|
|
|
|
HP C++
|
| Previous | Contents | Index |
This chapter discusses the features and characteristics specific to the HP C++ implementation, including pragmas, predefined names, numerical limits, and other implementation-dependent aspects of the language definition.
This section describes pragmas, predefined names, and limits placed on the number of characters and arguments used in C++ programs.
The #pragma preprocessor directive is a standard method for implementing features that differ from one compiler to the next. This section describes pragmas specifically implemented in the C++ compiler for OpenVMS systems.
The following #pragma directives are subject to macro expansion. A macro reference can occur anywhere after the pragma keyword.
| builtins | inline | linkage 1 | use_linkage 1 |
| dictionary | noinline | module | extern_model |
| member_alignment | message | define_template | extern_prefix |
This manual displays keywords used with #pragma in lowercase letters. However, these keywords are not case sensitive.
The #pragma builtins directive enables the C++ built-in functions that directly access processor instructions. If the pragma does not appear in your program, the default is #pragma nobuiltins .
C++ supports the #pragma builtins preprocessor directive for compatibility with VAX C, but it is not required.
The #pragma define_template directive instructs the compiler to instantiate a template with the arguments specified in the pragma. This pragma has the following syntax:
|
#pragma define_template identifier |
For example, the following statement instructs the compiler to instantiate the template mytempl with the arguments arg1 and arg2 :
#pragma define_template mytempl<arg1, arg2> |
For more information on how to use templates with the
#pragma
define_template
directive, see Section 5.2.
The #pragma environment directive offers a way to single-handedly set, save, or restore the states of context pragmas. This directive protects include files from contexts set by encompassing programs and protects encompassing programs from contexts that could be set in header files that the encompassing programs include.
On OpenVMS systems, the #pragma environment directive affects the following pragmas:
#pragma member_alignment
#pragma message
#pragma extern_model
#pragma extern_prefix
This pragma has the following syntax:
|
#pragma environment command_line #pragma environment header_defaults #pragma environment restore #pragma environment save |
command_line
Sets, as specified on the command line, the states of all the context pragmas. You can use this pragma to protect header files from environment pragmas that take effect before the header file is included.header_defaults
Sets the states of all the context pragmas to their default values. This is almost equivalent to the situation in which a program with no command line options and no pragmas is compiled; except that this pragma sets the pragma message state to #pragma nostandard , as is appropriate for header files.save
Saves the current state of every pragma that has an associated context.restore
Restores the current state of every pragma that has an associated context.
Without requiring further changes to the source code, you can use #pragma environment to protect header files from things like language extensions and enhancements that might introduce additional contexts.
A header file can selectively inherit the state of a pragma from the including file and then use additional pragmas as needed to set the compilation to non-default states. For example:
#ifdef __PRAGMA_ENVIRONMENT #pragma __environment save (1) #pragma __environment header_defaults (2) #pragma member_alignment restore (3) #pragma member_alignment save (4) #endif . . /* contents of header file */ . #ifdef __PRAGMA_ENVIRONMENT #pragma __environment restore #endif |
In this example:
Thus, the header file is protected from all pragmas, except for the member alignment context that the header file was meant to inherit.
The #pragma extern_model directive controls the compiler's interpretation of data objects that have external linkage. You can use this pragma to select the global symbol model to use for extern s. The default is the relaxed refdef model.
Take great care when using the non-default extern_model . The main purpose of extern_model is to allow C++ to share global data with code written in other languages. Declarations that cause data to be allocated according to the C++ object model, that is, declarations for other than POD (Plain Old Data) objects, cannot generally be shared reliably with other languages, and should only appear in regions of source that are subject to the default extern_model of relaxed_refdef . Within regions of source subject to an extern_model other than relaxed_refdef , declarations that allocate data with names visible to the linker should be limited exclusively to POD types. In particular, declaring a C++ class containing a static data member within such a region may produce unintended behavior. |
After you select a global symbol model with #pragma extern_model , the compiler treats all subsequent declarations of objects of the extern storage class accordingly, until it encounters another #pragma extern_model directive.
The global symbol models are as follows:
The C language permits objects declared with the const type qualifier to be allocated in read-only memory, and when the C compiler allocates a psect for a const object, it marks that section as read-only. This is not compatible with the C++ conventions because the C++ language permits objects with static storage duration to be initialized with values computed at run-time (before the main function gains control). When the C++ compiler allocates a psect for such a declaration, it marks the psect writable. Normally, only one compilation (the one responsible for initialization) will allocate a psect for a const object, and there is no problem. But under the common_block extern model, the compilers will always allocate a psect for such a declaration, leading to a "conflicting attributes" warning from the linker if the same const -qualified declaration is processed by both C and C++. It is best to avoid use of the common_block extern model when const objects with external linkage are shared between C and C++. If the common_block model must be used, then the const type qualifier should be removed (for example, by preprocessor conditionals) from the declaration processed by the C compiler. |
|
#pragma extern_model save |
|
#pragma extern_model restore |
|
The #pragma extern_model directive has the following syntax:
|
#pragma extern_model model_spec [attr[,attr]...] |
model_spec is one of the following:
common_block
relaxed_refdef
strict_refdef "name"
strict_refdef (No attr specifications allowed)
globalvalue (No attr specifications allowed)
[attr[,attr]...] are optional psect attribute specifications chosen from the following (at most one from each line):
gbl lcl (Not allowed with relaxed_refdef )
shr noshr
wrt nowrt
pic nopic (Not meaningful for Alpha)
ovr con
rel abs
exe noexe
vec novec
For OpenVMS Alpha and Integrity systems: 0 byte 1 word 2 long 3 quad 4 octa 5 6 7 8 9 10 11 12 13 14 15 16 page
For OpenVMS VAX systems: 2 long 3 quad 4 octa 9 page
The last line of attributes are numeric alignment values. When a numeric alignment value is specified on a section, the section is given an alignment of two raised to that power.
