLLRMD, 已除去代码 10101 的整理值
%CMGR-I-COLLRMD, 已除去代码 10102 的整理值
%CMGR-I-COLLRMD, 已除去代码 10103 的整理值
%CMGR-I-DBUPD, 已更新 CMGR_DEFAULT 系统数据库
CMGR> COPY/FONT/SIZE=24 10101-10102 12101
%CMGR-I-CPGFONT, 正在复制 CMGR_DEFAULT 数据库中的 24x24 大小的字 形模式...
%CMGR-I-FONTEXIST, 代码 12101 的 24x24 大小的字形模式已存在 把代码 10101 的 24x24 大小的字形模式复制至代码 12101 ? [N]: Y
%CMGR-I-FONTCPD, 已把代码 10101 的 24x24 大小的字形模式复制至代 码 12101
%CMGR-I-DBUPD, 已更新 CMGR_DEFAULT 系统数据库
4.7 CMGR EXTRACT CODE 和 CMGR EXTRACT REFERENCE 命令
EXTRACT 命令从系统属性数据库抽取字符属性资料来产生用户属性文件。用户可以用 EXTRACT CODE 命令来抽取字形和整理属性, 或用 EXTRACT REFERENCE 命令来只抽取字形属性。
EXTRACT CODE 命令的主要功能是为编辑或预装入 (只就预装入文件而言) 建立用户属性文件。EXTRACT REFERENCE 命令则为预装入建立预装入文件。
EXTRACT CODE 接受两个参数。一个是代码列表, 另一个是用户属性文件的说明:
CMGR> EXTRACT CODE 10101-10103 USER1
EXTRACT CODE 命令的默认限定词是 /FULL/SIZE=ALL, 因此, 上述命令会建立两个文件, 即 USER1.PRE 和 USER1.CVD。这两个文件分别包含代码 10101 至 10103 的所有大小的预装入序列和整理值。而且, 如果使用了 /FULL 限定词 (或默认), 便不允许在用户属性文件说明中指定文件扩充名。产生预装入文件和整理数据文件后, 用户便可以使用字形编辑程序来编辑文件或把 USER1.PRE 预装入到 终端以供显示。
如上所述, EXTRACT REFERENCE 只建立预装入文件, 它不具有 /FULL、/FONT 或/COLLATING 中的任何一个限定词。这命令的功能是检索一遍一些文本文件以找出用户定义字符, 并给那些用户定义字符建立预装入文件。建立的预装文件可以预装入到终端/打印机上。因此, 用户在发送文本文件前, 应把这文件发送到设备以便显示或打印那些用户定义字符。当然, 系统属性数据库必须包含那些用户定义字符代码的字形属性。
EXTRACT REFERENCE 也接受两个参数。一个是待检索的文本文件列表, 另一个是预装入文件的说明:
CMGR> EXTRACT REFERENCE USERDATA1.TXT, USERDATA2.TXT USER2
以上命令只建立一个文件 USER2.PRE。
用户可在这两个命令上使用限定词 /ENTRY_LIMIT 来控制最多只可输出多少属性记录到用户属性文件。原因是所有设备 (如 VT382) 都只有有限的内存空间来存储预装入字形模式。如果用完了内存空间, 任何输入的预装入字形模式便会重写到内存的现有字形模式上。因此, 如果必需的话, 用户应查看有关的设备参考手册来指定 /ENTRY_LIMIT 的值, 从而使预装入文件内的所有字形模式都可有效地预装入到设备上。如果不指定这限定词, CMGR 便不限制输出属性记录的数目。
再者, 如果用户要抽取保留用户定义字符, 便必须指定 /RESERVED。如果没有指定该限定词而 EXTRACT CODE 的代码列表却包含保留用户定义字符代码, 命令便会失败。至于 EXTRACT REFERENCE, 如果此命令在文本文件中找到一个保留用户定义字符, 便会显示一个警告信息。
如果用户要抽取其中一种或两种大小的字形而不是所有大小的字形,可使用/SIZE 限定词, 并指定大小作为限定词的值。例如:
CMGR> EXTRACT REFERENCE/SIZE=24 USERDATA1.TXT, USERDATA2.TXT USER2
4.8 CMGR CONVERT FONT_SIZE
CONVERT FONT_SIZE 命令把预装入文件中的字形模式从一种大小转换成另一种大小。这命令接受两个参数, 即输入预装入文件列表和输出预装入文件。系统会读取输入预装入文件中的预装入序列, 并把它们转换成 /SIZE 限定词指定的字形大小。转换后的预装入序列会写入输出预装入文件。例如:
CMGR> CONVERT FONT_SIZE FONT.PRE FONT32.PRE/SIZE=32
这命令会读取 FONT.PRE 中的所有字形, 并把它们转换成 32x32 的字形大小, 然后输出到 FONT32.PRE 文件。如果 FONT.PRE 包含同一个代码的重复预装入序列(可能属不同的字形大小), 那么会用最后一个预装入序列来执行转换。还有, 如果 FONT.PRE 中的预装入序列已是 32x32 大小的, 那么便只会复制该预装入序列到输出文件。
默认是 /SIZE=24。因此, 如果不指定限定词, 所有字形都会转换成 24x24 大小。
4.9 CMGR SHOW CHARACTER_SET 和 CMGR SHOW VERSION 命令
SHOW CHARACTER_SET 命令用以展示字符集资料。用户可以使用这些资料来确定CMGR 操作的有效代码范围和区范围。例如, 用户必须在 CMGR 的所有命令中指定有效的用户定义字符代码, 或者用户必须在一些具有 /RESERVED 限定词的命令中输入保留用户定义字符的有效代码范围。SHOW CHARACTER_SET 的输出展示如下。
CMGR> show character_set
DEC GB-2312 汉字字符集
代码范围 象限 区范围 字符种类
-------------- -------- ------------- ---------------
00101 - 00994 LR 1 - 9 DEC GB-2312 字符
01001 - 01594 LR 10 - 15 DEC GB-2312 保留字符
01601 - 08794 LR 16 - 87 DEC GB-2312 字符
08801 - 09494 LR 88 - 94 DEC GB-2312 保留字符
10101 - 18794 LL 1 - 87 用户定义字符
18801 - 19494 LL 88 - 94 保留用户定义字符
SHOW VERSION 命令展示当前 CMGR 的版本号, 如下所示:
CMGR> SHOW VERSION
%CMGR-I-VERSION, CMGR 第 2.0 版
4.10 CMGR HELP 和 EXIT 命令
任何时候用户都可在 CMGR 中键入 HELP, 然后在 "Topic?" 提示符处选择要阅读的题目。每当用户对使用任何一个 CMGR 命令有疑问, 都可以使用这命令。
CMGR> help
Information available:
Character_attributes CONVERT COPY EDIT EXIT EXTRACT
HELP REMOVE SET SHOW System_Attribute_Database
UPDATE User_Attribute_Files
Topic? copy
COPY
COPY 命令把源字符代码的字符属性复制到当前 "系统属性数据库" 的目的地字符代码。对每对源/目的地代码执行操作时不设任何缓冲, 因此, 下列命令会使 10101的属性被复制到从 10102 到 10194 的所有代码(10101 复制到 10102, 然后 10102复制到 10103, 如此类推。):
COPY 10101-10193 10102-10194
有关怎样选择当前数据库的详情, 请参阅 SET DATABASE 命令的题目。
您必须有 SYSPRV 特权, 才能执行这个命令。
语法:
COPY [/qualifiers] source-code[,...] destination-code[,...]
