$ SORT NAMES.LST BYNAME.LST |
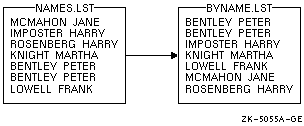
このコマンドは, 図 11-1 に示すように,出力ファイルBYNAME.LST を作成します。
図 11-1 昇順にソートした結果
$ SORT NAMES.LST,NAMES2.LST BYNAME.LST |
| 前へ | 次へ | 目次 | 索引 |
本章では,OpenVMS の Sort/Merge ユーティリティ (SORT/MERGE) の使用方法について説明します。 Sort/Mergeユーティリティは,次の2種類の作業を実行します。
Alphaシステムでは, 高性能Sort/Mergeユーティリティ を選択することもできます。このユーティリティでは,Alphaアーキテクチャを活用することにより,ほとんどのSort操作およびMerge操作で性能を向上させることができます。詳細は 第 11.1 節 を参照してください。
本章では,次のことを説明します。
その他の情報については,次のものを参照してください。
Alphaシステムでは, 高性能Sort/Mergeユーティリティ を選択することもできます。このユーティリティでは,Alphaアーキテクチャを活用することにより,ほとんどのSort操作およびMerge操作で性能を向上させることができます。
高性能Sort/Mergeユーティリティは, SORT/MERGEと同じコマンド行インタフェースを使用します。高性能Sort/MergeユーティリティとSORT/MERGEとの違いについては,本章で紹介します。
高性能Sort/Mergeユーティリティを使用するときは,論理名 SORTSHR を使用します。次のようにSORTSHRを定義して, SYS$LIBRARYにある高性能ソート実行可能プログラムを指定します。
$ define sortshr sys$library:hypersort.exe |
SORT/MERGEに戻るときは,SORTSHRの割り当てを解除します。 SORTSHRが定義されていない場合, SORT/MERGEユーティリティが省略時の値として設定されます。
高性能 Sort/Merge ユーティリティの動作は,ほとんど SORT/MERGE ユーティリティの動作と同じです。相違点は, 表 11-1 に示します。
サポートされていない修飾子を使用しようとしたり,サポートされていない値を修飾子に指定しようとしたりすると,高性能 Sort/Merge ユーティリティはエラーを表示します。
| キー・データ・タイプ | H-FLOATING および ZONED 10 進データ・タイプはサポートされていません。
BINARY データ・タイプ・キーのサイズは, 1 バイト,2 バイト,4 バイト,8 バイトのいずれかでなければなりません。 16 バイトのバイナリ・キーはサポートされていません (これは OpenVMS Alpha の将来のリリースでサポートされる予定です)。 |
| 照合順序 | NCS(National Character Set)照合順序はサポートされていません (これは OpenVMS Alpha の将来のリリースでサポートされる予定です)。 /COLLATING_SEQUENCE 修飾子に NCS 照合順序を指定しないでください。 ASCII,EBCDIC,および MULTINATIONAL 照合順序はサポートされています。省略時の設定は ASCII です。
指定ファイルを使用して,照合順序を定義したり変更したりすることはできません (これは OpenVMS Alpha の将来のリリースで解決される予定です)。 |
| 指定ファイル | 指定ファイルはサポートされていません (これは OpenVMS Alpha の将来のリリースでサポートされる予定です)。 /SPECIFICATION 修飾子は使用しないでください。 |
| 内部ソート・プロセス | レコードのソート・プロセスのみサポートされています (これは OpenVMS Alpha の将来のリリースで解決される予定です)。 /PROCESS=RECORD 修飾子を指定することも,または /PROCESS 修飾子を省略することもできます。 /PROCESS 修飾子で TAG, ADDRESS,および INDEX を指定しないでください。 |
| 統計情報 | 現在サポートされているのは次の統計情報です。
Records read (読み込まれたレコード数) 次の統計情報は利用できません。 Internal length (内部長) この機能の完全な実装は将来の OpenVMS Alpha リリースで行われる予定です。 |
ファイルをソートするときは,DCLのSORTコマンドを使用します。ソートする入力ファイルを複数指定するときは,それぞれのファイルをコンマで区切り,最終的に作成されるソート済みの出力ファイルの名前をその後に続けます。