On OpenVMS Alpha and Integrity systems, the strict_refdef "name" extern_model can also take the following psect attribute specifications:
Use of the natalgn attribute can cause a program to violate the Tru64 UNIX Calling Standard. The calling standard states that all global variables must be aligned on a quadword boundary. Therefore, variables declared in a natalgn section should only be referenced in the module that defines them. |
Table 2-1 lists the attributes that can be applied to program sections.
See the OpenVMS Linker Utility Manual for more complete information on each.
The default attributes are: noshr , rel , noexe , novec , nopic .
For strict_refdef , the default is con . For common_block and relaxed_refdef , the default is ovr .
The default for wrt / nowrt is determined by the first variable placed in the psect. If the variable has the const type qualifier (or the readonly modifier), the psect is set to nowrt . Otherwise, it is set to wrt .
Restrictions on Setting Psect Attributes
Be aware of the following restriction on setting psect attributes.
The #pragma extern_model directive does not set psect attributes for variables declared as tentative definitions in the relaxed_refdef model . A tentative definition is one that does not contain an initializer. For example, consider the following code:
#pragma extern_model relaxed_refdef long int a; int b = 6; #pragma extern_model common_block long int c; |
Psect A is given octaword alignment (the default) because a is a tentative definition. Psect B is correctly given longword alignment because it is initialized and is, therefore, not a tentative definition. Psect C is also given longword alignment because it is declared in an extern_model other than relaxed_refdef .
The psect attributes are normally used by system programmers who need to perform declarations normally done in macro. Most of these attributes are not needed in normal C programs. Also, notice that the setting of attributes is supported only through the #pragma mechanism, and not through the /EXTERN_MODEL command-line qualifier. |
The #pragma extern_prefix directive controls the compiler's synthesis of external names, which the linker uses to resolve external name requests. When you specify #pragma extern_prefix with a string argument, the compiler prepends the string to all external names produced by the declarations that follow the pragma specification.
This pragma is useful for creating libraries where the facility code can be attached to the external names in the library.
The syntax is as follows:
|
#pragma extern_prefix
|
"string"
Prepends the quoted string to external names in the declarations that follow the pragma specification.save
Saves the current pragma prefix string.restore
Restores the saved pragma prefix string.
The default external prefix, when none has been specified by a pragma, is the null string. The recommended use is as follows:
#pragma extern_prefix save
#pragma extern_prefix " prefix-to-prepend-to-external-names "
...some declarations and definitions ...
#pragma extern_prefix restore
When an extern_prefix is in effect and you are using #include to include header files, but do not want the extern_prefix to apply to extern declarations in the header files, use the following code sequence:
#pragma extern_prefix saveOtherwise, the external identifiers for definitions in the included files will be prepended with the external prefix.
#pragma extern_prefix ""
#include ...
#pragma extern_prefix restore
All external names prefixed with a nonnull string using #pragma extern_prefix are converted to uppercase letters regardless of the setting of the /NAMES qualifier.
The compiler treats #pragma extern_prefix independently of the /PREFIX_LIBRARY_ENTRIES qualifier. The /PREFIX_LIBRARY_ENTRIES qualifier affects only ANSI and C Run-Time Library (RTL) entries; the extern_prefix pragma affects external identifiers for any externally visible name.
The #pragma function directive specifies that calls to the specified functions will occur in the source code. You normally use this directive in conjunction with #pragma intrinsic , which affects specified functions that follow the pragma directive. The effect of #pragma intrinsic on a given function continues to the end of the source file or until a #pragma function directive occurs, specifying that function.
The #pragma function directive has the following syntax:
|
#pragma function (function1[,function2, ...]) #pragma function () |
You cannot specify this pragma with empty parentheses. To disable all intrinsic functions, specify the /OPTIMIZE=NOINTRINSICS qualifier on the command line.
The effect of each #pragma include_directory is as if its string argument (including the quotes) were appended to the list of places to search that is given its initial value by the /INCLUDE_DIRECTORY qualifier, except that an empty string is not permitted in the pragma form.
The #pragma include_directory directive has the following syntax:
|
#pragma include_directory <string-literal> |
This pragma is intended to ease DCL command-line length limitations when porting applications from POSIX-like environments built with makefiles containing long lists of -I options that specify directories to search for headers. Just as long lists of macro definitions specified by the /DEFINE qualifier can be converted to #define directives in a source file, long lists of places to search specified by the /INCLUDE_DIRECTORY qualifier can be converted to #pragma include_directory directives in a source file.
Note that the places to search, as described in the help text for the /INCLUDE_DIRECTORY qualifier, include the use of POSIX-style pathnames, for example "/usr/base" . This form can be very useful when compiling code that contains POSIX-style relative pathnames in #include directives. For example, #include <subdir/foo.h> can be combined with a place to search such as "/usr/base" to form "/usr/base/subdir/foo.h" , which will be translated to the filespec "USR:[BASE.SUBDIR]FOO.H"
This pragma can appear only in the main source file or in the first file specified on the /FIRST_INCLUDE qualifier. Also, it must appear before any #include directives.
The #pragma inline directive expands function calls inline. The function call is replaced with the function code itself.
The #pragma inline directive has the following syntax:
|
#pragma inline (id,...) #pragma noinline (id,...) |
If a function is named in an inline directive, calls to that function will be expanded as inline code, if possible.
If a function is named in a noinline directive, calls to that function will not be expanded as inline code.
If a function is named in both an inline and a noinline directive, an error message is issued.
For calls to functions named in neither an inline nor a noinline directive, C++ expands the function as inline code whenever appropriate as determined by a platform-specific algorithm.
The #pragma intrinsic directive specifies that calls to the specified functions are intrinsic. Intrinsic functions are functions in which the compiler generates optimize code in certain situations, possibly avoiding a function call.