Additional information available:
Parameters Command_Qualifiers
/COLLATING /CONFIRM /FONT /LOG /RESERVED /SIZE
Examples
COPY Subtopic?
EXIT 命令用以退出 CMGR 并把用户送回 DCL 提示。
CMGR> EXIT
$
用户也可以使用 <CTRL/Z> 来退出 CMGR。
第 5 章
CMGR 命令参考
本章包含 CMGR 中所有可用命令的完整参考资料。
以下 DCL 命令可调用 CMGR 子系统:
$ CHARACTER_MANAGER
CMGR>
建议用户定义以下的外部命令:
$ CMGR :== $HSY$SYSTEM:CMGR
从而, CMGR 可以下列命令调用:
$ CMGR
CMGR>
CMGR> 提示符表示已进入 CMGR 子系统, 用户现在可以输入本区中描述的命令。
另一个使用 CMGR 命令的方法是在 DCL 命令级上直接地使用它们:
$ CMGR cmgr-commands [qualifiers] [parameters]
5.1 CONVERT DATABASE
把旧字形数据库文件 FONT1.DAT 中的字形转换到当前系统属性数据库。
语法
|
CONVERT DATABASE [/qualifiers]
|
|
命令限定词
|
默认
|
|
/[NO]CONFIRM
|
/CONFIRM
|
|
/[NO]LOG
|
/LOG
|
限制
-
用户必须有 SYSPRV 特权, 才能执行这命令。
提示
没有。
参数
没有。
描述
推出 CMGR 后, 便不再使用旧的 FONT.DAT、FONT1.DAT 系统字形数据库。要使用在 FONT1.DAT 中定义的字形模式, 系统经理必须在系统升级后使用 CONVERT DATABASE 命令来执行转换。
CONVERT DATABASE 命令读取在 HSY$SYSTEM:FONT1.DAT 中定义的字形模式, 并把他们转换成新的格式, 然后把字形存储到当前的系统属性数据库。
旧的字形系统仅支持 24x24 大小的字形。但采用 CMGR 后, 32x32 和 40x40 大小的字形也得到支持。在执行 CONVERT DATABASE 时, 系统会从 FONT1.DAT 中读取 24x24 大小的字形, 并把它们转换成 32x32 和 40x40 的大小。转换后的字形会装入当前的系统属性数据库。
然而, 旧的字形系统不支持整理特征。CMGR 无法从旧的字形系统中获得整理值。因此, 在执行 CONVERT DATABASE 命令后,整理特征仍未定义。
可用 SET DATABASE 命令来设置当前数据库。在多数情况下, 系统经理都需要把当前数据库设置为 CMGR_DEFAULT, 然后用 CONVERT DATABASE 来执行转换。这是因为 OpenVMS/Hanzi 的字形处理程序会在按需装入时使用 CMGR_DEFAULT 数据库的字形。
命令限定词
/CONFIRM
/NOCONFIRM
指定如果当前系统属性数据库内已有字形模式的定义时是否需要用户确认。
默认是 /CONFIRM。
回应确认请求时可接收的回答是:
|
YES, TRUE, 1
|
肯定的回答
|
|
NO, FALSE, 0
|
否定的回答
|
|
<RETURN>
|
默认的回答 (否定)
|
|
<CTRL/Z>
|
终止该命令
|
回答可以缩写。
/LOG
/NOLOG
控制是否显示通知信息。
默认是 /LOG。
例子
1 CMGR> CONVERT DATABASE
%CMGR-I-READFIL, 正在读文件 HSY$SYSTEM:FONT1.DAT
%CMGR-S-FONTCONVTD, 已转换 10101 的字形数据
%CMGR-S-FONTCONVTD, 已转换 10102 的字形数据
%CMGR-S-FONTCONVTD, 已转换 10103 的字形数据
%CMGR-I-FDBCONVEND, 总共把 3 个模式转换至 CMGR_DEFAULT 字形数据库
此命令转换 HSY$SYSTEM:FONT1.DAT 中的三个字形模式并把它们存储到当前的系统属性数据库 - CMGR_DEFAULT。
5.2 CONVERT FONT_FILE
把一个或多个字形文件中的所有字形转换到一个预装入文件。
语法
|
CONVERT FONT_FILE [/qualifiers] font-file[,...] preload-file
|
|
命令限定词
|
默认
|
|
/[NO]LOG
|
/LOG
|
限制
没有。
提示
_Font File: font-file[,...]
_Preload File: preload-file
参数
font-file[,...]
一个或多个字形文件的文件名。将转换这些字形文件中找到的用户定义字符和保留用户定义字符的所有字形模式。
preload-file
输出预装入文件的文件名。将建立这文件以包含转换的字形模式。
描述
在旧的字形系统中, 用户字形存储在字形文件里。在 CMGR 中, 用户字形存储在预装入文件里。要在 CMGR 下使用在字形文件中定义的字形,必须首先使用 CONVERT FONT_FILE 命令来把这些字形文件转换成预装入文件。
用户可在 CONVERT FONT_FILE 命令中输入字形文件列表, 便可把文件中的所有字形转换成预装入序列。这命令可转换用户定义字符和保留用户定义字符。这里没有 /RESERVED 限定词。
指定的预装入文件会建立起来以存储这些已转换的预装入序列。
命令限定词
/LOG
/NOLOG
控制是否显示通知信息
默认是 /LOG。
例子
1
CMGR> CONVERT FONT_FILE MYFONT.FON MYFONT.PRE
这命令把 MYFONT.FON 中的位映象字形模式转换成预装入序列, 并把它们放入 MYFONT.PRE。
5.3 CONVERT FONT_SIZE
把一个或多个预装入文件中的所有字形转换成其中一种支持的字形大小。
语法
|
CONVERT FONT_SIZE [/qualifiers] source-file[,...] destination-file
|
|
命令限定词
|
默认
|
|
/[NO]LOG
|
/LOG
|
|
/SIZE=font-size
|
/SIZE=24
|
限制
没有。
提示
_Input File: source-file[,...]
_Output File: destination-file
参数
source-file[,...]
