| Previous | Contents | Index |
If the RTR ACP fails, behavior depends on the availability of standby servers.
RTR ACP Fails: Standby Servers Available
If the RTR ACP fails, all the active servers on that node have their RTR channels closed and any transaction in progress is rejected. RTR tries to fail over to the standby server, if any exists. If no standby servers have been configured, the transaction is aborted. Take the case of the configuration shown in Figure 2-3. Assume that the ACP has crashed on node N1. RTR on the surviving node recognizes this and attempts to fail over to P1S. As before, a journal scan of the journal on N1 must be done before changing to active state. Since the ACP on N1 is gone, it cannot be used for the journal scan; the ACP on N2 must do the journal scan on its own. In this case, the behavior is different for recognized and unrecognized clusters.
Because RTR recognizes that it is in a cluster configuration, it will wait for the cluster management to fail over the disks to N2. This failover process depends on whether it is a recognized or unrecognized cluster.
Journal Scan: Recognized Clusters
Recognized clusters allow N2 to access D.1 immediately and recover from
the journal N1.J0 . This is because both N1 and N2 have equal access to
the disk. Because the RTR ACP has gone down with the node, the DLM
locks on N1.J0 are also released making it free for use by N2. In this
cluster configuration, the RTR failover occurs immediately when the
active node goes down.
Because this is a cluster configuration, both nodes N1 and N2 can access the journal N1.J0 on D1. On recognized clusters, RTR can directly access N1.J0 and on unrecognized clusters, RTR can access N1.J0 through the host node N1. Since the RTR ACP on N1 has failed, it has released locks on N1.J0 making it free for the ACP on N2 to access. There is no failover time as the failure of the ACP on N1 is detected by RTR immediately.
If a cluster transition causes D1 and D3 to be hosted on N2, this initiates the worst-case scenario, because the active server for P1A is running on N1 but will be accessing the database partition P1 through host N2. Similarly, the RTR ACP on N1 will also access its journal N1.J0 through host N2. Note that this inefficiency is not present in recognized clusters. Thus, wherever host-based clustering is used, any re-hosting of disks should result in a matching change in the active/standby configuration of the RTR servers as well. RTR events or failover scripts can be used to achieve this.
Journal Scan: Unrecognized Clusters
Failover is more complicated in unrecognized clusters. When N1 goes
down, the host for D1 also disappears. The cluster software must then
select a new host, N2 in this case. It then proceeds to re-host D1 on
N2. Once this has happened, D1 will become visible from N2. RTR
failover time depends on cluster failover time.
Since the unrecognized clusters are all host-based, there will be a failover time required to re-host D1 on N2. RTR will not wait for this re-hosting. It performs a journal scan for N1.J0, does not find it and so does not do any transaction recovery. RTR simply moves into the active state and starts processing new transactions.
RTR treats unrecognized clusters as though they are not clusters. That is, RTR on the upcoming active server (N2) performs a journal scan. It searches among the disks accessible to it but does not specifically look for clustered disks. It also does not perform a journal scan on any NFS-mounted disks. If RTR on N2 can find the journal N1.J0, it performs a full recovery of any transactions sitting in this journal and then continues to process transactions. If it cannot find the journal (N1.J0), it just continues to process new transactions; it does not wait for journals to become available.
Behavior when an active node fails depends on whether a standby node is available.
Active Node Fails: Standby Nodes Available
In this scenario, the node on which the active RTR servers are running
fails. This causes the loss of a cluster node in addition to the RTR
ACP and RTR servers. So, in addition to RTR failover, there is also a
cluster failover. The RTR failover occurs as described above, with
first a journal scan, transactions in the journal recovered, and then
changing the standby server to active
(P1S -> P1A). As this also causes a cluster
failover, the effects vary according to cluster type.
A transactional shadow server handles the same transactions as the primary server, and maintains an identical copy of the database on the shadow. Both the primary and the shadow server receive every transaction for their key range or partition. If the primary server fails, the shadow server continues to operate and completes the transaction. This helps to protect transactions against site failure.
To prevent database loss at an entire site, you can use either transactional shadowing or standby servers. For example, for the highest level of fault tolerance, the configuration should contain two shadowed databases, each supported by a remote journal, with concurrent servers and partitions.
With such a configuration, you can use RTR shadowing to capture client transactions at two different physically separated sites. If one site becomes unavailable, the second site can then continue to record and process the transactions. This feature protects against site disaster.
