 |
OpenVMS User's Manual
9.4 Running Sort as a Batch Job
Batch jobs are programs or DCL command procedures that run
independently of your current session. If you are sorting large files,
consider submitting the Sort operation as a batch job because the sort
will require some time. See Chapter 16, Chapter 13, and
Chapter 14 for more information about batch jobs and command
procedures.
9.4.1 Command Procedures
Specify the SORT command in your command procedure just as you would
write it on the screen. If your default directory does not contain the
files to be sorted, explicitly set your default directory in the
command procedure or include the directory in the command file
specifications.
The following example submits the DCL command procedure SORTJOB.COM as
a batch job. The text of the command procedure is shown following the
command line:
! SORTJOB.COM
!
$ SET DEFAULT [USER.PER] ! Set default to location of input files
$ SORT/KEY=(POSITION:10,SIZE:15) EMPLOYEE.LST BYNAME.LST
$ TYPE BYNAME.LST
$ EXIT
|
9.4.2 Including Input Records
You can include the input records in the batch job by placing them
after the SORT command with one record per line. Individual sort
records can be longer than one line.
As with terminal input of records, specify the input file parameter as
SYS$INPUT. Use the /FORMAT qualifier to specify the record size in
bytes and the approximate file size in blocks. Approximately six
80-character lines equal one block.
The following example demonstrates including input records in a command
procedure:
! SORTJOB.COM
!
$ SET DEFAULT [USER.PER]
$ SORT/KEY=(POSITION:10,SIZE:15) -
SYS$INPUT-
/FORMAT=(RECORD_SIZE:24,FILE_SIZE:10) -
BYNAME.LST
$ DECK
BST 7828 MCMAHON JANE
ADM 7933 ROSENBERG HARRY
COM 8102 KNIGHT MARTHA
ANS 8042 BENTLEY PETER
BIO 7951 LOWELL FRANK
$ EOD
|
9.5 Merging Files
The MERGE command combines up to 10 (the high-performance Sort/Merge
utility supports up to 12) sorted files into one ordered output file.
You can merge input files that have the same format and have been
sorted by the same key fields.
By default, Merge checks the sequence of the records in the input files
to be sure they are in order. Specify the /NOCHECK_SEQUENCE qualifier
if you do not want Merge to check the order. If you specify the
/CHECK_SEQUENCE qualifier and a record is out of order (for example, if
you have not sorted one of the input files), Merge reports the
following error:
%SORT-W-BAD_ORDER, merge input is out of order
|
You can use the same qualifiers with the MERGE command as you use with
the SORT command with two exceptions:
- You cannot specify a process (/PROCESS) for a Merge operation.
- The /CHECK_SEQUENCE qualifier is used only for a merge operation.
In the following example, the files BYNAME1.LST and BYNAME2.LST have
already been sorted by employee name in ascending order. The command
shown merges them:
$ MERGE BYNAME1.LST,BYNAME2.LST BYNAME3.LST
|
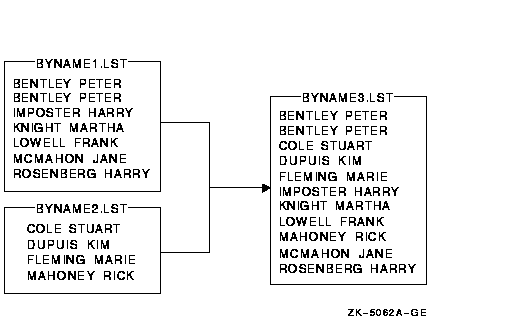
The output file BYNAME3.LST contains all the records from both files,
BYNAME1.LST and BYNAME2.LST, as shown in the following figure:
9.5.1 Sorted Files
To merge files that are sorted using a specific key, you must specify
the same key with the /KEY qualifier on the MERGE command line.
If you do not specify a key, Merge uses the default key described in
Section 9.2.