一系列源预装入文件, 里面包含要转换的预装入序列。默认扩充名是 .PRE。
destination-file
存储已转换的预装入序列的输出预装入文件。转换后, 这文件中的所有预装入序列都会有指定的大小。
描述
CONVERT FONT_SIZE 命令把一个或多个预装入文件中的所有字形转换为其中一个支持的字形大小, 并把它们输出到一个目的地预装入文件。这命令可转换用户定义字符和保留用户定义字符。这里没有 /RESERVED 限定词。
要指定输出字形大小, 可使用 /SIZE 限定词。如果输入预装入文件已包含指定大小的字形, 预装入序列就只复制到输出文件。如果输入文件包含一个以上的同码预装入序列, 便使用最后的预装入序列来作转换。
命令限定词
/LOG
/NOLOG
控制是否显示通知信息。
默认是 /LOG。
/SIZE=font-size
指定要转换的字形大小。font-size 的有效值是 24、32 和 40, 它们分别表示24x24、32x32 和 40x40 的字形大小。
默认是 /SIZE=24
例子
1
CMGR> CONVERT FONT_SIZE/SIZE=32 MYFILE24.PRE MYFILE32.PRE
假定 myfile24.pre 包含 10101 的 24x24 字形。这命令会把该字形转换为 32x32 大小, 并把它存储入 myfile32.pre 。
5.4 COPY
把指定的源字符代码的字符属性复制到当前系统属性数据库的目的地字符代码。
语法
|
COPY [/qualifiers] source-code[,...] destination-code[,...]
|
|
命令限定词
|
默认
|
|
/COLLATING
|
/FULL
|
|
/[NO]CONFIRM=[condition]
|
/CONFIRM=ALL
|
|
/FONT
|
/FULL
|
|
/FULL
|
/FULL
|
|
/[NO]LOG
|
/LOG
|
|
/RESERVED
|
None
|
|
/SIZE=(font-size[,...])
|
/SIZE=ALL
|
限制
-
用户必须有 SYSPRV 特权, 才能执行这命令。
提示
_From: source-code[,...]
_To: destination-code[,...]
参数
source-code[,...]
destination-code[,...]
代码或代码范围的列表。代码可以是 "区位" 码或内码。代码范围是两个代码,以连字符分隔, 中间无空格。
"区位" 码由 5 个十进制数字组成, 第一位数字是任选的, 可以是 "0" 或 "1"。"0" 指定右下象限, 而 "1" 指定左下象限。如果不指定, 默认为 "0"。接下来的两位数字指定 "区", 最后两位数字指定 "位"。
内码是前面带 "H" 的十六进制代码。例如, HA121 即等于 10101。
如没有 /RESERVED 限定词, 只能对属于用户定义区域的代码执行复制。有关详情,请参阅 /RESERVED 的描述。
星号 "*" 可用来指定用户定义区域的所有代码。也就是说, "*" 等于 "10101-18794"。
代码范围可以跨越几区, 但不可以跨越象限。
描述
COPY 命令把在 source-code 代码列表中指定的每个代码的字符属性复制到在 destination-code 代码列表中的相应代码。如果两个代码列表具有不同的长度,较长列表中的任何多余代码都会被忽略。
对于每对源/目的地代码执行复制操作时不设任何缓冲, 因此, 下列命令会使 10101 的属性复制到从 10102 到 10194 的所有代码 (10101 复制到 10102, 然后 10102 复制到 10103, 依此类推):
CMGR> COPY 10101-10193 10102-10194
按照默认, 会复制所有字符属性。然而, 用户可以明确指定要复制那个字符属性。如果要复制字形模式, 用户可以指定要复制那种字形大小。
注意, 用户只在当前数据库中代码间复制字符属性。当前数据库可以 SET DATABASE 命令来设置。
命令限定词
/COLLATING
这字符属性限定词指定要复制整理特征。
这限定词不可以与 /FULL 一起使用。
/CONFIRM[=condition]
/NOCONFIRM
指定是否需要用户确认。确认级取决于条件。可能的条件有:
|
ALL
|
对每个事项都要求确认
|
|
CONFLICT
|
如果相应的字符属性已在目的地代码中登记, 就要求确认。
|
默认是 /CONFIRM=ALL。
回应确认请求时可接受的回答是:
|
YES, TRUE, 1
|
肯定的回答
|
|
NO, FALSE, 0
|
否定的回答
|
|
<RETURN>
|
默认的回答 (否定)
|
|
<CTRL/Z>, QUIT
|
终止该命令
|
回答可以缩写。
/FONT
这字符属性限定词指定要复制字形模式。
这限定词不可以与 /FULL 一起使用。
/FULL
指定要复制所有字符属性。
如果在命令行中没有指定字符属性限定词, 便假定为 /FULL。
这限定词不可以与其他字符属性限定词一起使用。
/LOG
/NOLOG
控制是否显示通知信息。
默认是 /LOG。
/RESERVED
要指定 "保留用户定义字符" 的代码时, 便指定这个限定词。
如果指定了这个限定词, 便可用星号 "*" 来指定用户定义区域内的所有代码以及保留用户定义区域中的代码。也就是说, "*" 等于 "10101-19494"。
/SIZE=(font-size[,...])
指定要复制的字形大小。font-size 的有效值是 24、32 和 40, 它们分别表示 24x24、32x32 和 40x40 的字形大小。用户也可以使用关键字 'ALL' 来表示要复制所有支持的字形大小。
默认是 /SIZE=ALL
这个限定词只与 /FONT 或 /FULL (默认) 一起使用时才有效。
例子
1
CMGR> COPY 10101 10102
这个命令把字符代码 10101 的所有字符属性复制到 10102。它将请求确认并通知您复制操作是成功还是失败。
2
CMGR> COPY/NOLOG/CONFIRM=CONFLICT/FONT HA121-Ha122 10111-10113
source-code 代码列表扩展到 10101、10102。
destination-code 代码列表扩展到 10111、10112、10113。
这个命令将把字形模式从 10101 复制到 10111, 同时从 10102 复制到 10112。目的地代码列表中的最后一个代码 (10113) 会被忽略。除非发生错误, 否则不会打印信息。此外, 除非两个 destination-code 已有字形模式定义, 否则不会请求确认。
5.5 EDIT
调用字形编辑程序来编辑用户属性文件中的字形模式。同时也可以在编辑字形模式时编辑其他字符属性。
语法
|
EDIT [/qualifiers] user-attribute-file
|
|
命令限定词
|
默认
|
|
/COLLATING
|
/FULL
|
|
/FONT
|
/FULL
|
|
/FULL
|
/FULL
|
|
/[NO]LOAD_GLYPH
|
/LOAD_GLYPH
|
|
/[NO]LOG
|
/LOG
|
|
/RESERVED
|
None
|
|
/SIZE=(font-size[,...])