The #pragma intrinsic directive has the following syntax:
|
#pragma intrinsic (function1[,function2, ...]) |
You can use this directive to make intrinsic the default form of functions that have intrinsic forms. The following functions have intrinsic forms:
abs fabs labs alloca |
You can use the #pragma function directive to override the #pragma intrinsic directive for specified functions.
The function must have a declaration visable at the time the compiler encounters the #pragma intrinsic directive. The compiler takes no action if the compiler does not recognize the specified function name as an intrinsic.
By default, the compiler for OpenVMS systems aligns structure members so that members are stored on the next boundary appropriate to the type of the member; that is, bytes are on the next byte boundary, words are on the next word boundary, and so on.
You can use the #pragma member_alignment directive to specify structure member alignment explicitly. For example, using #pragma member_alignment aligns a long member variable on the next longword boundary, and it aligns a short member variable on the next word boundary.
Using #pragma nomember_alignment causes the compiler to align structure members on the next byte boundary regardless of the type of the member. The only exception to this is for bit-field members.
If used, the nomember_alignment pragma remains in effect until the compiler encounters the member_alignment pragma.
To save and restore the current setting of the member_alignment pragma, you can use the member_alignment save and member_alignment restore pragmas.
To affect the member alignment of the entire module, use the /MEMBER_ALIGNMENT qualifier. For information about this qualifier, see Section 2.1.1.10.
The #pragma message directive controls the kinds of individual diagnostic messages or groups of messages that the compiler issues. Use this pragma to override any command-line options specified by the /WARNINGS qualifier, which affects the types of messages the compiler issues.
Default severities used by the compiler can be changed only if they are informationals, warnings, or discretionary errors. Attempts to change more severe severities are ignored. If a message severity has not been altered by the command line and is not currently being controlled by a pragma, the compiler checks to see whether the message severity should be changed because of the "quiet" state. If not, the message is issued using the default severity.
Error message severities start out with command-line severities applied to default compiler severities. Pragma message severities are then applied. In general, pragma severities override command-line severities, which override default severities. The single exception to this is that command-line options can always be used to downgrade messages. However, command-line qualifiers cannnot be used to raise the severity of messages currently controlled by pragmas.
The #pragma message directive has the following syntax:
|
#pragma message disable (message-list) #pragma message enable (message-list) #pragma message error (message-list) #pragma message fatal (message-list) #pragma message informational (message-list) #pragma message warning (message-list) #pragma message restore #pragma message save |
disable
Suppresses the compiler-issued messages specified in the message-list argument. The message-list argument can be any one of the following:
- A single message identifier
- The keyword ALL (all messages issued by the compiler)
- A single message identifier enclosed in parentheses
- A comma-separated list of message identifiers enclosed in parentheses
A message identifier is the name immediately following the message severity code letter. For example, consider the following message:
%CXX-W-MISSINGRETURN, Non-void function "name" does not contain a return statementThe message identifier is MISSINGRETURN. To prevent the compiler from issuing this message, use the following directive:
#pragma message disable MISSINGRETURNThe compiler lets you disable a discretionary message if its severity is warning (W), informational (I), or error (E) at the time the message is issued. If the message has severity of fatal (F), the compiler issues it regardless of instructions not to issue messages.
enable
Enables the compiler to issue the messages specified in the message-list argument.errors
Sets the severity of each message in the message list to Error.fatals
Sets the severity of each message in the message list to Fatal.informationals
Sets the severity of each message in the message list to Informational.warnings
Sets the severity of each message in the message list to Warning.restore
Restores the saved state of enabling or disabling compiler messages.save
Saves the current state of enabling or disabling compiler messages.
The save and restore options are useful primarily within header files. See Section 2.1.1.5.
#pragma message performs macro expansion so that you map Version 5.6 message tags to Version 6.0 tags:
...
#if __DECCXX_VER > 60000000
#define uninit used_before_set
#endif
#pragma message disable uninit
int main()
{
int i,j;
i=j;
}
#pragma message enable uninit
|
When you compile source files to create an object file, the compiler assigns the first of the file names specified in the compilation unit to the name of the object file. The compiler adds the .OBJ file extension to the object file. Internally, the OpenVMS system (the debugger and the librarian) recognizes the object module by the file name; the compiler also gives the module a version number of 1. For example, given the object file EXAMPLE.OBJ, the debugger recognizes the EXAMPLE object module.
To change the system-recognized module name and version number, use the #pragma module directive.
You can find the module name and the module version number listed in the compiler listing file and the linker load map.
The #pragma module directive is equivalent to the VAX C compatible #module directive.
The
#pragma module
directive has the following syntax:
#pragma module identifier identifier
#pragma module identifier string
The first parameter must be a valid identifier, which specifies the name of the module to be used by the linker. The second parameter specifies the optional identification that appears on the listing and in the object file. The second parameter must be a valid identifier of no more than 31 characters, or a character-string constant of no more than 31 characters.
The #pragma once preprocessor directive specifies that the header file is evaluated only once.
The #pragma once directive has the following format:
|
#pragma once |
The #pragma pack directive specifies the byte boundary for packing member's structures.
The #pragma pack directive has the following format:
|
#pragma pack [(n)] #pragma pack(push {, identifier} {, n}) #pragma pack(pop {, identifier} {, n}) |
n specifies the new alignment restriction in bytes as follows:
| 1 | Align to byte |
| 2 | Align to word |
| 4 | Align to longword |
| 8 | Align to quadword |
| 16 | Align to octaword |
A structure member is aligned to either the alignment specified by #pragma pack or the alignment determined by the size of the structure member, whichever is smaller. For example, a short variable in a structure gets byte-aligned if #pragma pack (1) is specified. If #pragma pack (2) , (4) , or (8) is specified, the short variable in the structure gets aligned to word.
