| Previous | Contents | Index |
While a server application is processing a transaction, and particularly before it "accepts" the transaction, it must ensure that all shared resources accessed by that transaction are locked. Failure to do so can cause unpredictable results in shadowing or recovery.
The rule is:
Lock shared resources while processing each transaction.
To ensure that your application deals with transactions correctly, its transactions must be:
For the atomic attribute, the result of a transaction is all or nothing, that is, either totally committed or totally rolled back. To ensure atomicity, do not use a data manager that cannot roll back its updates on request. All standard data managers or database management systems have the atomicity attribute. However, in some cases, when interfacing to an external legacy system, a flat-file system, or an in-memory database, a transaction may not be atomic.
For example, a client application may believe that a transaction has been rejected, but the database server does not. With a database manager that can make this mistake, the application itself must be able to generate a compensating transaction to roll back the update.
Data managers that do not use XA/DTC, DECdtm or Microsoft DTC to integrate with RTR using XA or DECdtm must be programmed to handle rtr_mt_msg1_uncertain messages .
For example, to illustrate the atomicity rules, Figure 3-3 shows the uncertain interval in a transaction sequence that the application program must be aware of and take into account, by performing appropriate rollback.
Figure 3-3 Uncertain Interval for Transactions

If there is a crash before the AcceptTransaction method ( rtr_accept_tx statement for the C API) is executed, on recovery, the transaction is replayed as rtr_mt_msg1 because the database will have rolled back the prior transaction instance. However, if there is a crash after the AcceptTransaction method or rtr_accept_tx statement is executed, on recovery, the transaction is replayed as rtr_mt_msg1_uncertain because RTR does not know the status of the prior transaction instance. Your application must understand the implications of such failures and deal with them appropriately.
A transaction either creates a new and valid state of data, or, if any failure occurs, returns all data to its state as it was before the start of the transaction. This is called consistency.
Several rules must be considered to ensure consistency:
The changes to shared resources that a transaction causes do not become visible outside the transaction until the transaction commits. This makes transactions serializable. To ensure isolation:
Figure 3-4 Concurrent Server Commit Grouping
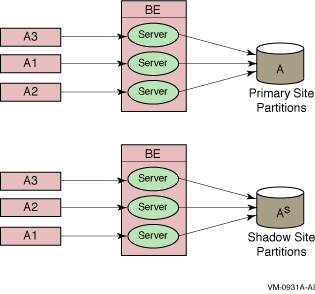
RTR commit grouping allows independent transactions to be scheduled together on the shadow secondary.
For a transaction to be durable, the changes caused by transaction commitment must survive subsequent system and media failure. Thus transactions are both persistent and stable.
For example, your bank deposit is durable if, once the transaction is complete, your account balance reflects what you have deposited.
The durability rule is:
If there are dependencies between separate RTR transactions, these should be considered carefully because the locking mechanisms of resource managers can cause unexpected behavior. These issues around locking mechanisms occur only if there is more than one server for the same partition.
For example, consider the case where there is a transaction T1 which inserts a record in the database and a subsequent transaction T2 which uses that record to make another update. If the partition has been configured with concurrent servers, it can happen that the update transaction T2 which has been given to a free server will begin executing and reach the database before the insert operation issued by transaction T1 has completed the commit process. In this scenario, the inserted record is not yet visible to the update transaction T2 because the commit is not yet complete. This will cause transaction T2 to fail. However, if the database table being updated is locked for the duration of the insert, transaction T2 will block (wait) until the insert has committed and there will be no possibility of transaction T2 overtaking transaction T1.
In another example, the first transaction T1 makes an update to the table and a second transaction T2 uses the updated value in its transaction. If the resource manager does not lock the row being accessed by transaction T1 right at the start of the update, that row can be queried by the second transaction T2 which has started on a concurrent server. However, transaction T2 will in this case be working with the old and not the updated value that was the result of T1. To prevent such unexpected and potentially undesirable behavior, check the locking mechanisms of the resource managers being used before using concurrent servers.
RTR provides client applications the option to specify a transaction timeout , but has no provision for server applications to specify a timeout on transaction duration. If there is a scarcity of server application processes, all other client transactions remain queued. If these transactions have also specified timeouts, they are aborted by RTR (assuming that the timeout value is less than 2 minutes).
To avoid this problem, the application designer has two choices:
The first (and easier) option is to use concurrent server processes. This allows transaction requests to be serviced by other free servers, even if one server is occupied by such a transaction that is taking a long time to disappear. The second option is to design the server application so that it can abort the transaction independently.