|
/SIZE=ALL
|
限制
提示
_Input File: user-attribute-file
参数
user-attribute-file
用户属性文件的文件名。要编辑一个以上的属性, 文件名不能有扩充名, 而是使用默认的扩充名。
支持的用户属性文件:
|
字符属性
|
文件扩充名
|
文件类型
|
|
字形模式
|
.PRE
|
预装入文件
|
|
整理特征
|
.CVD
|
整理数据文件
|
描述
EDIT 命令调用 CMGR 字形编辑程序来编辑预装入文件中的字形模式。用户也可以使用字形编辑程序来编辑其他字符属性, 但不能在没有编辑字形时去编辑它们。
字形编辑程序只支持 VT382 终端。
如没有 /RESERVED 限定词, 只可以编辑属于用户定义区域的代码。有关详情请参阅 /RESERVED 的描述。
有关使用字形编辑程序的详情, 请参阅第 6 章 "字形编辑程序参考"。
命令限定词
/COLLATING
这字符属性限定词指定要编辑整理特征。
这限定词不可没有 /FONT 而单独使用, 原因是字形编辑程序不可以单独编辑整理特征。
这限定词不可以与 /FULL 一起使用。
/FONT
这字符属性限定词指定要编辑字形模式。
这限定词不可以与 /FULL 一起使用。
/FULL
指定要编辑所有字符属性。
如果在命令行中没有指定字符属性限定词, 就假定为 /FULL。
这个限定词不可以与其他字符属性限定词一起使用。
/LOAD_GLYPH
/NOLOAD_GLYPH
为了显示, 字形编辑程序使用一些特殊的字符字块。每当启动编辑程序, 便会把这些字块装入用户的终端。然而, 一旦装入字块, 除非用户重置终端, 否则它们不会被擦除。装入需花时间, 因此, 如果确信字块已装入, 为了节省时间, 就可以指定 /NOLOAD_GLYPH。
默认是 /LOAD_GLYPH。
/LOG
/NOLOG
控制是否显示通知信息。
默认是 /LOG。
/RESERVED
要编辑保留用户定义字符时, 便指定这个限定词。
如果调用编辑程序时不指定这个限定词, 便只能编辑用户定义区域的代码。
/SIZE=(font-size[,...])
指定要编辑的字形大小。font-size 的有效值是 24、32 和 40, 它们分别表示 24x24、32x32 和 40x40 的字形大小。用户也可以使用关键字 'ALL' 来表示要编辑所有支持的字形大小。
默认是 /SIZE=ALL。
例子
1
CMGR> EDIT/FONT/COLLATING/SIZE=ALL MYFILE
这命令调用字形编辑程序来编辑用户属性文件 myfile.pre; 以及 myfile.cvd;。如果默认目录中没有这两个文件, 便会把它们建立起来。在进入编辑对话期前, 会把特殊字块装入用户终端。同时用户可以编辑任何支持的字形大小。此外, 还会有信息显示以通知您在对话期内执行的操作是成功还是失败。
5.6 EXIT
终止 CMGR 对话期
语法
限制
没有。
提示
没有。
参数
没有。
描述
EXIT 命令终止 CMGR 对话期并从 CMGR 子系统返回 DCL。
用户也可以按 <CTRL/Z> 来终止 CMGR 对话期。
限定词
没有。
例子
1
CMGR> EXIT
$
EXIT 命令终止 CMGR 对话期并返回 DCL "$" 提示符。
5.7 EXTRACT CODE
按指定的字符代码从当前的系统属性数据库中抽取字符属性到用户属性文件。
语法
|
EXTRACT [/qualifiers] source-code[,...] user-attribute-file
|
|
命令限定词
|
默认
|
|
/COLLATING
|
/FULL
|
|
/ENTRY_LIMIT=number-of-characters
|
Nones
|
|
/FONT
|
/FULL
|
|
/FULL
|
/FULL
|
|
/[NO]LOG
|
/LOG
|
|
/RESERVED
|
None
|
|
/SIZE=(font-size[,...])
|
/SIZE=ALL
|
限制
没有。
提示
_Code: source-code[,...]
_Output file: user-attribute-file
参数
source-code[,..]
代码或代码范围的列表。代码可以是 "区位" 码或内码。代码范围是两个代码,以连字符分隔, 中间无空格。
"区位" 码由 5 个十进制数字组成, 第一位数字是任选的, 可以是 "0" 或 "1"。"0" 指定右下象限, 而 "1" 指定左下象限。如果不指定, 默认为 "0"。接下来的两位数字指定 "区", 最后两位数字指定 "位"。
内码是前面带 "H" 的十六进制代码。例如, HA121 即等于 10101。
如没有 /RESERVED 限定词, 只能抽取属于用户定义区域内的代码。有关详情, 请参阅 /RESERVED 的描述。
星号 "*" 可用来指定用户定义区域的所有代码。也就是说, "*" 等于 "10101-18794"。
代码范围可以跨越几区, 但不可以跨越象限。
user-attribute-file
用户属性文件的文件名。要抽取一个以上的属性, 文件名不能有扩充名, 因为会添加默认的扩充名。
支持的用户属性文件:
|
字符属性
|
文件扩充名
|
文件类型
|
|
字形模式
|
.PRE
|
预装入文件
|
|
整理特征
|
.CVD
|
整理数据文件
|
描述
EXTRACT CODE 命令把在 source-code 代码列表中所指定的每个代码的字符属性抽取到用户属性文件。如果文件已经存在, 便建立更高的版本。
这命令严格依据指定的代码列表来执行抽取并且会逐个抽取。
如果指定输入极限, 便不会抽取多于指定数目的字符属性。代码列表末尾的多余代码会被忽略。
按照默认, 会抽取指定代码的所有字符属性。然而, 用户可以明确指定要抽取的字符属性。如果要抽取字形模式, 用户可以指定要抽取的字形大小。
注意, 字符属性会从当前数据库抽取, 而当前数据可以由 SET DATABASE 命令来设置。
命令限定词
/COLLATING
这字符属性限定词指定要抽取整理特征。
这限定词不可以与 /FULL 一起使用。
/ENTRY_LIMIT=number-of-character
如果指定的话, 可限制抽取字符属性的最大数目。
/FONT
这字符属性限定词指定要抽取字形模式。
这限定词不可以与 /FULL 一起使用。
/FULL
指定要抽取所有字符属性。
如果在命令行中没有指定字符属性限定词, 就假定为 FULL。
这个限定词不可以与其他字符属性限定词一起使用。
/LOG
/NOLOG
控制是否显示通知信息。
默认是 /LOG。
/RESERVED
要指定保留用户定义字符的代码时, 便指定这个限定词。
如果指定了这个限定词, 可以用星号 "*" 来指定用户定义区域的所有代码以及保留用户定义区域中的代码。也就是说, "*" 等于 "10101-19494"。
/SIZE=(font-size[,...])
