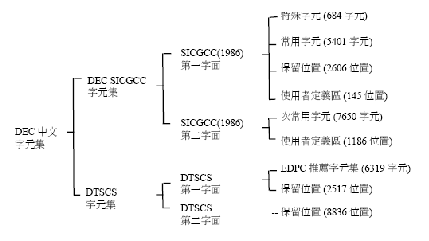
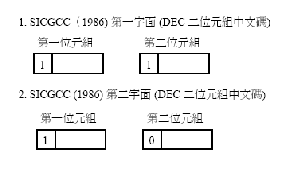
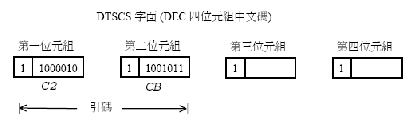
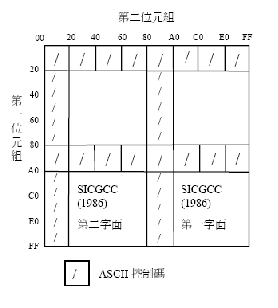
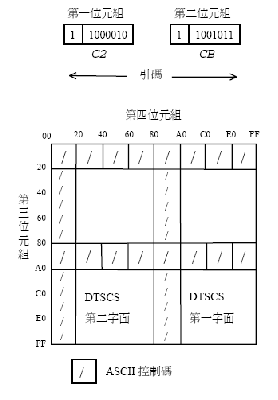
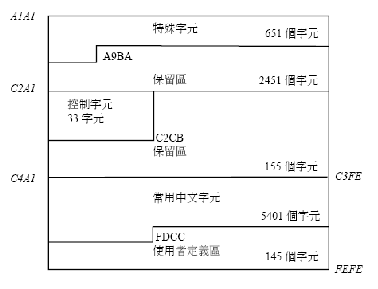
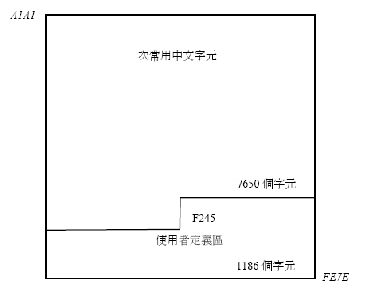
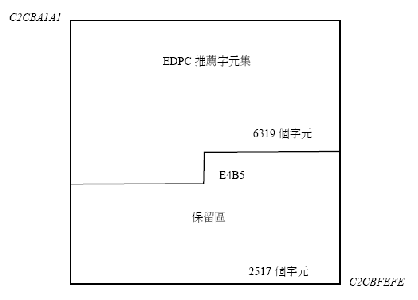
B.1.1 應用可呼叫HSYSHR常式的範例
$ TYPE HSY$EXAMPLE:SAMPLE_HSYSHR.C
/* SAMPLE_HSYSHR.C
----------------
This is a C language example to demostrate the ability of the HSY$ facility of the OpenVMS
Run Time Library, HSYSHR. The program accepts an input file from the command line and
ormats the text within it in the following ways:
- Left margin = 0, Right margin = 40
- Convert all half form ASCII characters to their full forms.
- Remove leading and trailing blanks of each input line.
- Remove all embedded controls or space characters.
*/
#include <stdlib.h>
#include <stdio.h>
typedef unsigned char mstr; /* Local language string type */
typedef unsigned char *mstr_p; /* Pointer type to local */
/* language string */
typedef unsigned long mchar; /* Multi-byte character type */
#define INPUT_STR_LEN 128 /* Max length of input line */
#define OUTPUT_STR_LEN 128*2 /* Max length of output line */
#define MARGIN 40 /* Width of output text */
#define EMPTY 0 /* Zero */
#define SUCCESS 1 /* Successful call */
#define FAILURE 0 /* Unsuccessful call */
#define SPACE 0x00000020 /* Space character in HSYSHR */
/* format */
extern HSY$IS_VALID(), /* External HSY$ routines to */
HSY$CH_RNEXT(),HSY$CH_WNEXT(), /* used */
HSY$CH_SIZE(), HSY$CH_NCHAR(), HSY$CH_NBYTE(),
HSY$CH_TRIM(), HSY$SKPC(), HSY$TRA_ROM_FULL();
FILE *fdin, /* Input file descriptor */
*fdout; /* Output file descriptor */
int line_length; /* Remaining number of bytes */
/* of the current output line */
/* WRITE_TEXT
----------
This routine will accept an input buffer and its length in number of characters,
and write the string to the output file at 40 bytes per line. A blank line is
printed if the input buffer is null.
