| 前へ | 次へ | 目次 | 索引 |
この章では,Compaq OpenVMS デバッガの起動方法と日本語拡張機能の利用方法について説明します。
8.1 デバッガの起動
ここでは標準版デバッガの日本語拡張機能を有効にする方法を説明します。
日本語拡張機能を有効にするためにはデバッグ・イメージあるいはデバッガ本体を起動する前に以下の論理名定義を行ってください。
$ DEFINE/JOB DBG$NATIONALITY JAPAN |
さらに端末インタフェースで日本語入出力機能を有効にするには以下の論理名定義を行ってください。
$ DEFINE/JOB SMGSHR JSY$SMGSHR |
$ DEFINE/JOB DBG$SMGSHR JSY$SMGSHR $ DEFINE/JOB SMG$DEFAULT_CHARACTER_SET SDK |
この定義により以降のデバッグ・セッションでは日本語拡張機能が有効となった状態で標準版デバッガが起動されます。
8.2 DECwindows Motif モードでの日本語の使用方法
DECwidnwos Motif 上でデバッガを使用し,日本語を含むプログラムをデバッグする場合,以下の方法によりデバッガのリソース・ファイルのフォント情報を変更する必要があります。
DECwindows Motif モードでデバッガを1度起動し,Options メニューの Save Options サブメニューを選択します。デバッガはそのまま終了させてください。
LOGIN ディレクトリに VMSDEBUG.DAT というファイルが生成されます。以 下の各項目の ":" より後ろをそれぞれ行末まで削除してください。
DebugInstruction.Font:
DebugControl.MonitorViewSecondaryFont:
DebugControl.MessageViewFont:
DebugControl.MonitorViewPrimaryFont:
DebugSource.Font:
|
上記によりデバッガが使用するフォントはシステム標準のフォントとなり,日本語が正しく表示されるようになります。なお,上記の操作はデバッガを最初に使うときに1度行えばそれ以降行う必要はありません。 VMSDEBUG.DAT を誤
って消してしまった場合等はやりなおしてください。
8.3 日本語拡張機能
ここでは日本語拡張機能が有効の場合にのみ使用できる機能を説明します。
8.3.1 日本語利用者語
COBOL および STDL プログラムのデバッグ時に COBOL の利用者語と STDL の内部識別子に対してそれぞれの言語で拡張されている日本語利用者語および日本語内部識別子が使用できます。
8.3.2 Super DEC 漢字のサポート
日本語拡張機能を有効にした場合,文字リテラルおよびコメント中に半角カタカナ,補助漢字を含む Super DEC 漢字のすべてを使用できます。
8.3.3 変換ユーザ・キー定義ライブラリ(IMLIB)による日本語入力のサポート
日本語 VMS V5.5 以前のデバッガでは日本語入力に独自のルーチンを用いていたため変換キーの定義は固定で,ユーザによるカスタマイズを行うことはできませんでした。日本語 Compaq OpenVMS V6.0以降では日本語画面管理ユーティリティを用いているので,変換ユーザ・キー定義ライブラリ(IMLIB)を使うことにより,ユーザ独自の変換キー定義を行うことができます。また,日本語画面管理ユーティリティ,日本語入力プロセスを使った他のアプリケーションと共通のキーを使うことが可能となります。
変換キーの設定は日本語環境設定ユーティリティ (JSY$CONTROL) を使うと簡単に設定できます。詳しくは 第 1 章 を参照してください。
8.4 wchar_t データタイプのサポート
C 言語の wchar_t データタイプのデータのデバッグ方法について説明します。ただし,DEC C コンパイラは wchar_t データタイプを typedef により実現しているため,ユーザがプログラム中で wchar_t データタイプを用いても C コンパイラが生成するデバッグ情報中では wchar_t データタイプとはなっていません。そのためデバッガは wchar_t データタイプとして認識できないため,以下に示すように /WCHAR_T 修飾子を指定する必要があります。
ファイルコードとプロセスコード間の変換はデバッガを起動したときのロケール情報に従います。
本機能は日本語拡張機能が無効の場合も動作します。
8.4.1 EXAMINE コマンド
DBG> EXAMINE /WCHAR_T[:文字数] アドレス表現 |