オプションとして,ソートに使用する各フィールドのキーを指定することができます。それぞれのキーには,次の情報が含まれます。
キーを指定しないでソートを行う場合,キーが1つだけ存在しており,このキー・フィールドが次のようになっているものと想定されます。
次の 2 つの例は,省略時のキーが使用されています。
$ SORT NAMES.LST BYNAME.LST |
このコマンドは, 図 11-1 に示すように,出力ファイルBYNAME.LST を作成します。
図 11-1 昇順にソートした結果
$ SORT NAMES.LST,NAMES2.LST BYNAME.LST |
すべての SORTの修飾子の一覧については,
第 11.9 節 を参照してください。
11.2.1 キーの定義
キーを定義するときは,/KEY修飾子を使用します。複数のキーを指定するときは,それぞれのキーごとに/KEY 修飾子を使用します。
表 11-2 は,キーを構成する5つの要素について説明しています。
| キー要素 | 値 | 説明 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| キーの位置 | POSITION: n | レコード内にあるキー・フィールドの1バイト目の位置を表す。レコードの1バイト目が1になる。 POSITION: nは必ず指定しなければならない。 | |||||||||||||||
| キー・サイズ | SIZE: n | キー・フィールドの長さを表す。浮動小数データの場合を除き, SIZE:
nは必ず指定しなければならない。
キーに指定するデータ型により,サイズを指定するときに受け付けられる値が決まる。次の表は,それぞれのデータ型に対応する値と,キーのサイズを指定するときに使用する単位を表す。
10進データでは,10進記号が別のバイトに格納される場合,そのバイトはデータのサイズにカウントされない。 指定したキーがレコードの終わりを越えた場合,失われた文字は空文字として扱われる。 |
|||||||||||||||
| データ型 | CHARACTER | 文字データ。CHARACTERが省略時のデータ型になる。 | |||||||||||||||
| BINARY | バイナリ・データ。
SIGNED---符号付きバイナリ・データまたは符号付き10進データ。バイナリ・データおよび10進データの場合,SIGNEDが省略時の値になる。 UNSIGNED---符号なしバイナリ・データまたは符号なし10進データ。 |
||||||||||||||||
| F_FLOATING | F_FLOATING形式のデータ。 | ||||||||||||||||
| D_FLOATING | D_FLOATING形式のデータ。 | ||||||||||||||||
| G_FLOATING | G_FLOATING形式のデータ。 | ||||||||||||||||
| H_FLOATING | VAXシステムでは,H_FLOATING形式のデータになる (現在,高性能 Sort/Merge ユーティリティではサポートされていない)。 | ||||||||||||||||
| S_FLOATING | Alphaシステムでは,IEEE S_FLOATING形式のデータになる。 | ||||||||||||||||
| T_FLOATING | Alphaシステムでは,IEEE T_FLOATING形式のデータになる。 | ||||||||||||||||
| DECIMAL | 10進データ。
TRAILING_SIGN---後続符号10進データ。 10進データの場合,TRAILING_SIGNが省略時の値になる。 LEADING_SIGN---先行符号10進データ。先行符号はフィールドの最初になければならず,フィールドの残りのスペースにはゼロが埋め込まれる。 OVERPUNCHED_SIGN---オーバパンチ10進データ。 10進データの場合,OVERPUNCHED_SIGNが省略時の値になる。 SEPARATE_SIGN---分割符号10進データ。 |
||||||||||||||||
| ZONED | ゾーン10進データ (現在,高性能 Sot/Merge ユーティリティではサポートされていない)。 | ||||||||||||||||
| PACKED_DECIMAL | パック10進データ。 | ||||||||||||||||
| ソート順 | ASCENDING | ソート操作を,英数字の昇順でソートする。ASCENDINGが省略時の順序になる。 | |||||||||||||||
| DESCENDING | ソート操作を,英数字の降順でソートする。 | ||||||||||||||||
| キーの優先順位 | NUMBER: n | 複数のキーが優先順位に従ってリストされていない場合,それぞれのキーの優先順位を指定する。1〜255までの値が指定できる。 | |||||||||||||||