To understand and plan for smooth inter-node communication you must understand quorum.
Quorum is used by RTR to ensure facility consistency and deal with potential network partitioning. A facility achieves quorum if the right number of routers and backends in a facility (referred to in RTR as the quorum threshold), usually a majority, are active and connected.
In an OpenVMS cluster, for example, nodes communicate with each other to ensure that they have quorum, which is used to determine the state of the cluster; for cluster nodes to achieve quorum, a majority of possible voting member nodes must be available. In an OpenVMS cluster, quorum is node based. In the RTR environment, quorum is role based and facility specific. Nodes/roles in a facility that has quorum are quorate; a node that cannot participate in transactions becomes inquorate.
RTR computes a quorum threshold based on the distributed view of connected roles. The minimum value can be two. Thus a minimum of one router and one backend is required to achieve quorum. If the computed value of quorum is less than two, quorum cannot be achieved. In exceptional circumstances, the system manager can reset the quorum threshold below its computed value to continue operations, even when only a minimum number of nodes, less than a majority, is available. Note, however, that RTR uses other heuristics, not based on simple computation of available roles, to determine quorum viability. For instance, if a missing (but configured) backend's journal is accessible, that journal is used to count for the missing backend.
A facility without quorum cannot complete transactions. Only a facility that has quorum, whose nodes/roles are quorate can complete transactions. A node/role that becomes inquorate cannot participate in transactions.
Your facility definition also has an impact on the quorum negotiation undertaken for each transaction. To ensure that your configuration can survive a variety of failure scenarios (for example, loss of one or several nodes), you may need to define a node that does not process transactions. The sole use of this node in your RTR facility is to make quorum negotiation possible, even when you are left with only two nodes in your configuration. This quorum node prevents a network partition from occurring, which could cause major update synchronization problems.
Note that executing the CREATE FACILITY command or its programmatic equivalent does not immediately establish all links in the facility, which can take some time and depends on your physical configuration. Therefore, do not use a design that relies on all links being established immediately.
Quorum is used to:
If your configuration is reduced to two server nodes out of a larger population, or if you are limited to two servers only, you may need to make some adjustments in how to manage quorum to ensure that transactions are processed. Use a quorum node as a tie breaker to ensure achieving quorum.
Figure 2-4 Configuration with Quorum Node
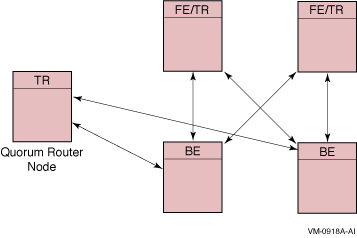
For example, with a five-node configuration (Figure 2-4) in which one node acts as a quorum node, processing still continues even if one entire site fails (only two nodes left). When an RTR configuration is reduced to two nodes, the system manager can manually override the calculated quorum threshold. For details on this practice, see the Reliable Transaction Router System Manager's Manual.
Frequently with RTR, you will partition your database.
Partitioning your database means dividing your database into smaller databases to distribute the smaller databases across several disk drives. The advantage of partitioning is improved performance because records on different disk drives can be updated independently - resource contention for the data on a single disk drive is reduced. With RTR, you can design your application to access data records based on specific key ranges. When you place the data for those key ranges on different disk drives, you have partitioned your database. How you establish the partitioning of your database depends on the database and operating systems you are using. To determine how to partition your database, see the documentation for your database system.
In some applications that use RTR with shadowing, the implications of transaction serialization need to be considered.
Given a series of transactions, numbered 1 through 6, where odd-numbered transactions are processed on Frontend A (FE A) and even-numbered transactions are processed on Frontend B (FE B), RTR ensures that transactions are passed to the database engine on the shadow in the same order as presented to the primary. This is serialization. For example, the following table represents the processing order of transactions on the frontends.
| Transaction Ordering on Frontends | |
|---|---|
| FE A | FE B |
| 1 | 2 |
| 3 | 4 |
| 5 | 6 |
The order in which transactions are committed on the backends, however, may not be the same as their initial presentation. For example, the order in which transactions are committed on the primary server may be 2,1,4,3,5,6, as shown in the following table.
| Transaction Ordering on Backend - Primary BE A | |
|---|---|
| 2 | |
| 1 | |
| 4 | |
| 3 | |
| 5 | |
| 6 | |
The secondary shadowed database needs to commit these transactions in the same order. RTR ensures that this happens, transparently to the application.