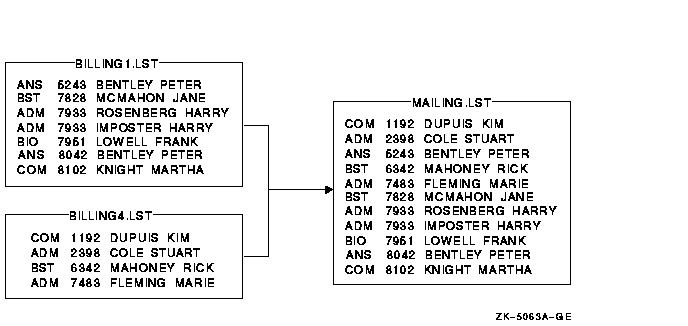
In the following example, the files BILLING1.LST and BILLING4.LST were
sorted by account number (/KEY=POSITION:5,SIZE:4,DECIMAL). To merge the
files into the output file MAILING.LST, enter the following command
line:
$ MERGE/KEY=(POSITION:5,SIZE:4,DECIMAL) -
_$ BILLING1.LST,BILLING4.LST MAILING.LST
|
The results of the merge are as follows:
If you want to merge files that you know are in sorted order, you can
prevent sequence checking by specifying the /NOCHECK_SEQUENCE qualifier.
9.5.2 Identical Key Fields
As with a Sort operation, when input files contain records with
identical key fields, Merge does not necessarily maintain the same
order in which the records had appeared in the input file. To maintain
the input order of records with identical keys, specify the /STABLE
qualifier on the MERGE command line. To retain only one copy of records
with identical keys, specify the /NODUPLICATES qualifier.
9.6 Entering Records from a Terminal
Records that you want to sort or merge do not have to be in a file. You
can enter the records directly from the terminal as you enter the SORT
or MERGE command. The following table describes the procedure:
| Step |
Task |
|
1
|
Specify SYS$INPUT as the input file on the SORT or MERGE command line.
Use the input file qualifier /FORMAT to specify the size of the
longest record, in bytes, and the approximate size of the input file,
in blocks.
|
|
2
|
Enter the input records on successive lines.
End each record by pressing Return.
|
|
3
|
Press Ctrl/Z to end the file.
|
The following example demonstrates a Sort operation in which the input
records to be sorted are entered directly from the terminal:
$ SORT/KEY=(POSITION:8,SIZE:15) -
_$ SYS$INPUT/FORMAT=(RECORD_SIZE:24,FILE_SIZE:10) BYNAME.LST
BST 7828 MCMAHON JANE
ADM 7933 ROSENBERG HARRY
COM 8102 KNIGHT MARTHA
ANS 8042 BENTLEY PETER
BIO 7951 LOWELL FRANK
|
This sequence of commands creates the output file BYNAME.LST, which
contains the sorted records.
9.7 Using a Sort/Merge Specification File
Sort/Merge allows you to maintain sort definitions and to specify more
complex sort criteria in specification files. (The
high-performance Sort/Merge utility does not support specification
files. Implementation of this feature is deferred to a future OpenVMS
Alpha release.) You can use any standard editor, or the DCL CREATE
command to create a specification file.
A Sort/Merge specification file allows you to:
- Select records to be included in the Sort/Merge operation
- Reformat the records in the output file
- Use conditional keys or data
- Specify multiple record formats
- Create or modify a collating sequence
- Reassign work files
- Store frequently used Sort/Merge operations
After you complete the specification file, specify the file name using
the /SPECIFICATION qualifier. The default file type for a specification
file is .SRT.
Each command in the specification file should start with a slash (/).
Continuation characters are not required if a command spans more than
one line.
Note
Many of the qualifiers used in the specification file are similar to
the DCL qualifiers used in the Sort/Merge command line. Note, however,
that the syntax of these qualifiers can be different. For example, the
/KEY qualifier at DCL level has different syntax than the /KEY
qualifier in the specification file. See Section 9.9.3 for a summary of
the specification file qualifiers.
|
Any DCL command qualifiers that you specify on the command line
override corresponding entries in the specification file. For example,
if you specify the /KEY qualifier in the DCL command line, Sort/Merge
ignores the /KEY clause in the specification file.