There are three cases where this use of concurrent servers is not ideal. First, there is an implicit assumption about how many such lingering transactions might remain on the system. In the worst case, this could exceed or equal the number of client processes. But having so many concurrent server processes to cater to this contingency is wasteful of system resources. Second, use of concurrent servers is beneficial when the servers do not need to access a common resource. For instance, if all these servers needed to update the same record in the database, they would simply be waiting on a lock taken by the first server. Additional servers do not resolve this issue. Third, it must make business sense to have additional servers. For example, if transactions must be executed in the exact order in which they entered the system, concurrent servers may introduce sequencing problems.
Take the example of the order matcher in a stock trading application. Business rules may dictate that orders be matched on a first-come, first- matched basis; using concurrent servers would negate this rule.
The second option is to let the server application process administer its own timeout and abort the transaction when it sees no activity on its input stream.
To ensure that transactions are fully executed and that the database is consistent, RTR uses the two-phase commit process for committing a transaction. The two-phase commit process has both a prepare phase and a commit phase. Transactions must reach the commit phase before they are hardened in the database.
The two-phase commit mechanism is initiated by the client when it executes a call to RTR that declares that the client has accepted the transaction. The servers participating in the transaction are then asked to be prepared to accept or roll back the transaction, based on a subsequent request.
Transactions are prepared before being committed by accept processing. Table 3-1 lists backend transaction states that represent the steps in the prepare phase.
| Phase | State | Meaning |
|---|---|---|
| Phase 0 | WAITING | Waiting for a server to become free. |
| RECEIVING | Processing client messages. | |
| Phase 1 | VREQ | Vote of server requested. |
| VOTED | Server has voted and awaits final transaction status. | |
| Phase 2 | COMMIT | Final status of a committed transaction delivered to server. |
| ABORT | Final status of an aborted transaction delivered to server. |
The RTR frontend sees several transaction states during accept processing. Table 3-2 lists frontend transaction states that represent the steps in the prepare phase.
| State | Meaning |
|---|---|
| SENDING | Processing, not ready to accept. |
| VOTING | Accept processing in process; frontend has issued an rtr_accept_tx call, but the transaction has not been acknowledged. |
| DONE | Transaction is complete, either accepted or rejected. |
Implementation details are shown in the separate chapters for the RTR APIs.
With RTR, client/server messaging enables the application to send:
With RTR, client and server applications communicate by exchanging messages in a transaction dialog. Transactional messages are grouped in a unit of work called a transaction. RTR takes ownership of a message when called by the application.
A transaction is a group of logically connected messages exchanged in a transaction dialog. Each dialog forms a transaction in which all participants have the opportunity to accept or reject the transaction. A transaction either commits or aborts. When the transaction is complete, all participants are informed of the transaction's completion status. The transaction succeeds if all participants accept it, but fails if even one participant rejects it.
In the context of a transaction, an RTR client application sends one or more messages to the server application, which responds with zero or more replies to the client application. Client messages can be grouped to form a transaction. All work within a transaction is either fully completed or all work is undone. This ensures transaction integrity from client initiation to database commit with the cooperation of the server application.
For example, say you want to take $20 from your checking account and add it to your savings account. With an application using RTR you are assured that this entire transaction is completed; you will not be left at the point where you have taken $20 from your checking account but it has not yet been deposited in your savings account. This feature of RTR is transactional integrity, illustrated in Figure 3-5.
Figure 3-5 Transactional Messaging
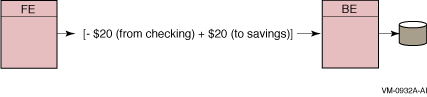
The transactional message is either all or nothing for everything enclosed in brackets [ ] in Figure 3-5.
An RTR client application sends one or more messages to one or more server applications and receives zero or more responses from one or more server applications. For example:
The client application:
The server application:
RTR generates a unique identifier, the transaction ID or TID, for each transaction. The client can inject also its own TID into RTR. Doing so will make RTR treat the transaction as a nested transaction.