*/
int write_text(buffer, buf_len)
mstr_p buffer; /* Output buffer */
int buf_len; /* Buffer length in number */
/* of characters */
{
int char_size, /* Character size in bytes */
offset, /* Offset of input buffer */
i, j; /* Loop index */
mchar curr_char; /* Current multi-byte char */
mstr_p buf_ptr; /* Pointer to buffer */
if (buffer == NULL){ /* Empty line, next paragraph */
fprintf(fdout, "\n");
if (line_length != EMPTY) fprintf(fdout, "\n");
line_length = MARGIN;
return SUCCESS;
}
offset=EMPTY;buf_ptr = buffer; /* Initialize for the loop */
for (i= EMPTY; i < buf_len; i++) {
curr_char = HSY$CH_RNEXT(&buf_ptr);
/*Read next character and */
/* advance string pointer. */
char_size = HSY$CH_SIZE(curr_char);
/* Calculate the size of the */
if (line_length < char_size) {
/* character in bytes. */
line_length = MARGIN;
fprintf(fdout,"\n");
}
for (j=0; j < char_size; j++){
/* Put a multi-byte character */
fputc(buffer[offset++], fdout);
/* to the output file */
}
line_length -= char_size;
}
return SUCCESS;}
/* TEXT_FORMAT
-----------
This routine accepts an input string, removes its trailing and
leading blanks, converts all half form ASCII to their full
forms and places the converted string into a buffer which
will be written to the output file.
*/
int text_format(in_str)
mstr in_str[]; /* Zero terminated input */
/* string */
{
mstr buffer[OUTPUT_STR_LEN];
/* Output buffer */
mstr_p str_ptr, /* Pointer to source string */
dst_ptr; /* Pointer to dest. string */
mchar curr_char; /* Current multi-byte char */
int status, /* Return status */
pos, /* Position of trimmed string */
charsofar, /* Character processed so far */
noofchar, /* No. of characters and */
noofbytes; /* bytes in a string. */
if (!(str_ptr = HSY$SKPC(SPACE, in_str, strlen(in_str)-1)))
return write_text(NULL,EMPTY);
/* Skip leading blanks */
pos = HSY$TRIM(str_ptr, strlen(str_ptr)-1);
/* Trim trailing blanks */
if (!(HSY$TRA_ROM_FULL(str_ptr, pos, buffer, OUTPUT_STR_LEN,
&noofbytes)))
return FAILURE; /* Convert to full form */
noofchar = HSY$CH_NCHAR(buffer,noofbytes);
/* Calculate the length of */
/* string in characters. */
charsofar = EMPTY;
str_ptr = dst_ptr = buffer; /* Initialize for the loop */
while (noofchar--) {
curr_char = HSY$CH_RNEXT(&str_ptr);
/* Read the next character */
if (HSY$IS_VALID (curr_char)) {
/* Test for valid multi-byte */
HSY$CH_WNEXT(curr_char, &dst_ptr);
/* character and write to the */
charsofar ++ ; /* destination. */
}
}
write_text(buffer, charsofar); /* Write the text out to file */
return SUCCESS;
}
/* MAIN
----
This main program checks for a valid command line, open all
necessary files and calls the appropriate routine to process
the input data.
*/
main(argc,argv)
int argc;
unsigned char *argv[];
{
mstr in_str[INPUT_STR_LEN]; /* Input line */
int status;
if (argc != 3) {
printf("Usage: $ FORMAT <input_file> <output_file>\n");
exit(EXIT_FAILURE);
}
if ((fdin = fopen(argv[1], "r")) == NULL) {
printf("Error: Cannot open input file %s.\n", argv[1]);
exit(EXIT_FAILURE);
}
if ((fdout = fopen(argv[2],"w")) == NULL) {
printf("Error: Cannot open output file %s.\n", argv[2]);
exit(EXIT_FAILURE);
}
line_length = MARGIN;
while (fgets(in_str, INPUT_STR_LEN, fdin) != NULL)
if (!(text_format(in_str))) {
printf("Information: Processing error.\n");
break;
}
printf("Information: Finish Processing.\n");
fclose (fdin);
fclose (fdout);
exit(EXIT_SUCCESS);
}