指定要抽取的字形大小。font-size 的有效值是 24、32 和 40, 它们分别表示 24x24、32x32 和 40x40 的字形大小。用户也可以使用关键字 'ALL' 来表示要抽取所有支持的字形大小。
默认是 /SIZE=ALL。
这个限定词只与 /FONT 或 /FULL (默认) 一起使用时才有效。
例子
1
CMGR> EXTRACT CODE/FONT/ENTRY_LIMIT=5 10101-10107 MYFILE
source-code 代码列表扩展到 10101、10102、10103、10104、10105、 10106、10107。
因为输入极限为 5, 10101 到 10105 内所有大小的字形模式都被抽取, 只忽略最后两个代码 10106 和 10107。
2
CMGR> EXTRACT CODE * MYFILE
这个命令抽取所有用户定义字符的全部字符属性。
5.8 EXTRACT REFERENCE
为指定文本文件中的用户定义字符把字形模式从当前的系统属性数据库中抽取到用户预装入文件。
语法
|
EXTRACT REFERENCE [/qualifiers] text-file[,...] preload-file
|
|
命令限定词
|
默认
|
|
/ENTRV_LIMIT=number-of-characters
|
Nones
|
|
/[NO]LOG
|
/LOG
|
|
/RESERVED
|
None
|
|
/SIZE=(font-size[,...])
|
/SIZE=ALL
|
限制
没有。
提示
_Text File: text-file[,...]
_Output file: preload-file
参数
text-file[,...]
文本文件名的列表。这些文本文件中的用户定义字符将会抽取其预装入序列。如果一个字符在文本文件中出现多次, 便仅抽取其预装入序列一次。
如果指定 /RESERVED, 便抽取保留用户定义字符。
preload-file
输出预装入文件的文件名。这个文件将被建立起来, 并包含抽取的预装入序列。
默认预装入文件的扩充名是 .PRE。
描述
EXTRACT REFERENCE 命令为指定文本文件列表中的每个用户定义字符抽取字形模式, 并把它们输出到指定的预装入文件。如果预装入文件已经存在, 便会建立更高版本。
如果指定了 /RESERVED 限定词, 便也可抽取保留用户定义字符。否则, 如在文本文件中找到保留用户定义字符, 便会显示警告信息。
它有助于在文本文件中找出用户定义字符的预装序列, 使用户可在打印文本文件前把序列预装到终端或打印机, 从而节省按需装入的时间。
抽取次序取决于用户定义字符在文本文件中的出现频率。频率越高,抽取越迟。这保证了当用户把字形预装入到没有足够字形 RAM 的终端时, 只丢掉频率较低的预装入序列。
如果指定了输入极限, 便不能抽取多于指定数目的字形模式。如果用户定义字符的个数大于指定的输入极限, 便会首先丢掉频率较低的多余用户定义字符。
按照默认, 会抽取所有可支持其大小的字形模式。然而, 用户也可用 /SIZE 限定词来指定要抽取的字形大小。
注意, 字形模式是从当前数据库中抽取的, 而当前数据库可以由 SET DATABASE命令来设置。
命令限定词
/ENTRY_LIMIT=number-of-character
如果指定的话, 可限制要抽取字形模式的最大数目。
/LOG
/NOLOG
控制是否显示通知信息。
默认是 /LOG。
/RESERVED
需要抽取保留用户定义字符时便指定这个限定词。
如果指定了这个限定词, 便会抽取文本文件中找到的用户定义区域的所有代码以及保留用户定义区域的代码。
/SIZE=(font-size[,...])
指定要抽取的字形大小。font-size 的有效值是 24、32 和 40, 它们分别表示 24x24、32x32 和 40x40 的字形大小。用户也可使用关键字 'ALL' 来表示要抽取所有支持的字形大小。
默认是 /SIZE=ALL。
例
1
CMGR> EXTRACT REFERENCE/SIZE=24 MYTEXT.TXT MYFILE.PRE
这个命令会根据 'mytext.txt' 中找到的用户定义字符, 从当前系统属性数据库中将 24x24 大小的字形模式抽取到预装入文件 'myfile.pre'。然后, 用户便可以在发送文件 'mytext.txt' 前, 将文件预装入到终端/打印机。字形将可用于终端/打印机而无须按需装入。
5.9 HELP
提供有关 CMGR 命令和其他相关题目的求助。
语法
|
HELP [topic]
|
|
|
命令限定词
|
默认
|
|
没有。
|
没有。
|
限制
没有。
提示
Topic? topic
参数
[topic]
指定用户想要求助的题目。如果没有指定题目, 便会显示所有题目的列表。
要离开求助, 可使用 <CTRL/Z> 或按 <RETURN> 几次。
描述
HELP 命令可显示某特定题目的求助。如果没有指定题目, 便会列出包含所有 CMGR 命令及一些有关题目的列表。
限定词
没有。
例子
1
CMGR> HELP COPY
HELP 命令显示 COPY 命令的求助文本。
5.10 REMOVE
把指定字符代码的字符属性从当前系统属性数据库中除去。
语法
|
REMOVE [/qualifiers] character-code[,...]
|
|
命令限定词
|
默认
|
|
/COLLATING
|
/FULL
|
|
/[NO]CONFIRM
|
/CONFIRM
|
|
/FONT
|
/FULL
|
|
/FULL
|
/FULL
|
|
/[NO]LOG
|
/LOG
|
|
/RESERVED
|
None
|
|
/SIZE=(font-size[,...])
|
/SIZE=ALL
|
限制
提示
_Code: character-code[,...]
参数
character-code[,...]
代码或代码范围的列表。代码可以是 "区位" 码或内码。代码范围是两个代码,以连字符分隔, 中间无空格。
"区位" 码由 5 个十进制数字组成, 第一位数字是任选的, 可以是 "0" 或 "1"。"0" 指定右下象限, 而 "1" 指定左下象限。如果没有指定, 默认为 "0"。接下来的两个数字指定 "区", 最后两个数字指定 "位"。
内码是前面带 "H" 的十六进制代码。例如, HA121 即等于 10101。
如没有 /RESERVED 限定词, 只能除去属于用户定义区域的代码。有关详情, 请参阅 /RESERVED 的描述。
星号 "*" 可用来指定用户定义区域的所有代码。也就是说, "*" 等于"10101-18794"。
代码范围可以跨越几区, 但不可以跨越象限。
描述
REMOVE 命令除去 character-code 代码列表中指定的每个代码的字符属性。它按照指定代码列表的次序逐个除去属性。
如果指定了 /RESERVED, 便可除去用户定义区域和保留用户定义区域的属性。否则, 只可除去用户定义区域的属性。
按照默认, 会除去所有字符属性。然而, 用户可以明确地指定要除去哪些字符属性。如果已除去字形模式, 用户可以指定哪些字形大小要删除。
注意, 字形模式是从当前数据库中除去的, 而当前数据库可以由 SET DATABASE 命令来设置。
命令限定词
/COLLATING
这个字符属性限定词指定要除去整理特征。
这个限定词不可以与 /FULL 一起使用。
/CONFIRM
/NOCONFIRM
指定是否需要用户确认。
默认是 /CONFIRM
回应确认请求时可接受的回答是:
|
YES, TRUE, 1
|
肯定的回答
|
|
NO, FALSE, 0
|
否定的回答
|
|
<RETURN>
|
默认的回答 (否定)
|
|
<CTRL/Z>, QUIT
|
终止该命令
|
回答可以缩写。
/FONT
这个字符属性限定词指定要除去字形模式。
这个限定词不可以与 /FULL 一起使用。
/FULL
指定要除去所有字符属性。
如果在命令行中没有指定字符属性限定词, 就假定为 /FULL。
这个限定词不可以与其他字符属性限定词一起使用。
/LOG
/NOLOG
控制是否显示通知信息。
默认是 /LOG。
/RESERVED
要指定保留用户定义字符的代码时, 可指定这个限定词。
如果指定了这个限定词, 可用星号 "*" 来指定用户定义区域内的所有代码以及保留用户定义区域内的代码。也就是说, "*" 等于 "10101-19494"。
/SIZE=(font-size[,...])