If #pragma pack is not used, or if n is omitted, packing defaults to 1 for byte alignment.
With the push/pop syntax of this pragma, you can save and restore packing alignment values across program components. This allows you to combine components into a single translation unit even if they specify different packing alignments:
The push/pop syntax of pragma pack lets you write header files that ensure that packing values are the same before and after the header file is encountered. Consider the following example:
// File name: myinclude.h // #pragma pack( push, enter_myinclude ) // Your include-file code ... #pragma pack( pop, enter_myinclude ) // End of myinclude.h |
In this example, the current packing value is associated with the identifier enter_myinclude and pushed on entry to the header file. Your include code is processed. The #pragma pack at the end of the header file then removes all intervening packing values that might have occurred in the header file, as well as the packing value associated with enter_myinclude , thereby preserving the same packing value after the header file as before it.
This syntax also lets you include header files that might set packing alignments different from the ones set in your code. Consider the following example:
#pragma pack( push, before_myinclude ) #include <myinclude.h> #pragma pack( pop, before_myinclude ) |
In this example, your code is protected from any changes to the packing value that might occur in <myinclude.h> by saving the current packing alignment value, processing the include file (which may leave the packing alignment with an unknown setting), and restoring the original packing value.
The #pragma unroll preprocessor directive unrolls the for loop that follows it by the number of times specified in unroll_factor. The #pragma unroll directive must be followed by a for statement.
This directive has the following format:
|
#pragma unroll unroll_factor |
The unroll_factor is an integer constant in the range of 0 to 255. If a value of 0 is specified, the compiler ignores the directive and determines the number of times to unroll the loop in its normal way. A value of 1 prevents the loop from being unrolled. The directive applies only to the for loop that follows it, not to any subsequent for loops.
This directive performs operations similar to the save and restore options on #pragma message directive:
The compiler defines the following predefined macros and predefined names. For information on using predefined macros in header files in the common language environment, see Section 3.2.
Table 2-3 lists names with a defined value of 1.
| Name | Description |
|---|---|
| __cplusplus 1 | Language identification name. |
| __DECCXX | Language identification name. |
| __VMS | System identification |
| __vms | System identification |
The compiler predefines __VMS ; the C compiler predefines VMS and __VMS . Therefore, C++ programmers who plan to reuse code should check for __VMS .
On OpenVMS Alpha systems, the compiler supports the following predefined macro names.
The compiler predefines __32BITS when pointers and data of type long are 32 bits on Alpha platforms.
On both UNIX and OpenVMS operating systems, programmers should use the predefined macro __alpha for code that is intended to be portable from one system to the other.
On OpenVMS I64 systems, the compiler supports the following predefined macro names:
Predefined macros (with the exception of vms_version , VMS_VERSION , __vms_version , __VMS_VERSION , and __INITIAL_POINTER_SIZE ) are defined as 1 or 0, depending on the system (VAX or Alpha processor), the compiler defaults, and the qualifiers used. For example, if you compiled using G_FLOAT format, __D_FLOAT and __IEEE_FLOAT (Alpha processors only) are predefined to be 0, and __G_FLOAT is predefined as if the following were included before every compilation unit:
#define __G_FLOAT 1 |
These macros can assist in writing code that executes conditionally. They can be used in #elif , #if , #ifdef , and #ifndef directives to separate portable and nonportable code in a C++ program. The vms_version , VMS_VERSION , __vms_version , and __VMS_VERSION macros are defined with the value of the OpenVMS version on which you are running (for example, Version 6.0).
C++ automatically defines the following macros pertaining to the format of floating-point variables. You can use them to identify the format with which you are compiling your program.
__D_FLOAT
__G_FLOAT
__IEEE_FLOAT
_IEEE_FP
__X_FLOAT
The value of __X_FLOAT can be 0 or 1 depending on the floating point mode in effect. You can use the /FLOAT qualifier to change the mode.
Table 2-6 lists predefined version string and version number macros.
For example, the defined value of __VMS_VERSION on OpenVMS Version 6.1 is character string V6.1 .
You can use __DECCXX_VER to test that the current compiler version is newer than a particular version and __VMS_VER to test that the current OpenVMS Version is newer than a particular version. Newer versions of the compiler and the OpenVMS operating system always have larger values for these macros. If for any reason the version cannot be analyzed by the compiler, then the corresponding predefined macro is defined but has the value of 0. Releases of the compiler prior to Version 5.0 do not define these macros, so you can distinguish earlier compiler versions by checking to determine if the __DECCXX_VER macro is defined.
The following example tests for C++ 5.1 or higher:
#ifdef __DECCXX_VER
#if __DECCXX_VER >= 50100000
/ *Code */
#endif
#endif
|
The following tests for OpenVMS Version 6.2 or higher:
#ifdef __VMS_VER
#if __VMS_VER >= 60200000
/* code */
#endif
#endif
|
Table 2-7 shows the macro names for the listed command-line options.
The only translation limits imposed in the compiler are as follows:
| Limit | Meaning |
|---|---|
| 32,767 | Bytes in the representation of a string literal. This limit does not apply to string literals formed by concatenation. |
| 8192 | Characters in an internal identifier or macro name. |
| 8192 | Characters in a logical name. |
| 8192 | Characters in a physical source line, on OpenVMS Alpha systems. |
| 1012 | Bytes in any one function argument. |
| 512 | Characters in a physical source line, on OpenVMS VAX systems. |
| 255 | Arguments in a function call. 1 |
| 255 | Parameters in a function definition. 1 |
| 127 | Characters in a qualified identifier in the debugger. |
| 31 | Significant characters in an external identifier with "C" linkage. A warning is issued if such an identifier is truncated. |
The numerical limits, as defined in the header files <limits.h> and <float.h> are as follows:
Numerical limits not described in this list are defined in The Annotated C++ Reference Manual.