アドレス表現で表されるアドレスから文字数分の内容を wchar_t データ・タイプのデータであるとみなし,ファイル・コードに変換して表示します。文字数を省略した場合は1文字を表示します。
8.4.2 DEPOSIT コマンド
DBG> DEPOSIT /WCHAR_T[:文字数] アドレス表現 = "文字列" |
文字列を対応するプロセス・コードに変換し,アドレス表現で表されるアドレスから文字数分の内容を置き換えます。文字数を省略した場合は1文字を置き換えます。
日本語 OpenVMS V7.2 から,新しく日本語DECnet/SNA リモート・ジョブ・エントリ/OpenVMS (RJE) の機能が追加されています。この章では,これらの新機能について説明します。
9.1 機能概要
日本語DECnet/SNA リモート・ジョブ・エントリ/OpenVMS (以下日本語RJE) は, JSNACODE ユーティリティおよび JSNAKNJDEFユーティリティから構成されるソフトウェア製品です。
Digital SNA Remote Job Entry for OpenVMS と組み合わせて使用することにより, DECnet SNA Gateway-ST,DECnet SNA Gateway-CT を通して,ハイレベルな伝送制御方式で接続された IBM システムと OpenVMS システムとの間で,漢字コードを含むファイルの送受信を行うことができます。
JSNACODE ユーティリティを使用し,IBM-DEC のファイル単位でのコード変換を行うことができます。JSNAKNJDEF ユーティリティを使用して,外字の登録を行うことができます。
9.1.1 関連資料
Digital SNA Remote Job Entry for OpenVMS については,次のマニュアルを参考にしてください。
漢字コードについては,次のマニュアルを参考にしてください。
必要に応じて,次のIBM社のマニュアルも参照してください。
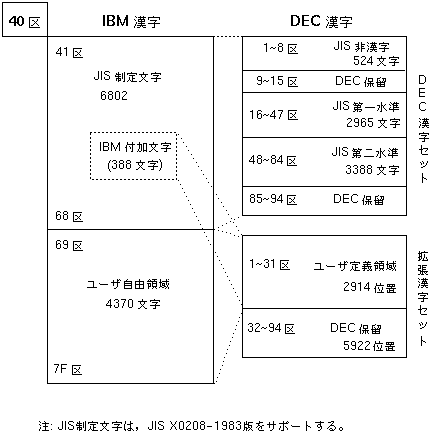
IBM漢字コードとDEC漢字コードを相互に変換するための2バイト・コード体系の対応を 図 9-1 に示します。
図 9-1 が示すように, IBM漢字空間のJIS漢字コードについては DEC漢字セットの対応する各文字に対応付けられ, IBM付加文字(338文字) およびIBMユーザ定義文字(4,370文字) については,日本語RJE利用者の選択によりDEC拡張漢字セットのユーザ定義領域に対応付けます。その際,次のような対応規則を設定します。
| IBM漢字セット | 対応規則 |
|---|---|
| JIS制定文字 | DEC漢字セットと一対一対応 |
| IBM付加文字 | DEC拡張漢字セットの連続6区間と対応 |
| IBMユーザ定義文 | DEC拡張漢字セットの連続2区間 |
| 字の1区間 |
図 9-1 IBM-DEC漢字コード対応図
EBCDIC/ASCIIの1バイト・コード変換テーブルについては,日本語RJEが提供する変換テーブルであるSYS$LIBRARY:JSNARJETRA.TBL が省略値として使用されます。これ以外のテーブルを使用する場合には, JSNACODEコマンドの/CHARACTERSET修飾子で指定します。 /CHARACTERSET修飾子については, 第 9.2 節
を参照してください。 1バイト変換テーブルの作成方法については, SYS$LIBRARY:JSNARJEPRE.MAR を参照してください。
9.1.4 ソフトウェア構成
日本語 RJE は次の 2 つのユーティリティから構成されています。
JSNACODE ユーティリティは,日本語 DECnet SNA リモート・ジョブ・エントリ/OpenVMS (以下日本語RJE) の本体となる部分のソフトウェアです。日本語 OpenVMS の DCL (Digital Command Language) のフォーリン・コマンドにより起動され,その際に指定された入力ファイルを指定されたコマンド修飾子に従って変換し,出力ファイルを作成します。
9.2.1 起動方法
次のコマンドでJSNACODEを起動します。
$ JSNACODE :== $JSNACODE |
$ JSNACODE/IPC=DEC/OPC=IBM 入力ファイル名出力ファイル名 |
または
$ JSNACODE/IPC=IBM/OPC=DEC 入力ファイル名出力ファイル名 |
この節では,JSNACODE コマンドの形式,パラメータ,修飾子について説明します。
入力ファイルを修飾子の指示に従い変換し,出力ファイルを作成します。
JSNACODE 入力ファイル指定 [ 出力ファイル指定 ]