However, if the application cannot take advantage of partitioning, there can be situations where delays occur while the application waits, say, for transaction 2 to be committed on the secondary. The best way to minimize this type of serialization delay is to use a partitioned database. However, because transaction serialization is not guaranteed across partitions, to achieve strict serialization where every transaction accepts in the same order on the primary and on the shadow, the application must use a single partition.
Not every application requires strict serialization, but some do. For example, if you are moving $20, say, from your savings to your checking account before withdrawing $20 from your checking account, you will want to be sure that the $20 is first moved from savings to checking before making your withdrawal. Otherwise you will not be able to complete the withdrawal, or perhaps, depending upon the policies of your bank, you may get a surcharge for withdrawing beyond your account balance. Or a banking application may require that checks drawn be debited first on a given day, before deposits. These represent dependent transactions, where you design the application to execute the transactions in a specific order.
If your application deals only with independent transactions, however, serialization will probably not be important. For example, an application that tracks payment of bills for a company would consider that the bill for each customer is independent of the bill for any other customer. The bill-tracking application could record bill payments received in any order. These would be independent transactions. An application that can ignore serialization will be simpler than one that must include logic to handle serialization and make corrections to transactions after a server failure.
In addition to dependent transactions that can make serialization more complex, if the application uses batch processing or concurrent servers, ensuring strict serialization may be difficult.
In a transactional shadow configuration using the same facility, the same partition, and the same key-range, RTR ensures that data in both databases are correctly serialized, provided that the application follows a few rules. For a description of these rules, see Chapter 3, later in this document. The shadow application runs on the backends, processes transactions based on the business and database logic required, and hands off transactions to the database engine that updates the database. The application can take advantage of multiple CPUs on the backends.
Transactions are serialized by accept committing them in chronological order within a partition. Do not share data records between partitions because they cannot be serialized correctly on the shadow site.
Dependent transactions operate on the same record and must be executed in the same order on the primary and the secondary servers. Independent transactions do not update the same data records and can be processed in any order.
RTR relies on database locking during its accept phase to determine if transactions executing on concurrent servers within a partition are dependent. A server that holds a lock on a data record during its vote call (AcceptTransaction for the C++ API or rtr_accept_tx for the C API) blocks other servers from updating the same record. Therefore only independent transactions can vote at the same time.
RTR tracks time in cycles using windows; a vote window is the time between the close of one commit cycle and the start of the next commit cycle.
RTR commit grouping enables independent transactions to be scheduled together on the shadow secondary. A group of transactions that execute an AcceptTransaction (or rtr_accept_tx call for the C API) call within a vote window form an RTR commit group, identified by a unique commit sequence number (CSN). For example, given a router (TR), backend (BE), and database (DB), each transaction sent by the backend to the database server is represented by a vote. When the database receives each vote, it locks the database and responds as voted. The backend responds to the router in a time interval called the vote window, during which all votes that have locked the database receive the same commit sequence number. This is illustrated in Figure 2-5.
Figure 2-5 Commit Sequence Number
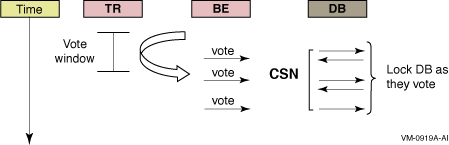
To improve performance on the secondary server, RTR lets this commit group of transactions execute in any order on the secondary.
RTR reuses the current CSN if it determines that the current transaction is independent of previous transactions. This way, transactions can be sent to the shadow in a bunch.
In a little more detail, RTR assumes that transactions within the vote window are independent. For example, given a router and a backend processing transactions, as shown in Figure 2-6 for the C++ API, transactions processed between execution of AcceptTransaction and the final Receive that occurs after the SQL commit or rollback will have the same commit sequence number.