指定要除去的字形大小。font-size 的有效值是 24、32 和 40, 它们分别表示 24x24、32x32 和 40x40 的字形大小。用户也可以使用关键字 'ALL' 来表示要除去所有支持的字形大小。
默认是 /SIZE=ALL
这个限定词仅与 /FONT 或 /FULL (默认) 一起使用时才有效。
例子
1
CMGR> REMOVE 10101
这个命令将从当前系统属性数据库中除去 10101 代码的所有字符属性。在它实际删除属性之前, 会请求用户确认, 并且通知用户操作是成功还是失败。
5.11 SET DATABASE
把一个数据库设置为当前数据库。
语法
|
SET DATABASE [/qualifiers] [database-name]
|
|
命令限定词
|
默认
|
|
/DEFAULT
|
|
|
/LOG
|
/LOG
|
限制
没有。
提示
_Database: database-name
参数
[database-name]
指定要设置为当前数据库的数据库名。支持的数据库有 CMGR_DEFAULT、SONG 和HEI。
如果已指定 /DEFAULT 限定词, 便不允许使用该参数, 否则, 就必须指定这个参数。
描述
CMGR 有三个系统属性数据库, 名为 CMGR_DEFAULT、SONG 和 HEI。用户注册时,会以默认数据库 CMGR_DEFAULT 作为当前数据库 (除非由系统经理明确地另行设置)。所有随后的 CMGR 命令将在当前数据库上操作。要选择另一个数据库作为当前数据库, 可使用 SET DATABASE 命令。
SET DATABASE 命令使用逻辑名 CMGR$DATABASE_NAME 来保存当前数据库设置以供下次调用。
系统经理或用户可以在系统、组、作业或进程逻辑名表中, 把其中一个支持的数据库名定义为 CMGR$DATABASE_NAME 这逻辑名来取代默认。以后调用 CMGR, 便会以此数据库作为当前数据库。但如果把逻辑名定义为一个不支持的名, 便不能调用 CMGR。
要展示有关数据库的资料, 可使用 SHOW DATABASE 命令。
命令限定词
/DEFAULT
要重置当前数据库为默认数据库, 可使用这个限定词。
如果指定了这个限定词, 便不要指定 database-name 参数。
/LOG
控制是否显示通知信息。
默认是 /LOG。
例子
1
CMGR> SET DATABASE HEI
这个命令设置当前数据库为 HEI。会显示通知信息。
5.12 SHOW BITMAP
以位映象格式显示当前系统属性数据库和用户属性文件中指定代码的字形模式。
语法
|
SHOW BITMAP [/qualifiers] [character-code[,...]]
|
|
命令限定词
|
默认
|
|
/[NO]BACKGROUND
|
/BACKGROUND
|
|
/COLLATING
|
/FULL
|
|
/FONT
|
/FULL
|
|
/FULL
|
/FULL
|
|
/OUTPUT=output-file
|
/OUTPUT=SYS$OUTPUT
|
|
/RESERVED
|
None
|
|
/SIZE=(font-size[,...])
|
/SIZE=ALL
|
|
/SYSTEM
|
/SYSTEM
|
|
/USER
|
/SYSTEM
|
|
/WIDTH=80 or 132
|
/WIDTH=132
|
限制
没有。
提示
_Code: [character-code[,...]]
参数
[character-code[,...]]
代码或代码范围的列表。代码可以是 "区位" 码或内码。代码范围是两个代码,以连字符分隔, 中间无空格。
"区位" 码由 5 个十进制数字组成, 第一位数字是任选的, 可以是 "0" 或 "1"。"0" 指定右下象限, 而 "1" 指定左下象限。如果不指定, 默认为 "0"。接下来的两个数字指定 "区", 最后两个数字指定 "位"。
内码是前面带 "H" 的十六进制代码。例如, HA121 等于 10101。
如没有 /RESERVED 限定词, 只可指定属用户定义区域的代码。有关详情, 请参阅/RESERVED 的描述。
星号 "*" 可用来指定用户定义区域的所有代码。也就是说, "*" 等于"10101-18794"。
代码范围可以跨越几区, 但不可以跨越象限。
如果已在命令行中指定 /USER, 这个参数便是任选的。
描述
SHOW BITMAP 命令以位映象格式显示当前系统属性数据库中定义的以及来自预装入文件的预装入序列的字形的模式。其他字符属性也可和字形模式一起显示。用户可以用 /width 限定词来挑选 80 列或 132 列显示。
要显示当前系统属性数据库的位映象, 可使用 /SYSTEM 限定词并指定要显示的字符代码作为参数。注意, 当前数据库可用 SET DATABASE 命令来选择。要从用户属性文件来显示位映象, 可使用 /USER 限定词并指定用户属性文件作为/USER 限定词的值。在这种情形下, 字符代码列表参数是任选的。如果指定了字符代码列表, 便只显示属于该列表的代码位映象。如果没有指定字符代码列表,便会显示指定预装入文件中找到的所有字形模式。
如果需要指定保留用户定义字符的代码, 可使用 /RESERVED 限定词。
命令限定词
/BACKGROUND
/NOBACKGROUND
控制背景点是否显示在位映象中。
SHOW BITMAP 使用 '@' 来代表位映象上的 ON 象素 (前景), "." 来代表 OFF 象素 (背景)。
/COLLATING
这个字符属性限定词指定要显示整理特征。
因为 SHOW BITMAP 不可以单独显示整理特征, 所以这个字符属性限定词不可以没有 /FONT 而单独使用。
这个限定词不可以与 /FULL 一起使用。
/FONT
这个字符属性限定词指定要显示字形模式。
这个限定词不可以与 /FULL 一起使用。
/FULL
指定要显示所有字符属性。
如果在命令行中没有指定字符属性限定词, 就假定为 /FULL。
这个限定词不可以与其他字符属性限定词一起使用。
/OUTPUT=output-file
按照默认, 位映象会打印到 SYS$OUTPUT。使用这个限定词, 用户可以指示它打印到输出文件。
/RESERVED
要指定保留用户定义字符的代码时, 可指定这个限定词。
如果指定了这个限定词, 星号 "*" 可用来指定用户定义区域内的所有代码以及保留用户定义区域内的代码。也就是说, "*" 等于 "10101-19494"。
/SIZE=(font-size[,...])