キー・フィールドのデータが文字データでない場合は,データ型を指定する必要があります。 Sort/Mergeユーティリティでは,次のデータ型が認識されます。
| BINARY, [SIGNED] |
| BINARY, UNSIGNED |
| CHARACTER |
| DECIMAL, LEADING_SIGN, SEPARATE_SIGN [SIGNED] |
| DECIMAL, LEADING_SIGN, [OVERPUNCHED_SIGN, SIGNED] |
| DECIMAL [,SIGNED, TRAILING_SIGN, OVERPUNCHED_SIGN] |
| DECIMAL, [TRAILING SIGN], SEPARATE_SIGN, [SIGNED] |
| DECIMAL, UNSIGNED |
| D_FLOATING |
| F_FLOATING |
| G_FLOATING |
| H_FLOATING |
| S_FLOATING, IEEE (Alpha システムのみ) |
| T_FLOATING, IEEE (Alpha システムのみ) |
| PACKED_DECIMAL |
| ZONED |
[ ] かっこ内の項目は省略時の値になるため,指定する必要はありません。
10進文字列データの場合,VAXシステムやAlphaシステムと違って, Sort/Mergeユーティリティが,入力文字列の無効な桁について報告します。 VAXシステムの場合,比較のために無効な桁(または予約オペランド)が有効な10進文字列に変換されたというメッセージが表示されます。 Alphaシステムの場合,Sort/Mergeユーティリティによって同じ変換が行われますが,メッセージが表示されません。どちらの場合も,入力ファイルのデータがそのまま出力ファイルに記述されます。 |
各レコードが (1) 部門名, (2) アカウント番号, (3) カスタマ名の 3 つのフィールドから構成される EMPLOYEE.LST ファイルを例として考えてみます。 図 11-2 にこの 3 つのフィールドを示します。
図 11-2 リストの中のレコード・フィールド

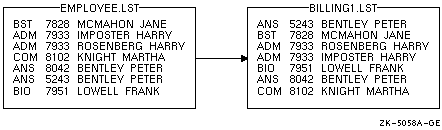
次に,EMPLOYEE.LST のレコードをソートする例を示します。
$ SORT/KEY=(POSITION:5,SIZE:4,DECIMAL) EMPLOYEE.LST BILLING1.LST |
このコマンドは,キー・フィールド (アカウント番号) が位置 5 から始まること,長さが 4 文字であること,10 進データが格納されていること,昇順 (省略時の設定) でソートすることを指定しています。ソート結果を 図 11-3
に示します。
図 11-3 キー・フィールドによるソート
$ SORT EMPLOYEE.LST BYDEPT.LST |
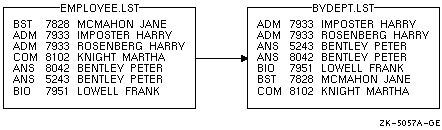
キーを指定していないので省略時の特性が使用されます。ソートの結果を 図 11-4 に示します。
図 11-4 ソート済みリスト (キー・フィールドなし)
2 つ以上のキー (255 キーが上限) でソートを行うことができます。この場合には,複数のキーを優先順位順に指定します。すなわち,最初に1 次キーを,次に 2 次キーを指定し,以下も同様になります。また別の方法として,NUMBER:n を使用して,キーの優先順位を指定する方法もあります。それぞれのキーは昇順でも降順でもかまいません。
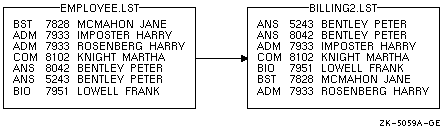
たとえば,次のコマンドは,EMPLOYEE.LST を最初にカスタマ名をキーとしてソートし,次に (同一名があれば) アカウント番号順にソートします。
$ SORT /KEY=(POSITION:10,SIZE:15,CHARACTER) - _$ /KEY=(POSITION:5,SIZE:4,DECIMAL) EMPLOYEE.LST BILLING2.LST |
ソート結果を 図 11-5 に示します。
図 11-5 複数のキー・フィールドによるソート結果
それぞれのキーは昇順でも降順でもかまいません。たとえば,次のコマンドは,最初にレコードを部門名別に降順にソートしてから,次にカスタマ名別に昇順にソートします。
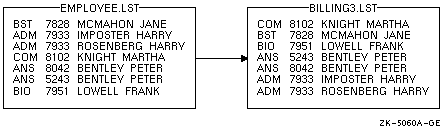
$ SORT/KEY=(POSITION:1,SIZE:3,DESCENDING) - _$ /KEY=(POSITION:10,SIZE:15) - _$ EMPLOYEE.LST BILLING3.LST |
ソート結果を 図 11-6 に示します。
図 11-6 昇順および降順キーによるソート結果
| 前へ | 次へ | 目次 | 索引 |