| Previous | Contents | Index |
The cluster environment can be important to the smooth failover characteristics of RTR. This environment is slightly different on each operating system. The essential features of clusters are availability and the ability to access a common disk or disks. Basic cluster configurations are illustrated below for the different operating systems where RTR can run.
An OpenVMS cluster provides disk shadowing capabilities, and can be based on several interconnects including:
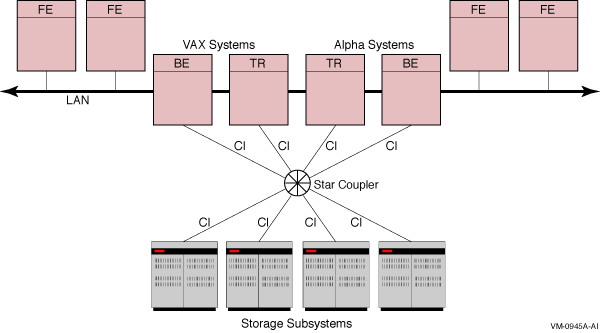
Figure B-1 shows a CI-based OpenVMS cluster configuration. Client applications run on the frontends; routers and backends are established on cluster nodes, with backend nodes having access to the storage subsystems. The LAN is the Local Area Network, and the CI is the Computer Interconnect joined by a Star Coupler to the nodes and storage subsystems. Network connections can include Compaq GIGAswitch subsystems.
Figure B-1 OpenVMS CI-based Cluster
For other OpenVMS cluster configurations, see the web site
http://www.compaq.com/software/OpenVMS .
The Tru64 UNIX TruCluster is typically a SCSI-based system, but can also use Memory Channel for greater throughput. Considered placement of frontends, routers, and backends can ensure transaction completion and database synchronization. The usual configuration with a Tru64 UNIX TruCluster contains PCs as frontends, establishes cluster nodes as backends, and can make one node the primary server for transactional messaging with a second as standby server. Because this cluster normally contains only two nodes, a third non-cluster node on the network can be set up as a tie-breaker to ensure that the cluster can attain quorum. Figure B-2 illustrates a Tru64 UNIX TruCluster configuration.
Figure B-2 Tru64 UNIX TruCluster Configuration
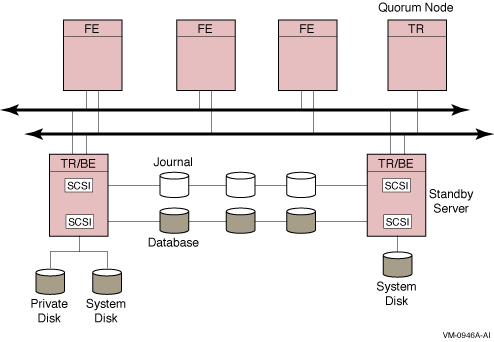
When using standby servers in the Compaq Tru64 UNIX TruCluster environment, the RTR journal must be on a shared device.
In the Windows NT environment, two Intel servers managed and accessed as a single node comprise an NT cluster. You can use RAID storage for cluster disks with dual redundant controllers. A typical configuration would place the RTR frontend, router, and backend on the cluster nodes, as shown in Figure B-3 and would include an additional tie-breaker node on the network to ensure that quorum can be achieved.
Figure B-3 Windows NT Cluster
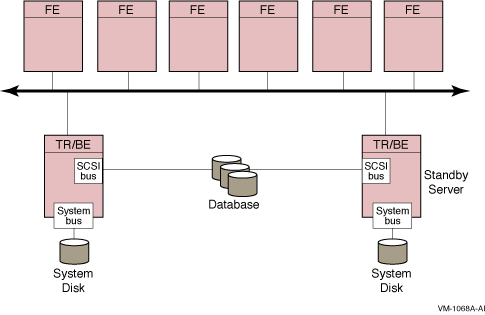
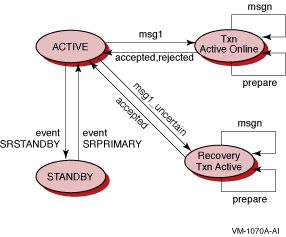
Figure C-1 shows server states after delivery of a primary or secondary event, and message types used with primary and secondary servers.
Figure C-1 Server Events and States with Active Transaction Message Types
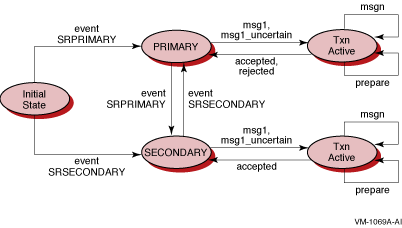
Figure C-2 shows server states after delivery of a standby event, and message types used with transactions that are active or in recovery.