指定要展示的字形大小。font-size 的有效值是 24、32 和 40, 它们分别表示 24x24、32x32 和 40x40 的字形大小。用户也可以使用关键字 "ALL" 来表示要展示所有支持的字形大小。
默认是 /SIZE=ALL。
/SYSTEM
使用 SHOW BITMAP 打印当前系统属性数据库中的字形模式和/或其他字符属性。使用这个限定词时, 必须指定 character-code 代码列表参数。然后, 便打印指定字符代码的所有位映象和其他字符属性。
这个限定词不可以与 /USER 一起使用。
如果在命令行中没有指定 /SYSTEM 或 /USER, 就假定为 /SYSTEM。
/USER=user-attribute-file
使用 SHOW BITMAP 来打印存储在用户属性文件中存储的字形模式和/或其他字符属性。使用这个限定词时, character-code 代码列表参数是任选的。如果指定该代码列表, 仅显示属于列表的那些代码位映象。如果没有指定, 便打印用户属性文件中的所有位映象及其他字符属性。
要显示一个以上的属性, user-attribute-file 的文件名不能有扩充名, 而是使用默认的扩充名。
支持的用户属性文件:
|
字符属性
|
文件扩充名
|
文件类型
|
|
字形模式
|
.PRE
|
预装入文件
|
|
整理特征
|
.CVD
|
整理数据文件
|
这个限定词不可以与 /SYSTEM 一起使用。
/WIDTH=80 或 132
指定要使用的显示列宽。
用户可以指定 80 或 132 列宽。如果不指定这个限定词或指定限定词却不指定值, 默认是 132 列。
例子
1
CMGR> SHOW BITMAP/FONT/OUTPUT=MYBITMAP.LIS/SIZE=(32,40) 10101
这个命令将以位映象格式把 10101 的 32x32 和 40x40 大小的字形模式打印到文件 'mybitmap.lis'。位映象会使用 '.' 作为背景。
2
CMGR> SHOW BITMAP/FONT/COLLATING/USER=MYFILE/NOBACKGROUND
这个命令会打印预装入文件 'myfile.pre' 中找到的所有代码的字形模式,并且也会打印整理数据文件 'myfile.cvd' 中代码的整理特征。位映象会以空白作为背景。
5.13 SHOW CHARACTER_SET
以表的格式显示当前的字符集。
语法
|
SHOW CHARACTER_SET
|
|
|
命令限定词
|
默认
|
|
没有。
|
没有。
|
限制
没有。
提示
没有。
参数
没有。
描述
SHOW CHARACTER_SET 命令以表的格式显示正在使用的字符集。它展示分配了哪个部分的字符平面给哪个字符种类。
限定词
没有。
例子
1
CMGR> SHOW CHARACTER_SET
SHOW CHARACTER_SET 命令显示 DEC 汉字字符集。
5.14 SHOW DATABASE
展示当前数据库以及所有支持的数据库名。
语法
|
SHOW DATABASE [/qualifiers]
|
|
命令限定词
|
默认
|
|
/ALL
|
|
限制
没有。
提示
没有。
描述
SHOW DATABASE 命令展示当前数据库名。
要展示系统上的所有数据库名, 可使用 /ALL 限定词。这些名字会以表的格式展示。
命令限定词
/ALL
如果指定这个限定词, 便会展示系统中的所有数据库名。当前数据库会有箭头标记。
例子
1
CMGR> SHOW DATABASE
这个命令展示当前数据库。当前数据库可能是 CMGR_DEFAULT、SONG 或 HEI。
5.15 SHOW TABLE
显示当前系统属性数据库中指定区内或用户属性文件中的字符代码表。
语法
|
SHOW TABLE [/qualifiers] [/positional-qualifiers]
[section-number[/positional-qualifiers][,...]]
|
|
命令限定词
|
默认
|
|
/COLLATING
|
/FULL
|
|
/FONT
|
/FULL
|
|
/FULL
|
/FULL
|
|
/OUTPUT=output-file
|
/OUTPUT=SYS$OUTPUT
|
|
/RESERVED
|
None
|
|
/SIZE=(font-size[,...])
|
/SIZE=ALL
|
|
/SYSTEM
|
/SYSTEM
|
|
/USER=user-attribute-file
|
/SYSTEM
|
|
定位限定词
|
默认
|
|
/QUADRANT=quadrant-name
|
/QUADRANT=ALL
|
限制
没有。
提示
_Section No.[section-number [/positional-qualifiers] [,...]]
参数
[section-number [/positional-qualifiers] [,...]]
区号或区范围的列表。区号是从 1 到 94 的整数。区范围是两个区号, 以连字符分隔, 中间无空格。
星号 "*" 可用来指定一个象限的所有区。也就是说, "*" 等于 "1-94"。
区号的解释取决于它所在的象限。默认是 DEC 汉字字符平面的左下象限。要指定右下象限中的区, 可使用 /QUADRANT 定位限定词。
/QUADRANT 限定词可置于两处以修改区号的意义。它可以置于 "TABLE" 一字之后及区号列表之前。这样可把限定词应用到整个区号列表。/QUADRANT 限定词也可以与每个区号或区范围并排放置。这样仅把限定词应用到该具体的区号或区范围。第二种情形会取代第一种情形。
在命令行中指定 /USER 时, 便不允许使用这个参数。
描述
SHOW TABLE 命令显示当前系统属性数据库中指定区内或用户属性文件中的字符代码表。这些代码表展示当前系统属性数据库或用户属性文件中有关字符属性的资料。
要显示当前系统属性数据库的代码表, 可使用 /SYSTEM 限定词。注意, 当前数据库可用 SET DATABASE 命令来选择。
要显示用户属性文件的代码表, 可使用 /USER 限定词。
有关所有区中的字形模式资料可随时显示。然而, 有关其他字符属性的资料, 则只可显示具有用户定义字符和保留用户定义字符的那些区的资料。(如果指定了/RESERVED)。
命令限定词
/COLLATING
这个字符属性限定词指定要显示有关整理特征的资料。
这个限定词不可以与 /FULL 一起使用。
/FONT
这个字符属性限定词指定要显示有关字符模式的资料。
这个限定词不可以与 /FULL 一起使用。
/FULL
指定要显示有关所有字符属性的资料。
如果在命令行中没有指定字符属性限定词, 就假定为 /FULL。
这个限定词不可以与其他字符属性限定词一起使用。
/OUTPUT=output-file
代码表通常打印到 SYS$OUTPUT。使用这个限定词, 用户可以指示把它打印到输出文件。
/RESERVED
要显示保留用户定义字符的所有属性时, 可指定这个限定词。
如果没有指定这个限定词, 便只显示保留用户定义字符的字形模式是否存在。
/SIZE=(font-size[,...])