The compiler passes arrays, functions, and class objects with a constructor or destructor by reference. All other objects are passed by value.
If a class has a constructor or a destructor, it is not passed by value. In this case, the compiler calls a copy constructor to copy the object to a temporary location, and passes the address of that location to the called function.
If the return value of a function is a class that has defined a constructor or destructor or is greater than 64 bits, storage is allocated by the caller and the address to this storage is passed in the first parameter to the called function. The called function uses the storage provided to construct the return value.
This section describes the extensions and implementation-specific features of the compiler on OpenVMS systems.
In the compiler, the dollar sign ($) is a valid character in an identifier.
For each external function with C++ linkage, the compiler decorates the function name with a representation of the function's type.
The compiler uses the external name encoding scheme described in §7.2.1c of The Annotated C++ Reference Manual.
For the basic types, the external name encoding scheme is exactly the same as that described in The Annotated C++ Reference Manual, as follows:
| Type | Encoding |
|---|---|
| void | v |
| char | c |
| short | s |
| int | i |
| long | l |
| float | f |
| double | d |
| long double | r |
| ... | e |
| bool | jb |
| wchar_t | jw |
Class names are encoded as described in The Annotated C++ Reference Manual, except that the DEC C++ compiler uses the lowercase q instead of uppercase Q , and denotes the qualifier count as a decimal number followed by an underscore, as follows:
| Class | Notation | Encoding |
|---|---|---|
| simple | Complex | 7Complex |
| qualified | X::YY | q2_1x2yy |
Type modifiers are encoded as follows:
| Modifier | Encoding |
|---|---|
| const | k |
| signed | g |
| volatile | w |
| unsigned | u |
| __unaligned | b |
Type declarators are encoded as follows:
| Type | Notation | Encoding |
|---|---|---|
| array | [10] | a10_ |
| function | () | x |
| pointer | * | p |
| pointer to member | S::* | m1S |
| reference | & | n |
| unnamed enumeration type | h |
On OpenVMS Alpha systems, the compiler also supports the following data types:
| Type | Encoding |
|---|---|
| __int16 | ji4 |
| __int32 | ji5 |
| __int64 | ji6 |
| __f_float | jf |
| __g_float | jg |
| __s_float | js |
| __t_float | jt |
On OpenVMS systems, if an identifier for a function name with C++ linkage exceeds 31 characters, the name is modified as follows:
For information on how to view the demangled form of these names, see Section 1.6.
Nonlocal static objects are initialized in declaration order within a compilation unit and in link order across compilation units. On OpenVMS systems, the compiler uses the lib$initialize mechanism to initialize nonlocal static objects.
When demoting an integer to a signed integer, if the value is too large to be represented the result is truncated and the high-order bits are discarded.
Conversions between signed and unsigned integers of the same size involve no representation change.
When converting an integer to a floating-point number that cannot exactly represent the original value, the compiler rounds off the result of the conversion to the nearest value that can be represented exactly.
When the result of converting a floating-point number to an integer or other floating-point number at compile time cannot be represented, the compiler issues a diagnostic message.
When converting an integral number or a double floating-point number to a floating-point number that cannot exactly represent the original value, rounds off the result to the nearest value of type float .
When demoting a double value to float , if the converted value is within range but cannot exactly represent the original value, the compiler rounds off the result to the nearest representable float value.
the compiler performs similar rounding for demotions from long double to double or float .
In C++, the expression T() (where T is a simple type specifier) creates an rvalue of the specified type, whose value is determined by default initialization. According to the The C++ Programming Language, 3rd Edition, the behavior is undefined if the type is not a class with a constructor, but the ANSI/ISO International Standard removes this restriction. With this change you can now write:
int i=int(); // i must be initialized to 0
|
The type of the sizeof operator is size_t . In the header file, stddef.h , the compiler defines this type as unsigned int , which is the type of the integer that holds the maximum size of an array.
A pointer takes up the same amount of memory storage as objects of type int or long (or their unsigned equivalents). Therefore, a pointer can convert to any of these types and back again without changing its value. No scaling occurs and the representation of the value is unchanged.
Conversions to and from a shorter integer and a pointer are similar to conversions to and from a shorter integer and unsigned long . If the shorter integer type was signed, conversion fills the high-order bits of the pointer with copies of the sign bit.
The semantics of the division (/) and remainder (%) operator are as follows:
In the following cases of undefined behavior detected at compile time, the compiler issues a warning:
Integer overflow
Division by 0
Remainder by 0
You can subtract pointers to members of the same array. The result is the number of elements between the two array members, and is of type ptrdiff_t . In the header file stddef.h , the compiler defines this type as int .
The expression E1 >> E2 shifts E1 to the right E2 positions. If E1 has a signed type, the compiler fills the vacated high-order bits of the shifted value E1 with a copy of E1 's sign bit (arithmetic shift).
When comparing two pointers to members, the compiler guarantees equality if either of the following conditions hold:
When comparing two pointers to members, the compiler guarantees inequality if either of the following conditions hold:
When created by different address expressions, two pointers to members may compare either as equal or as unequal if they produce the same member when applied to the same object.
For variables that are modifiable in ways unknown to the compiler, use the volatile type specifier. Declaring an object to be volatile means that every reference to the object in the source code results in a reference to memory in the object code.
In the compiler, asm declarations produce a compile-time error. As an alternative to asm, you can use built-in functions. See Appendix C for more information.
Specifying linkage other than "C++" or "C" generates a compile-time error.
In object files, the compiler decorates with type information the names of functions with C++ linkage. This permits overloading and provides rudimentary type checking across compilation units. The type-encoding algorithm used is similar to that given in §7.2.1c of The Annotated C++ Reference Manual (see Section 2.2.1.1).
The alignment requirements and sizes of structure components affect the structure's alignment and size. A structure can begin on any byte boundary and occupy any integral number of bytes.