Generally, there is no required order in which you must specify the
qualifiers in a specification file. However, the order becomes
significant in the following cases:
- Sorting by more than one key field if you do not specify the
NUMBER:n key element
- Describing the output format
- Defining multiple record types
When you specify the FOLD, MODIFICATION, and IGNORE keywords with the
/COLLATING_SEQUENCE qualifier, you should specify all MODIFICATION and
IGNORE clauses before any FOLD clauses. See Section 9.9.3 for more
information about the /COLLATING_SEQUENCE qualifier.
You can include comments in your specification file by beginning each
comment line with an exclamation point (!). Unlike DCL command lines,
specification files do not need hyphens (-) to continue the line.
Examples
- This is an example of a specification file that can be used to sort
negative and positive data in ascending order:
! Specification file for sorting negative and positive data
! in ascending order
!
/FIELD=(NAME=SIGN,POS:1,SIZ:1) (1)
/FIELD=(NAME=AMT,POS:2,SIZ:4) (2)
/CONDITION=(NAME=CHECK1, (3)
TEST=(SIGN EQ "-"))
/CONDITION=(NAME=CHECK2, (4)
TEST=(SIGN EQ " "))
/INCLUDE=(CONDITION=CHECK1, (5)
KEY=(AMT,DESCENDING),
DATA=SIGN,
DATA=AMT)
/INCLUDE=(CONDITION=CHECK2, (6)
KEY=(AMT,ASCENDING),
DATA=SIGN,
DATA=AMT)
|
As you examine the specification file, note the following:
- This command line defines a field that begins
in byte 1 of the record and is 1 byte long. It assigns the field the
name SIGN.
- This command line defines a field that begins
in byte 2 of the record and is 4 bytes long. It assigns the field the
name AMT.
- This is a condition statement. If there is a
negative sign ( - ) in the SIGN byte, the CHECK1 condition is met.
- This is a condition statement. If the SIGN
byte is blank, the CHECK2 condition is met.
- If the condition CHECK1 is met, then the
record is sorted in descending order.
- If the condition CHECK2 is met, then the
record is sorted in ascending order.
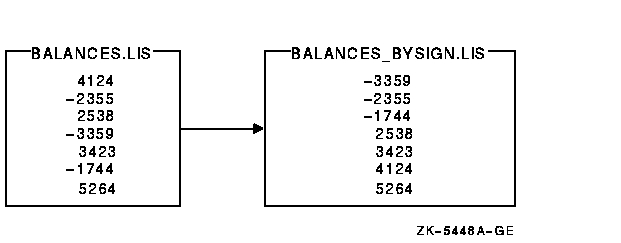
Figure 9-8 shows the result of using the specification file on
an input file named BALANCES.LIS.
Figure 9-8 Output from Using a Specification File
-
/FIELD=(NAME=RECORD_TYPE,POS:1,SIZ:1) ! Record type, 1-byte
/FIELD=(NAME=PRICE,POS:2,SIZ:8) ! Price, both files
/FIELD=(NAME=TAXES,POS:10,SIZ:5) ! Taxes, both files
/FIELD=(NAME=STYLE_A,POS:15,SIZ:10) ! Style, format A file
/FIELD=(NAME=STYLE_B,POS:20,SIZ:10) ! Style, format B file
/FIELD=(NAME=ZIP_A,POS:25,SIZ:5) ! Zip code, format A file
/FIELD=(NAME=ZIP_B,POS:15,SIZ:5) ! Zip code, format B file
/CONDITION=(NAME=FORMAT_A, ! Condition test, format A
TEST=(RECORD_TYPE EQ "A"))
/CONDITION=(NAME=FORMAT_B, ! Condition test, format B
TEST=(RECORD_TYPE EQ "B"))
/INCLUDE=(CONDITION=FORMAT_A, ! Output format, type A
KEY=ZIP_A,
DATA=PRICE,
DATA=TAXES,
DATA=STYLE_A,
DATA=ZIP_A)
/INCLUDE=(CONDITION=FORMAT_B, ! Output format, type B
KEY=ZIP_B,
DATA=PRICE,
DATA=TAXES,
DATA=STYLE_B,
DATA=ZIP_B)
|
In this example, two input files from two different branches of a
real estate agency are sorted according to the instructions specified
in a specification file. The records in the first file that begin with
an A in the first position have this format:
|A|PRICE|TAXES|STYLE|ZIP|
1 2 10 15 25
|
The records in the second file that begin with a B in the first
position and have the style and zip code fields reversed, are as
follows:
|B|PRICE|TAXES|ZIP|STYLE|
1 2 10 15 20
|
To sort these two files on the zip code field in the format of
record A, first define the fields in both records with the /FIELD
qualifiers. Then, specify a test to distinguish between the two types
of records with the /CONDITION qualifiers. Finally, the /INCLUDE
qualifiers change the record format of type B to record format of type
A on output.