指定要展示的字形大小。font-size 的有效值是 24、32 和 40, 它们分别表示 24x24、32x32 和 40x40 的字形大小。用户也可以使用关键字 'ALL' 来表示要展示所有支持的字形大小。
默认是 /SIZE=ALL。
这个限定词仅与 /FONT 或 /FULL (默认) 一起使用时才有效。
/SYSTEM
使用 SHOW TABLE 来打印当前系统属性数据库中的代码表。要使用这个限定词,就必须指定区号列表参数, 然后便会打印指定区的代码表。
这个限定词不可以与 /USER 一起使用。
在命令行中没有指定 /SYSTEM 或 /USER 时, 就假定为 /SYSTEM。
/USER=user-attribute-file
使用 SHOW TABLE 来打印指定用户属性文件的代码表。要使用这个限定词, 不可指定区号参数。用户属性文件中所有字符属性的资料将被打印。
要显示一个或以上的属性, user-attribute-file 的文件名就不能有扩充名, 因为会使用默认的扩充名。
支持的用户属性文件:
|
字符属性
|
文件扩充名
|
文件类型
|
|
字形模式
|
.PRE
|
预装入文件
|
|
整理特征
|
.CVD
|
整理数据文件
|
这个限定词不可以与 /SYSTSEM 一起使用。
定位限定词
/QUADRANT=quadrant-name
指定要使用字符平面上的哪个象限。象限名可接收的值是 LOWER_LEFT 和 LOWER_RIGHT。用户也可以使用 LL 或 1 来代表 LOWER_LEFT, 使用 LR 或 0 来代表 LOWER_RIGHT。
默认是 /QUADRANT=LL
这个限定词不可以与 /USER 一起使用。
例子
1
CMGR> SHOW TABLE/FONT/COLLATING 1/QUADRANT=1
这个命令显示当前系统属性数据库左下象限中区 1 的代码表。所有大小的字形模式和整理特征都将展示表中。
2
CMGR> SHOW TABLE/COLLATING/USER=MYFILE.CVD/OUTPUT=MYTABLE.LIS
这个命令把整理数据文件 'myfile.cvd' 的代码表打印到文件 'mytable.lis'。代码表包含整理数据文件中定义的所有整理特征的资料。
5.16 SHOW VERSION
显示 CMGR 的软件版本号。
语法
|
SHOW VERSION
|
|
命令限定词
|
默认
|
|
没有。
|
没有。
|
限制
没有。
提示
没有。
参数
没有。
描述
SHOW VERSION 命令显示 CMGR 的软件版本号。
当用户需要知道他们使用的 CMGR 的版本时, 这个命令便很有用。
限定词
没有。
例子
1
CMGR> SHOW VERSION
SHOW VERSION 命令显示 CMGR 的当前版本号。
5.17 UPDATE
使用用户属性文件中定义的字符属性来更新当前系统属性数据库。
语法
|
UPDATE [/qualifiers] user-attribute-file[,...]
|
|
命令限定词
|
默认
|
|
/COLLATING
|
/FULL
|
|
/[NO]CONFIRM[=condition]
|
/CONFIRM=ALL
|
|
/FONT
|
/FULL
|
|
/FULL
|
/FULL
|
|
/[NO]LOG
|
/LOG
|
|
/RESERVED
|
None
|
|
/SIZE=(font-size[,...])
|
/SIZE=ALL
|
提示
_Input File: user-attribute-file[,...]
参数
user-attribute-file[,...]
用户属性文件的文件名列表。要更新一个以上的属性, 文件名不能有扩充名, 因为会添加默认的扩充名。
支持的用户属性文件:
|
字符属性
|
文件扩充名
|
文件类型
|
|
字形模式
|
.PRE
|
预装入文件
|
|
整理特征
|
.CVD
|
整理数据文件
|
描述
UPDATE 命令用存储在用户属性文件中的字符属性插入或替换当前系统属性数据库的字符属性。如果没有指定 /RESERVED, 便只可更新用户定义字符。否则, 可更新用户定义字符和保留用户定义字符。
该命令会顺序地读取用户属性文件中找到的字符属性, 并在系统属性数据库中逐一更新这些属性。
按照默认, 会更新所有字符属性。然而, 用户可以明确地指定要更新哪个字符属性。如果已更新字形模式, 用户可以指定哪些字形大小要更新。
注意, 字符属性会更新到当前数据库, 而当前数据库可用 SET DATABASE 命令来设置。
命令限定词
/COLLATING
这个字符属性限定词指定要更新的整理特征。
这个限定词不可以与 /FULL 一起使用。
/CONFIRM[=condition]
/NOCONFIRM
指定是否需要用户确认。确认级取决于条件。可能的条件有:
|
ALL
|
对每个事项都要求确认。
|
|
CONFLICT
|
如果相应字符属性已在目的地代码中登记, 就要求确认。
|
默认是 /CONFIRM=ALL。
回应确认请求时可接受的回答是:
|
YES, TRUE, 1
|
肯定的回答
|
|
NO, FALSE, 0
|
否定的回答
|
|
<RETURN>
|
默认的回答 (否定)
|
|
<CTRL/Z>, QUIT
|
终止该命令
|
回答可以缩写。
/FONT
这个字符属性限定词指定要更新的字形模式。
这个限定词不可以与 /FULL 一起使用。
/FULL
指定要更新所有字符属性。
如果在命令行中没有指定字符属性限定词, 就假定为 /FULL。
这个限定词不可以与其他字符属性限定词一起使用。
/LOG
/NOLOG
控制是否显示通知信息。
默认是 /LOG。
/RESERVED
要更新保留用户定义字符的属性时, 可指定这个限定词。
/SIZE=(font-size[,...])
指定要更新的字形大小。font-size 的有效值是 24、32 和 40, 它们分别表示 24x24、32x32 和 40x40 的字形大小。用户也可以使用关键字 'ALL' 来表示要更新所有支持的字形大小。
默认是 /SIZE=ALL。
这个限定词仅与 /FONT 或 /FULL (默认) 一起使用时才有效。
例子
1
CMGR> UPDATE/FONT/COLLATING MYFILE
这个命令用 'myfile.pre' 中定义的字形模式和 'myfile.cvd' 中定义的整理特征来更新当前系统属性数据库。它将请求确认, 并且通知用户更新是成功还是失败。
2
CMGR> UPDATE/NOLOG/CONFIRM=CONFLICT/FONT/SIZE=24 MYFILE.PRE
这个命令用 'myfile.pre' 中定义的 24x24 大小的字形模式来更新当前系统属性数据库。除非发生错误, 否则不打印信息。此外, 除非目的地代码已定义字形模式, 否则不会请求确认。
第 6 章