入力ファイル指定
変換対象のファイル名。順編成,テキストファイル。出力ファイル指定
変換した結果のファイル名。順編成,テキストファイル。
コマンド修飾子 省略時の値 /IPC= keyword /IPC = DEC /OPC= keyword /OPC = DEC /CHARACTERSET=ファイル名 /CHARACTERSET=JSNARJEDEF /[NO]ESCAPE[=SS|LS] /ESCAPE=SS(/KMAPを指定した場合は/NOESCAPE) /[NO]EXTERNAL=外字管理ファイル名 /NOEXTERNAL /FIELD=(START:n,END:n,LENGTH:n,KANJI|KATAKANA) なし /[NO]KMAP=KMAPレコード数 /NOKMAP(レコード数の省略値は1) /[NO]TAB /NOTAB /IPC = keyword
入力ファイルのコード体系を指定します。ここで指定できるkeywordは次の2つです。
/IPC=DEC(省略時設定)
- IBM
- DEC
/OPC = keyword
出力ファイルのコード体系を指定します。ここで指定できるkeywordは次の2つです。
/OPC=DEC(省略時設定)
- IBM
- DEC
/CHARACTERSET=1バイトコード変換テーブル名
1 バイトコード変換テーブルのファイル名を指定します。 1 バイトコード変換テーブルについては, 第 9.1.3 項 を参照してください。
/CHARACTERSET=JSNARJEDEF(省略時設定)
注意
JSNACODE ユーティリティが1バイトコード変換テーブルへのアクセス中に何らかのエラーを検出した場合は,その旨を告げるメッセージを表示し,出力ファイルは消去されます。
/[NO]ESCAPE[=SS|LS]
/ESCAPE=SS (/KMAPを指定した場合は/NOESCAPE) (省略時設定)
- /ESCAPE=SSの場合
- /IPC=DEC/OPC=IBMの場合
入力ファイルのデータ中にSS2(X'8E') が現われた場合,次の1バイトをJISカタカナ・コードセットと解釈します。 SS2が付加されずにX'A1'以上X'FE'以下のコードが現れた場合は,全角コードの上位バイトと解釈します。/ESCAPEと/KMAPは同時には指定できません。この指定がない場合は,/KMAPの指定に従います。変換したIBMコードの全角文字列の前後にはシフトコード(X'0E',X'0F')が挿入されます。
- /IPC=IBM/OPC=DECの場合
JISカタカナ・コードセットに変換された場合は,前にSS2を付加してからファイルに出力します。この出力ファイルは,端末またはプリンタに直接出力する最終形式のファイルを想定しています。 /ESCAPEと/KMAPは同時には指定できません。指定がない場合は,/KMAPの指定に従います。
- /ESCAPE=LSの場合
- /IPC=DEC/OPC=IBMの場合
/ESCAPE の指定がある場合,入力ファイルのデータ中に LS3R (ESC|) が現われたとき以後,X'A1' 以上 X'FE' 以下のコードを全角コードの上位バイトと解釈します。LS2R(ESC}) が現われたとき以後のコードを,すべて 1 バイト・コードと解釈します。/ESCAPE と /KMAP は同時には指定できません。この指定がない場合は,/KMAP の指定に従います。変換した IBM コードの全角文字列の前後にはシフトコード (X'0E',X'0F') が挿入されます。
- /IPC=IBM/OPC=DECの場合
/ESCAPEの指定がある場合,出力ファイル中にDEC漢字コードのエスケープ・シーケンスを挿入します。この出力ファイルは,端末またはプリンタに直接出力する最終形式のファイルを想定しています。 /ESCAPEと/KMAPは同時には指定できません。指定がない場合は,/KMAPの指定に従います。
/ESCAPE 修飾子を指定せずに,グローバル・シンボル JSNARJE$ESCAPE=="SS|LS" を定義することにより, /ESCAPE=SS または /ESCAPE=LS と指定した場合と同じ結果が得られます。ただし,明示的に /ESCAPE=SS|LS を指定した場合は,グローバル・シンボルより優先されます。/[NO]EXTERNAL=外字管理ファイル名
IBM 付加文字や IBM ユーザ定義文字を,DEC ユーザ定義領域のどの文字コードに割り当てるかを定めた外字管理ファイル名を指定します。外字管理ファイルは, JSNAKNJDEF ユーティリティにより作成,管理されるファイルです。 /EXTERNAL を指定した場合は,必ず外字管理ファイル名を指定しなければなりません。