Structure alignment is controlled by the /MEMBER_ALIGNMENT command-line qualifier or by using the #pragma member_alignment preprocessor directive. If /MEMBER_ALIGNMENT is specified, or implied by default, the maximum alignment required by any member within the structure determines the structure's alignment. When the structure or union is a member of an array, padding is added to ensure that the size of a record, in bytes, is a multiple of its alignment.
Components of a structure are laid out in memory in the order in which they are declared. The first component has the same address as the entire structure. Padding is inserted between components to satisfy alignment requirements of individual components.
If /NOMEMBER_ALIGNMENT is specified, each member of a structure appears at the next byte boundary.
If /MEMBER_ALIGNMENT is specified, or implied by default, the presence of bit-fields causes the alignment of the whole structure or union to be at least the same as that of the bit-field's base type.
For bit-fields (including zero-length bit-fields) not immediately declared following other bit-fields, their base type imposes the alignment requirements (less than that of type int ). Within the alignment unit (of the same size as the bit-field's base type), bit-fields are allocated from low order to high order. If a bit-field immediately follows another bit-field, the bits are packed into adjacent space in the same unit, if sufficient space remains; otherwise, padding is inserted at the end of the first bit-field and the second bit-field is put into the next unit.
Bit-fields of base type char must be smaller than 8 bits. Bit-fields of base type short must be smaller than 16 bits.
The layout of a class is unaffected by the presence of access specifiers.
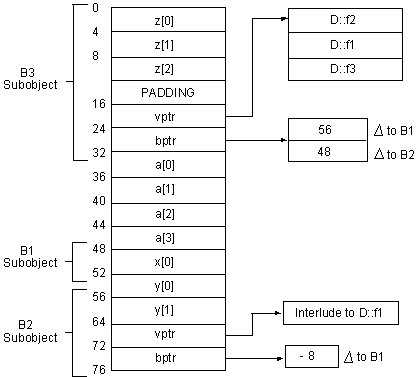
A class object that has one or more base classes contains instances of its base classes as subobjects. The offsets of nonvirtual base class subobjects are less than the offsets of any data members that are not part of base class subobjects.
The offsets of nonvirtual base classes increase in derivation order. The offset of the first nonvirtual base class subobject of any class is 0. For single inheritance, the address of a class object is always the same as the address of its base class subobject.
If a class has virtual functions, an object of that class contains a pointer to a virtual function table (VFPTR).
If a class has virtual base classes, an object of that class contains a pointer to a virtual base class table (VBPTR).
For a class with no base classes, the offset of a VFPTR or VBPTR is greater than the offset of any data members. Thus, the offset of the first data member of a class with no base classes is 0, which facilitates interoperability with other languages. If the leftmost base class of a subclass has a VFPTR, a VBPTR, or both, and is not virtual, the class and its base class share the table or tables.
The offsets of virtual base class subobjects are greater than the offset of any data member, and increase in the order of derivation of the virtual base classes. In increasing order, a class object contains the following:
Consider the following example:
class B1
{
int x[1];
};
class B2 : virtual B1
{
int y[2];
virtual int fl();
};
class B3 : virtual B2, virtual B1
{
int z[3];
virtual int f2();
};
class D : B3
{
int a[4];
virtual int f1(), f2(), f3();
};
|
Figure 2-1 shows the layout of an object of D class for this example.
The compiler allocates storage for virtual function tables (VTBLs) and base class tables (BTBLs) using the common block extern model. All references to VTBLs and BTBLs share a single copy. (The compiler specifies the local (LCL) PSECT attribute for these tables. Thus, one copy of each table exists for each program image file.) This means that you need not be concerned with the associations of these tables during compilation, and the compiler command switch +e supplied in other implementations is not needed for HP C++ for OpenVMS systems.
Within a class object, base class subobjects are allocated in derivation order; that is, immediate base classes are allocated in the order in which they appear in the class declaration.
Figure 2-1 Layout of an Object of D Class
Under the following conditions, the compiler creates temporary objects for class objects with constructors:
Variations in the compiler generation of such temporary objects can adversely affect their reliability in user programs. The compiler avoids introducing a temporary object whenever it discovers that the temporary object is not needed for accurate compilation. Therefore, you should modify or write your programs so as not to depend on side effects in the constructors or destructors of temporary objects.
Generally the compiler implements destruction of temporary objects at the end of statements. In certain situations, however, temporary objects are destroyed at the end of the expression; they do not persist to the end of the statement. Temporary objects do not persist to the end of statements in expressions that are:
Consider the following example:
struct A {
void print(int i);
A();
~A() { }
};
struct B {
A* find(int i);
B(int i);
B();
~B() { }
};
void f() {
B(8).find(6)->print(6);
(*(B(5).find(3))).print(3);
return;
}
|
In the first and second statements inside void f() , the compiler destroys the temporary object created in evaluating the expressions B(8) and B(5) after the call to A::print(int) .
If your program tries to initialize a nonconstant reference with a temporary object, the compiler generates a warning. For example:
struct A {
A(int);
};
void f(A& ar);
void g() {
f(5); // warning!!
}
|
When a static member is accessed through a member access operator, the expression on the left side of the dot (.) or right arrow (->) is not evaluated. In such cases, the compiler creates code that calls the static member function to handle the destruction of a class type temporary; the compiler does not create temporary destructor code. For example:
struct A {
~A();
static void sf();
};
struct B {
A operator ()() const;
};
void f () {
B bobj;
bobj().sf(); // If 'bobj()' is evaluated, a temporary of
// type 'A' is created.
}
|
The #include directive inserts external text into the macro stream delivered to the compiler. Programmers often use this directive to include global definitions for use with compiler functions and macros in the program stream.