Figure 2-6 CSN Vote Window for the C++ API
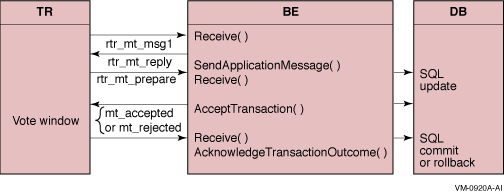
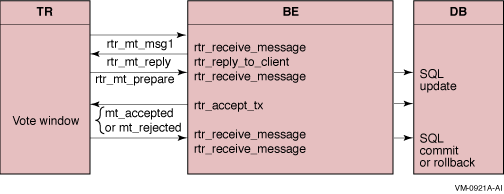
Figure 2-7 illustrates the vote window for the C API. Transactions processed between execution of the rtr_accept_tx call and the final rtr_receive_message call that occurs after the SQL commit or rollback will have the same commit sequence number.
Figure 2-7 CSN Vote Window for the C API
Not all database managers require locking before the SQL commit operation. For example, some insert calls create a record only during the commit operation. For such calls, the application must ensure that the table or some token is locked so that other transactions are not incorrectly placed by RTR in the same commit group.
All database systems do locking at some level, at the database, file, page, record, field, or token level, depending on the database software. The application designer must determine the capabilities of whatever database software the application will interface with, and consider these in developing the application. For full use of RTR, the database your application works with must, at minimum, be capable of being locked at the record level.
When a transaction is specified as being independent (using the
SetIndependentTransaction parameter set to true in the
AcceptTransaction method (C++ API) or with the INDEPENDENT flag (C
API)), the current commit sequence number is assigned to the
independent transaction. Thus the transaction can be scheduled
simultaneously with other transactions having the same CSN, but only
after all transactions with lower CSNs have been processed.
RTR tracks time in cycles using windows; a vote window is the time between the close of one commit cycle and the start of the next commit cycle. For example, independent transactions include transactions such as zero-hour ledger posting (posting of interest on all accounts at midnight), and selling bets (assuming that the order in which bets are received has no bearing on their value).
RTR examines the vote sequence of transactions executing on the primary server, and determines dependencies between these transactions. The assumption is: if two or more transactions vote within a vote window, these transactions could be processed in any order and still produce the same result in the database. Such a group of transactions is considered independent of other transaction groups. Such groups of transactions that are mutually independent may still be dependent on an earlier group of independent transactions.
RTR tracks these groups through CSN ordering. A transaction belonging to a group with a higher CSN is considered to be dependent on all transactions in a group with a lower CSN. Because RTR infers CSNs based on run-time behavior of servers, there is scope for improvement if the application can provide hints regarding actual dependence. If the application knows that the order in which a transaction is committed within a range of other transactions is not significant, then using independent transactions is recommended. If an application does not use independent transactions, RTR determines the CSN grouping based on its observation of the timing of the vote.
To force RTR to provide a CSN boundary, the application must:
The CSN boundary is between the end of one CSN and the start of the next, as represented by the last transaction in one commit group and the first transaction in the subsequent commit group.
In practice, for the transaction to be voted on after its dependent transactions, it is enough for the dependent transaction to access a common database resource, so that the database manager can serialize the transaction correctly.
Dependent transactions do not automatically have a higher CSN. To ensure a higher CSN, the transaction also needs to access a record that is locked by a previous transaction. This will ensure that the dependent transaction does not vote in the same vote cycle as the transaction on which it is dependent. Similarly, transactions that are independent do not automatically all have the same CSN. In particular, for the C API, if they are separated by an independent transaction, that transaction creates a CSN boundary.
RTR commit grouping enables independent transactions to be scheduled together on the shadow secondary. Flags on rtr_accept_tx and rtr_reply_to_client enable an application to signal RTR that it is safe to schedule this transaction for execution on the secondary within the current commit sequence group. In a shadow environment, an application can obtain certain performance improvements by using independent transactions where suitable. With independent transactions, transactions in a commit group can be executed on the shadow server in a different order than on the primary. This reduces waiting times on the shadow server.
For example, transactions in a commit group can execute in the order A2, A1, A3 or the primary partition and in the order A1, A2, A3 on the shadow site. Of course independent transactions can only be used where transaction execution need not be strictly the same on both primary and shadow servers. Examples of code fragments for independent transactions are shown in the code samples appendices of this manual.
Some of your applications may rely on batch processing for periodic activity. Application facilities can be created with batch processing. (The process for creating batch jobs is operating-system specific, and is thus outside the scope of this document.) Be careful in your design when using batch transactions. For example, accepting data in batch from legacy systems can have an impact on application results or performance. If such batch transactions update the same database as online transactions, major database inconsistencies or long transaction processing delays can occur.
| Previous | Next | Contents | Index |