/NOEXTERNAL (省略時設定)/EXTERNAL の指定がない場合,IBM から DEC への変換の場合は IBM 付加文字や IBM ユーザ定義文字はすべて "□" (X'A2A2') に,DEC から IBM への変換の場合も, DEC 拡張漢字セットの文字はすべて "□"(X'A2A2') に変換します。
/FIELD=(START:n,END:n,LENGTH:n,KANJI|KATAKANA)
1 レコード内の変換の範囲を指定します。 1 回の JSNACODE コマンドの最大長は 256 バイトです。この 1 コマンド列で規定すべきフィールド数が指定できない場合は,複数回の JSNACODE コマンドを使用してください。各々の /FIELD 修飾子で指定する範囲が重なってはいけません。/FIELD 修飾子の指定がない時は,1 レコード全体が変換の対象になります。 START の省略値はレコードの先頭で,END,LENGTH の省略値はレコードの最後の位置を示す値です。 END と LENGTH は同時には指定できません。 /FIELD 修飾子を 33 個以上指定しても,33 個目からの修飾子は無視されます。 /FIELD 修飾子は /ESCAPE とは同時に指定できません。
モード指定の KATAKANA と KANJI は,同時に指定することはできません。
- /IPC = DEC/OPC = IBMの場合
モード指定のkeywordは,出力ファイルの開始/終了モードを指定します。 DEC側の開始モードは,KMAP ファイルの指定に依存します。
- /IPC=IBM/OPC=DECの場合
モード指定の keyword は,入力ファイルの開始/終了モードを指定します。/FIELD 修飾子を指定しない場合は,先頭レコードが 2 バイト・コード開始のシフト・コード(X'0E') で始まらない限り,英数字モードから始まるものとみなします。
/[NO]KMAP=KMAPレコード数
KMAPレコード数の省略値は1です。
/NOKMAP(省略時設定)
- /IPC=DEC/OPC=IBMの場合
/KMAPを指定した時,入力ファイルと同じファイル名で,ファイル・タイプが"KMAP"であるファイルが,入力ファイルの全角・半角コード混在情報を示すKMAPファイルであるとみなされます。ただし,論理名JSNA$KMAPFILE が定義されている場合には,この論理名に割り当てられているファイルが優先的に使用されます。そして,その情報にしたがってコード変換を行います。
KMAP レコード数の指定がある場合,KMAP ファイルの先頭レコードから指定されたレコード数を変換する際に使用します。 KMAP ファイル内の全 KMAP レコード数が指定された値より小さい場合は,全 KMAP レコード数が指定されているものとして処理されます。 /KMAPと /ESCAPE は同時には指定できません。
この指定がない場合は,/ESCAPE の指定に従います。
また KMAP コードが "Xk" で対応する入力コードが漢字コードだった場合は, KMAP コードは "XX" であるとみなします。
- /IPC=IBM/OPC=DECの場合
/KMAP の指定がある場合,コマンド・パラメータで指定した出力ファイル中に DEC 漢字コードのエスケープ・シーケンスを挿入せず,出力ファイルと同じファイル名でファイル・タイプが "KMAP" のファイルを作成し,全角・半角コードの混在情報を出力します。または,論理名JSNA$KMAPFILEが割り当てられているファイル名が優先的に使用されます。 KMAP レコード数の指定がある場合, KMAP ファイルに出力されるのは出力ファイルの先頭レコードから数えて KMAP レコード数分のレコードに対する全角・半角コードの混在情報です。
/KMAP と /ESCAPE は同時には指定できません。この指定がない場合は /ESCAPE の指定に従います。/[NO]TAB
この修飾子は/IPC=DEC/OPC=IBMの指定の場合に有効です。
/NOTAB(省略時設定)/TABの指定がある場合は,タブをそれ自体有効なコードと解釈し,タブ・コードを空白文字列へ変換することを行いません。
/NOTABの指定がある場合は,タブ・コードを次の文字位置が8の倍数となるようにタブ文字を空白文字に変換します。
空白文字列の変換は,DEC コードから IBM コードへの変換の前に行われます。したがって全角コードの前後に挿入されるシフトコード文字 (X'0E',X'0F') はタブ位置の計算には含まれません。
| 前へ | 次へ | 目次 | 索引 |