On OpenVMS systems, the #include directive may be nested to a depth determined by the FILLM process quota and by virtual memory restrictions. The compiler imposes no inherent limitation on the nesting level of inclusion.
In C++ source programs, inclusion of both OpenVMS and most UNIX style file specifications is valid. For example, the following is a valid UNIX style file specification:
nodename!/device/directory/filename.dat.3 |
The exclamation point (!) separates the node name from the rest of the specification; slash characters (/) separate devices and directories; periods (.) separate file types and file versions. Because one character separates two segments of the file specification, ambiguity can occur.
The /INCLUDE_DIRECTORY=(pathname,...) qualifier provides an additional level of search for user-defined include files. Each pathname argument can be either a logical name or a legal UNIX style directory in a quoted string. The default is /NOINCLUDE_DIRECTORY.
The qualifier provides functionality similar to the -I option of the cxx command on Tru64 UNIX systems. This qualifier allows you to specify additional locations to search for files to include. Putting an empty string in the specification prevents the compiler from searching any of the locations it normally searches but directs it to search only in locations you identify explicitly on the command line with the /INCLUDE_DIRECTORY and /LIBRARY qualifiers (or by way of the specification of the primary source file, depending on the /NESTED_INCLUDE_DIRECTORY qualifier).
The basic order for searching depends on the form of the header name (after macro expansion), with additional aspects controlled by other command line qualifiers as well as the presence or absence of logical name definitions. The valid possibilities for names are as follows:
Unless otherwise defined, searching a location means that the compiler uses the string specifying the location as the default file specification in a call to an RMS system service (that is, a $SEARCH/$PARSE) with a primary file specification consisting of the name in the #include (without enclosing delimiters). The search terminates successfully as soon as a file can be opened for reading.
Specifying a null string in the /INCLUDE qualifier causes the compiler to do a non-standard search. This search path is as follows:
For standard searches, the search order is as follows:
SYS$COMMON:[CXX$LIB.INCLUDE.CXXL$ANSI_DEF]
SYS$COMMON:[CXX$LIB.INCLUDE.DECC$RTLDEF_HXX].HXX
SYS$COMMON:[CXX$LIB.INCLUDE.DECC$RTLDEF].H
SYS$COMMON:[CXX$LIB.INCLUDE.SYS$STARLET_C].H
SYS$COMMON:[CXX$LIB.INCLUDE.DECC$RTLDEF_HXX].HXX
SYS$COMMON:[CXX$LIB.INCLUDE.DECC$RTLDEF].H
SYS$COMMON:[CXX$LIB.INCLUDE.SYS$STARLET_C].H
SYS$COMMON:[CXX$LIB.INCLUDE.CXXL$ANSI_DEF]
| #include "foo.h" | Module name "FOO" |
| #include "foo" | Module name "FOO" |
| #include "foo" | Module name "FOO" |
| #include "foo.h" | Module name "FOO.H" |
| #include "foo" | Module name "FOO." |
| #include "foo" | Module name "FOO." |
Libraries specified on the command line with the /LIBRARY qualifier (all files, type stripped)
CXX$TEXT_LIBRARY (all files, type stripped)
DECC$RTLDEF (H files and unspecified files, type stripped)
SYS$STARLET_C (all files, type stripped)
CXXL$ANSI_DEF (unspecified files, type stripped)
Libraries specified on the command line with the /LIBRARY qualifier (all files, type optional)
CXX$TEXT_LIBRARY (all files, type optional)
CXXL$ANSI_DEF (all files, type required)
DECC$RTLDEF (H files and unspecified files, type stripped)
SYS$STARLET_C (all files, type stripped)
Example 1
#include "foo" |
- Look for "FOO."
- Look for "FOO"
Example 2
#include "foo.h" |
- Look for "FOO.H"
- Look for "FOO"
The C++ language allows programmers to give distinct functions the same name, and uses either overloading or class scope to differentiate the functions:
void f(int);
void f(int *);
class C {void f(int);};
class D {void f(int);};
|
Yet, linkers cannot interpret overloaded parameter types or classes, and they issue error messages if they find more than one definition of any external symbol. C++ compilers, including HP C++, solve this problem by assigning a unique mangled name (also called type safe linkage name) to every function. These unique mangled names allow the linker to tell the overloaded functions apart.
The compiler forms a mangled name, in part, by appending an encoding of the parameter types of the function to the function's name, and if the function is a member function, the function name is qualified by the names of the classes within which it is nested.
For example, for the function declarations at the beginning of this section, the compiler might generate the mangled names f__Xi , f__XPi , f__1CXi , and f__1DXi respectively. In these names, i means a parameter type was int , P means "pointer to", 1C means nested within class C , and 1D means nested within class D .
There is a flaw in the name mangling scheme used by the compiler that can cause problems in uncommon cases. The compiler fails to note in the encoding of an enum type in a mangled name whether the enum type was nested within a class. This can cause distinct overloaded functions to be assigned the same mangled name:
struct C1 {enum E {red, blue};};
struct C2 {enum E {red, blue};};
extern "C" int printf(const char *, ...);
void f(C1::E x) {printf("f(C1::E)\n");}
void f(C2::E x) {printf("f(C2::E)\n");}
int main()
{
f(C1::red);
f(C2::red);
return 1;
}
|
In the previous example, the two overloaded functions named f differ only in that one takes an argument of enum type C1::E and the other takes an argument of enum type C2::E . Since the compiler fails to include the names of the classes containing the enum type in the mangled name, both functions have mangled names that indicate the argument type is just E . This causes both functions to receive the same mangled name.
In some cases, the compiler detects this problem at compile-time and issues a message that both functions have the same type-safe linkage. In other cases, the compiler issues no message, but the linker complains about duplicate symbol definitions.
If you encounter such problems, you can recompile using the
/DISTINGUISH_NESTED_ENUMS qualifier (ALPHA ONLY). This causes the
compiler, when forming a mangled name, to include the name of class or
classes within which an enum is nested, thereby preventing different
functions from receiving the same the same mangled name.