Note that, if you specify either key or data fields in
an /INCLUDE qualifier, you must explicitly specify all the key and data
fields for the Sort operation in the /INCLUDE qualifier.
Also note
that records that are not type A or type B are omitted from the sort.
-
/COLLATING_SEQUENCE=(SEQUENCE=
("AN","EB","AR","PR","AY","UN","UL",
"UG","EP","CT","OV","EC","0"-"9"),
MODIFICATION=("'"="19"),
FOLD)
|
This /COLLATING_SEQUENCE qualifier specifies a user-defined
sequence that gives each month a unique value in chronological order.
For example, if you want to order a file called SEMINAR.DAT according
to the date, the file SEMINAR.DAT would be set up as follows:
16 NOV 1983 Communication Skills
05 APR 1984 Coping with Alcoholism
11 Jan '84 How to Be Assertive
12 OCT 1983 Improving Productivity
15 MAR 1984 Living with Your Teenager
08 FEB 1984 Single Parenting
07 Dec '83 Stress --- Causes and Cures
14 SEP 1983 Time Management
|
The primary key is the year field; the secondary key is the month
field. Because the month field is not numeric and you want the months
ordered chronologically, you must define your own collating sequence.
You can do this by sorting on the second two letters of each month--in
their chronological sequence--giving each month a unique key value.
The MODIFICATION option specifies that the apostrophe (') be
equated to 19, thereby allowing a comparison of '83 and 1984. The FOLD
option specifies that uppercase and lowercase letters are treated as
equal.
The output from this Sort operation appears as follows:
14 SEP 1983 Time Management
12 OCT 1983 Improving Productivity
16 NOV 1983 Communication Skills
07 Dec '83 Stress --- Causes and Cures
11 Jan '84 How to Be Assertive
08 FEB 1984 Single Parenting
15 MAR 1984 Living with Your Teenager
05 APR 1984 Coping with Alcoholism
|
See Section 9.3 for other examples of creating user-defined
collating sequences.
-
/FIELD=(NAME=AGENT,POSITION:20,SIZE:15)
/CONDITION=(NAME=AGENCY,
TEST=(AGENT EQ "Real-T Trust"
OR
AGENT EQ "Realty Trust"))
/DATA=(IF AGENCY THEN "Realty Trust" ELSE AGENT)
|
In this example, two real estate files are being sorted. One file
refers to an agency as Real-T Trust; the other refers to the same
agency as Realty Trust. The /CONDITION and /DATA qualifiers instruct
Sort to list the AGENT field in the sorted output file as Realty Trust.
-
/FIELD=(NAME=ZIP,POSITION:60,SIZE:6)
/CONDITION=(NAME=LOCATION,
TEST=(ZIP EQ "01863"))
/KEY=(IF LOCATION THEN 1
ELSE 2)
|
In this example, all the records with a zip code of 01863 will
appear at the beginning of the sorted output file. The conditional test
is on the ZIP field, defined with the /FIELD qualifier; the condition
is named LOCATION. The values 1 and 2 in this /KEY qualifier signify a
relative order for those records that satisfy the condition and those
that do not.
-
/FIELD=(NAME=ZIP,POSITION:60,SIZE:6)
/CONDITION=(NAME=LOCATION,
TEST=(ZIP EQ "01863"))
/DATA=(IF LOCATION THEN "NORTH CHELMSFORD"
ELSE "Outside district")
|
In this example, the /CONDITION qualifier tests for the 01863 zip
code. The /DATA qualifier specifies that the name of town field will be
added to the output record, depending on the test results.