Figure C-2 Server States after Standby Events
The application must specify server type with boolean attributes using the CreateBackEndPartition method in the RTRManager class. For example, the following declaration establishes a standby server with concurrency:
CreateBackEndPartition( *pszPartitionName,
pszFacility,
pKeySegment
bShadow=false
bConcurrent=true
bStandby=true);
|
To add a transactional shadow server, use: bShadow = true
To disallow a standby server, use: bStandby = false
With the C++ API, you enable RTR failover behavior with the
CreateBackEndPartition method in the RTRPartitionManager management
class.
For the C++ API, concurrent servers can be implemented as many server transaction controllers in one process or as one or many server transaction controllers in many processes.
RTR delivers transactions to any open transaction controllers, so each application thread must be ready to receive and process transactions.
An application creates a transaction controller and registers a partition with the RegisterPartition method. To specify whether or not a server is concurrent, the application uses the CreateBackendPartition method in the RTRPartitionManager class. The rules are as follows:
For example, the following declaration establishes a concurrent server that is also a standby:
CreateBackEndPartition( *pszPartitionName,
pszFacility,
pKeySegment
bShadow=false
bConcurrent=true
bStandby=true);
|
The following declaration establishes a server with no concurrency:
CreateBackEndPartition( *pszPartitionName,
pszFacility,
pKeySegment
bShadow=false
bConcurrent=false
bStandby=true);
|
For more information on the CreateBackEndPartition method, see the Reliable Transaction Router C++ Foundation Classes manual.
RTR manages the activation of standby servers at run time.
When an application creates a server partition with the CreateBackEndPartition method in the RTRPartitionManager class, it specifies whether a server is to be standby or not as follows:
CreateBackEndPartition ( *pszPartitionName,
pszFacilityName,
*pKeySegment,
bShadow = false,
bConcurrent = true,
bStandby = false);
|
When an application creates a server partition with the CreateBackEndPartition method in the RTRPartitionManager class, it specifies whether a server is to be a shadow or not as follows:
CreateBackEndPartition ( *pszPartitionName,
pszFacilityName,
*pKeySegment,
bShadow = true,
bConcurrent = true,
bStandby = false);
|
Only one primary and one secondary shadow server can be established. Shadow servers can have concurrent servers.
When partition state is important to an application, the application can determine if a shadow server is in the primary or secondary partition state after server restart and recovery following a server failure. The application does this using methods in the RTRServerEventHandler class such as OnServerIsPrimary, OnServerIsStandby, and OnServerIsSecondary. For example:
OnServerIsPrimary(*pRTRData, *pController); |
Within your application server code, you identify those transactions that can be considered independent, and set the state of the transaction controller object with the bIndependent attribute in the AcceptTransaction method, as appropriate. The following example illustrates how to set the bIndependent parameter to true with the AcceptTransaction method to make a transaction independent.
RTRServerTransactionController *pController= new
RTRServerTransactionController();
pController->AcceptTransaction(RTR_NO_REASON, true);
|
Another example:
RTRServerTransactionController stc;
/* Determine from our business logic if this transaction is independent of our
other transactions. */
If (true == Independent())
{
stc.AcceptTransaction(RTR_NO_REASON,true)
}
else
{
stc.AcceptTransaction()
}
|
The application specifies the server type in the rtr_open_channel call as follows:
rtr_status_t rtr_open_channel ( . rtr_ope_flag_t |
To add a transactional shadow server, include the following flags: flags = RTR_F_OPE_SERVER RTR_F_OPE_SHADOW;
To disallow concurrent and standby servers, use the following flags:
flags = RTR_F_OPE_SERVER | RTR_F_OPE_NOCONCURRENT | RTR_F_OPE_NOSTANDBY; |
With the C API, you enable RTR failover behavior with flags set when your application executes the rtr_open_channel statement or command.
For the C API, concurrent servers can be implemented as many channels in one process or as one or many channels in many processes. By default, a server channel is declared as concurrent.
RTR delivers transactions to any open channels, so each application thread must be ready to receive and process transactions. The main constraint in using concurrent servers is the limit of available resources on the machine where the concurrent servers run.
When an application opens a channel with the rtr_open_channel call, it specifies whether the server is to be concurrent or not, as follows:
For example, the following code fragment establishes a server with concurrency:
rtr_open_channel(&Channel, RTR_F_OPE_SERVER, FACILITY_NAME, NULL, RTR_NO_PEVTNUM, NULL, Key.GetKeySize(), Key.GetKey() != RTR_STS_OK); |
If an application starts up a second server for a partition on the same node, the second server is a concurrent server by default.