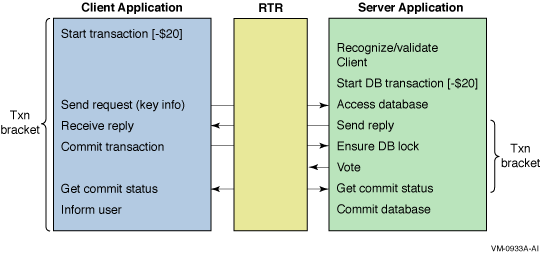
Figure 3-6 illustrates frontend/backend interaction with pseudo-code for transactions and shows transaction brackets. The transaction brackets show the steps in completing all parts of a transaction, working from left to right and top to bottom. The transaction (txn) is initiated at "Start txn" at the frontend, and completed after the "Commit txn" step on the backend. The transaction ID is encoded to ensure its uniqueness throughout the entire distributed system. In the prepare phase on the server, the application should lock the relevant database (db) records. The commit of a transaction hardens the commit to the database. The rtr_start_tx message specifies the characteristics of the transaction. RTR identifies the server based on key information in the transaction.
Figure 3-6 Transactional Messaging Interaction
Broadcast messaging lets client and server applications send non- transactional information to recipients. Recipients must be declared with the opposite role; that is, a client can send a broadcast message to servers, and a server can send a broadcast message to clients. Broadcasts are delivered on a "best try" basis; they are not guaranteed to reach every potential recipient. A broadcast message can be directed to a specific client or server, or be sent to all reachable recipients.
This point-to-point messaging using broadcast semantics is a feature to use instead of transactions when the information being sent is not recorded as a transaction in the database, and when you need to send information to several clients (or servers) simultaneously. For example, in a stock trading environment, when a trade has been completed and the stock price has changed, the application can use a broadcast message to send the new stock price to all trading stations. Another use for such messages is to inform the applications about a state change in the environment (for example, the fact that the exchange is now closed for business).
Other considerations when using broadcast messages include:
Broadcast messages are subject to flow control. A broadcaster may be blocked and unable to send messages when traffic is high and recipients are unable to process the broadcasts. The broadcaster sends at the minimum rate (MINIMUM_BROADCAST_RATE) which can be set to send "no matter what" for a given node. However, if an application does this, the application may in practice hold up broadcasts for others, and application design must take this into account. For example, no client application should be able to issue a Control S (^ S) to hold up all broadcasts. If an application doing broadcasts works with transactions that might get held up, it may be time to consider using multiple channels on multiple threads.
RTR guarantees that broadcasts are received in the same order as sent by a specific sender. However, if there is more than one sender in an application, different recipients can receive broadcasts in different orders. For example, Sender A could send broadcasts ABC and Sender B, broadcasts XYZ. These could be received by two different recipients as ABCXYZ or XYZABC. If this is important in your application, correct application design is to use one sender that takes in all input needed for such broadcasts.
Consider a shadowed trading environment that initiates 5PM processing with a broadcast for closing of the exchange. Application design should send broadcasts and transactions through different pipes. Because RTR does not guarantee receipt of a broadcast at all servers, but does guarantee receipt of transactions, this critical "broadcast" could be most effectively handled by being sent in a transaction as an event through the transaction pipe.
There is no replay or recovery for broadcasts.
A broadcast can sometimes be lost. This can be caused by link loss or perhaps when there is excessively high volume.
There is overhead associated with managing and correcting for loss of broadcasts. Thus Compaq recommends that applications do not use broadcasts for critical information. If, however, an application decides to use broadcasts and wants to ensure that all broadcasts are accounted for, one approach is to add a tracking sequence number to each broadcast that is sent out. All recipients can then check for missing sequence numbers and request a resend of any missing broadcasts.
A client or server application may need to send unsolicited messages to one or more participants. Applications tell RTR which broadcast classes they want to receive.
The sender sends one message received by several recipients. Recipients subscribe to a specific type of message. Delivery is not guaranteed. Broadcast messages can be:
Clients cannot broadcast to other clients, and servers cannot broadcast to other servers. To enable communication between two applications of the same type, open a second instance of the application of the other type. Messaging destination names can include wildcards, enabling flexible definition of the subset of recipients for a particular broadcast.
Broadcast types include user events and RTR events; both are numbered.
Event numbers are provided as a list beginning with RTR_EVTNUM_USERDEF and ending with RTR_EVTNUM_ENDLIST . To subscribe to all user events, an application can use the range indicators RTR_EVTNUM_USERBASE and RTR_EVTNUM_USERMAX , separated by RTR_EVTNUM_UP_TO , to specify all possible user event numbers.
A user broadcast is named or unnamed. An unnamed broadcast does a match on user event number; the event number completely describes the event. A named broadcast does a match on both user event number and recipient name. The recipient name is a user-defined string. Named broadcasts provide greater control over who receives a particular broadcast.
Named events specify an event number and a textual recipient name. The name can include wildcards (% and *).
For all unnamed events specify the evtnum field and RTR_NO_RCPSPC as the recipient name.
| Previous | Next | Contents | Index |