Because the /DISTINGUISH_NESTED_ENUMS qualifier changes the external symbols the compiler produces, you can get undefined symbol messages from the linker if some modules are compiled with /DISTINGUISH_NESTED_ENUMS and some are compiled without it. Because of this, /DISTINGUISH_NESTED_ENUMS might make it difficult to link against old object files or libraries of code.
If you compile your code with
/DISTINGUISH_NESTED_ENUMS and try to link against a library that was
compiled without the /DISTINGUISH_NESTED_ENUMS qualifier, you receive
an undefined symbol message from the linker if you attempt to call a
function from the library that takes an argument of a nested enum type.
The mangled name of the function in the library will be different from
the mangled name your code is using to call the function.
Note that the /DISTINGUISH_NESTED_ENUMS qualifier has no meaning on I64 systems because it modifies the behavior of programs compiled with /MODEL=ARM, and that model is not supported on I64 systems.
A guiding declaration is a function declaration that matches a function template, does not introduce a function definition (implies an instantiation of the template body and not a explicit specialization), and is subject to different argument matching rules than those that apply to the template itself---therefore affecting overload resolution. Consider the following example:
template <class T> void f(T) {
printf("In template f\n");
}
void f(int);
int main() {
f(0); // invokes non-template f
f<>(0.0); // invokes template f
return 0;
}
void f(int) {
printf("In non-template f\n");
}
|
Because there is no concept of guiding declaration in the current version of the C++ International Standard, the function f in the example is not regarded as an instance of function template f . Furthermore, there are two functions named f that take an int parameter. A call of f(0) would invoke the former, while a call of f<>(0) would be required to invoke the latter.
The compiler supports use of alternative tokens:
/[no]alternative_tokens
Enable use of operator keywords and digraphs to generate tokens as follows:
Operator Keyword Token and && and_eq &= bitand & bitor | compl ~ not ! not_eq != or || or_eq |= xor ^ xor_eq ^=
Digraph Token :> ] <: [ %> } <% { %: #
The compiler emits type information for run-time type identification (RTTI) in the object module with the virtual function table, for classes that have virtual function tables.
You can specify the /[NO]RTTI qualifier to enable or disable support for RTTI (runtime type identification) features: dynamic_cast and typeid . Disabling runtime type identification can also save space in your object file because static information to describe polymorphic C++ types is not generated. The default is to enable runtime type information features and generate static information in the object file.
Specifying /NORTTI does not disable exception handling.
The type information for the class may include references to the type information for each base class and information on how to convert to each. The typeinfo references are mangled in the form __T__<class> .
The compiler supports the following message control options. The options apply only to warning and informational messages. The ident variable is obtained from the error message.
Indicated messages can specify one or more message identifiers ident or the message group name all .
The default qualifier, /WARNINGS, outputs all enabled informational and warning messages. The /NOWARNINGS qualifier suppresses both the informational and the warning messages.
Message options are processed and take effect in the following order:
/WARNINGS=NOWARNINGS
Disable all warnings./WARNINGS=INFORMATIONALS
Enable informationals.Although /WARNINGS=INFORMATIONALS enables most informationals, we recommend using /WARNINGS=ENABLE=ALL instead.
/WARNINGS=INFORMATIONALS=ALL or (ident,...)
Set the severity of the specified messages to Informational. You can specify ALL, which applies only to discretionary messages. The ALL option also enables informationals that are disabled by default.With Version 7.1 of the C++ compiler, /WARNINGS=INFORMATIONALS=<tag> no longer enables all other informational messages.
/WARNINGS=WARNINGS=ALL or (ident,...)
Set the severity of the specified messages to Warning. You can specify ALL, which applies only to discretionary messages./WARNINGS=[NO]ANSI_ERRORS
Issue error messages for all ANSI violations when in STRICT_ANSI mode. The default is /WARNINGS=NOANSI_ERRORS./WARNINGS=ERRORS=ALL or (ident,...)
Set the severity of the specified messages to Error. You can specify ALL, which applies only to discretionary messages./WARNINGS=ENABLE=ALL or (ident,...)
Enable all compiler messages, including informational-level messages. Enable specific messages that normally would not be issued when using /QUIET. You can also use this option to enable messages disabled with /WARNINGS=DISABLE./WARNINGS=DISABLE=ALL or (ident,...)
Disable message. This can be used for any nonerror message./QUIET
Be more like Version 5.n error reporting. Fewer messages are issued using this option.This is the default in arm mode (/STANDARD=ARM). All other modes default to /NOQUIET.
You can use the /WARNINGS=ENABLE option with this option to enable specific messages normally disabled using /QUIET.
The compiler supports the following message information option, which is disabled by default.
/WARNINGS=[NO]TAGS
Display a descriptive tag with each message. "D" indicates that the message is discretionary and that its severity can be changed from the command line or with a pragma. The tag displayed can be used as the ident variable in the /WARNINGS options.Example:
$ cxx/warnings=tags t.cxx f() {} ^ %CXX-W-NOSIMPINT, omission of explicit type is nonstandard ("int" assumed) (D:nosimpint) at line number 1 in file CXX$:[SMITH]STD.CXX;1 f() {} .....^ %CXX-W-MISSINGRETURN, non-void function "f" (declared at line 1) should return a value (D:missingreturn) at line number 1 in file CXX$:[SMITH]STD.CXX;1 $ cxx /warnings=(notags,disable=nosimpint) t.cxx f() {} .....^ %CXX-W-MISSINGRETURN, non-void function "f" (declared at line 1) should return a value at line number 1 in file CXX$:[SMITH]STD.CXX;1
Also see the #pragma message preprocessor directive.
| Previous | Next | Contents | Index |
|
|||||||||||