The following example establishes a server with no concurrency:
rtr_open_channel(&Channel, RTR_F_OPE_SERVER|RTR_F_OPE_NOCONCURRENT, FACILITY_NAME, NULL, RTR_NO_PEVTNUM, NULL, Key.GetKeySize(), Key.GetKey() != RTR_STS_OK); |
When a concurrent server fails, the server application can fail over to another running concurrent server, if one exists.
Concurrent servers are useful both to improve throughput using multiple channels on a single node, and to make process failover possible. Concurrent servers can also help to minimize timeout problems in certain server applications. For more information on this topic, see the section later in this manual on Server-Side Transaction Timeouts.
For more information on the rtr_open_channel call, see the Reliable Transaction Router C Application Programmer's Reference Manual and the discussion later in this document.
RTR manages the activation of standby servers at run time.
When an application opens a channel, it specifies whether or not the server is to be standby, as follows:
When an application opens a channel, it specifies whether the server is to have the capability to be a transactional shadow server or not, as follows:
Only one primary and one secondary shadow server can be established. Shadow servers can also have concurrent servers.
When partition state is important to an application, the application can determine if a shadow server is in the primary or secondary partition state after server restart and recovery following a server failure. The application does this using RTR events in the rtr_open_channel call, specifying the events RTR_EVTNUM_SRPRIMARY and RTR_EVTNUM_SRSECONDARY . For example, the following is the usual rtr_open_channel declaration:
rtr_status_t
rtr_open_channel (
rtr_channel_t *p_channel, //Channel
rtr_ope_flag_t flags, //Flags
rtr_facnam_t facnam, //Facility
rtr_rcpnam_t rcpnam, //Name of the channel
rtr_evtnum_t *p_evtnum, //Event number list
//(for partition states)
rtr_access_t access, //Access password
rtr_numseg_t numseg, //Number of key segments
rtr_keyseg_t *p_keyseg //Pointer to key-segment data
)
|
To enable receipt of RTR events that show shadow state, used if an application needs to include logic depending on partition state, the application enables receipt of RTR events that show shadow state.
The declaration includes the events as follows:
rtr_evtnum_t evtnum = {
RTR_EVTNUM_RTRDEF,
RTR_EVTNUM_SRPRIMARY,
RTR_EVTNUM_SRSECONDARY,
RTR_EVTNUM_ENDLIST
};
rtr_evtnum_t *p_evtnum = &evtnum;
|
Broadcasts deliver using name and subscription name. For details, see the descriptions of rtr_open_channel and rtr_broadcast_event in the RTR C Application Programmer's Reference Manual.
Within your application server code, you identify those transactions that can be considered independent, and process them with the independent transaction flags on rtr_accept_tx or rtr_reply_to_client calls, as appropriate. For example, the following code fragment illustrates use of the independent transaction flag on the rtr_accept_tx call:
case rtr_mt_prepare:
/* if (txn is independent).*/
status = rtr_accept_tx (channel,
RTR_F_ACC_INDEPENDENT,
RTR_NO_REASON\\);
if (status != RTR_STS_OK)
|
You can also use the independent flag on the rtr_reply_to_client call. For example,
rtr_reply_to_client(channel, RTR_F_REP_INDEPENDENT, pmsg, msglen, msgfmt); |
An application subscribes to an RTR event with the rtr_open_channel call. For example,
rtr_status_t
rtr_open_channel(
.
rtr_rcpnam_t rcpnam = RTR_NO_RCPNAM;
rtr_evtnum_t evtnum = {
RTR_EVTNUM_RTRDEF,
RTR_EVTNUM_SRPRIMARY,
RTR_EVTNUM_ENDLIST
};
rtr_evtnum_t *p_evtnum = &evtnum; )
|
You read the message type to determine what RTR has delivered. For example,
rtr_status_t rtr_receive_message ( . rtr_msgsb_t *p msgsb ) |
Use a data structure of the following form to receive the message:
typedef struct {
rtr_msg_type_t msgtype;
rtr_usrhdl_t usrhdl;
rtr_msglen_t msglen;
rtr_tid_t tid;
rtr_evtnum_t evtnum; /*Event Number*/
} rtr_msgsb_t;
|
The event number is returned in the message status block in the evtnum field. The following RTR events return key range data back to the client application:
RTR_EVTNUM_KEYRANGEGAIN
RTR_EVTNUM_KEYRANGELOSS
|
These data are included in the message (pmsg); size is
msglen_sizeof(rtr_msgsb_t)
. Other events do not have additional data.
Use the following brief checklist to help diagnose a particular performance problem:
Excessive use of a MONITOR command can be disruptive to the system. For example, running several MONITOR commands simultaneously steals cycles away from RTR to do real work. To minimize the impact of using MONITOR commands, increase the sample size interval using /INTERVAL= no-of-seconds . |
| Index | Contents |