-
/FIELD=(NAME=FFLOAT,POS:1,SIZ:0,F_FLOATING)
/CONDITION=(NAME=CFFLOAT,TEST=(FFLOAT GE 100))
/OMIT=(CONDITION=CFFLOAT)
|
In this example, the number 100 is considered to be an F_FLOATING
data type because field FFLOAT is defined as F_FLOATING in the /FIELD
qualifier.
-
/FIELD=(NAME=AGENT,POSITION:1,SIZE:5)
/FIELD=(NAME=ZIP,POSITION:6,SIZE:3)
/FIELD=(NAME=STYLE,POSITION:10,SIZE:5)
/FIELD=(NAME=CONDITION,POSITION:16,SIZE:9)
/FIELD=(NAME=PRICE,POSITION:26,SIZE:5)
/FIELD=(NAME=TAXES,POSITION:32,SIZE:5)
/DATA=PRICE
/DATA=" "
/DATA=TAXES
/DATA=" "
/DATA=STYLE
/DATA=" "
/DATA=ZIP
/DATA=" "
/DATA=AGENT
|
The /FIELD qualifiers define the fields in the records from an
input file that has the following format:
AGENT ZIP STYLE CONDITION PRICE TAXES
|
The /DATA qualifiers, which use the field-names defined in the
/FIELD qualifiers, reformat the records to create output records of the
following format:
PRICE TAXES STYLE ZIP AGENT
|
9.8 Optimizing a Sort or Merge Operation
There are several ways in which you can improve the efficiency of a
Sort or Merge operation, based on your sorting environment. Use the
/STATISTICS qualifier with the SORT or MERGE command to get information
about the variables in your sorting environment.
After you examine the statistics display, consider any of the
optimization options presented in the following sections.
When you enter the SORT or MERGE command with the /STATISTICS
qualifier, you see output similar to the following:
$ SORT/STATISTICS PAGEANT.LIS DOCUMENT.LIS
OpenVMS Sort/Merge Statistics
Records read: 3 (1) Input record length: 26
Records sorted: 3 Internal length: 28
Records output: 3 Output record length: 26
Working set extent: 16384 (2) Sort tree size: 42
Virtual memory: 392 Number of initial runs: 0
Direct I/O: 10 Maximum merge order: 0
Buffered I/O: 11 Number of merge passes: 0
Page faults: 158 (3) Work file allocation: 0 (4)
Elapsed time: 00:00:00.54 Elapsed CPU: 00:00:00.03 (5)
|
As you examine the fields, note the following:
- Records read
Lists the number of records
that were read during a Sort operation. See Section 9.8.2 for
information on selectively omitting records from a Sort operation.
- Working set extent
Shows how many blocks
are reserved to perform the sort operation. See Section 9.8.4 for
information on making your working set larger.
- Page faults
Shows how many times the
operating system has transferred parts of your process from physical
memory to your paging device. See Section 9.8.4 for more information on
preventing paging.
- Work file allocation
Shows how much disk
space is reserved for your work file. See Section 9.8.3 for more
information on work files.
- Elapsed CPU
Shows how much CPU time the
operating system took to process the sort operation. See Section 9.8.1
for information on saving time by choosing different methods of sorting.
9.8.1 Sorting Process
Sort defines four processes for sorting data internally: record, tag,
address and indexed. (The high-performance Sort/Merge utility supports
only the record process. Implementation of tag, address, and index
processes is deferred to a future OpenVMS Alpha release.) RECORD is the
default process. The type of process you choose affects the performance
of the Sort operation as well as storage requirements. See
Section 9.2.6 for information about the different sort processes.
Before you select a sorting process, consider the following:
- How you will use the output file
- Because record and tag sorting generate files that contain entire
sorted records, these reordered files are ready to be used.
- Both address- and index-sorted output files can be processed by a
program written in a programming language such as Pascal, Fortran,
MACRO, or C.
- Address sorting creates an output file of pointers to the records
in the input file. This list consists of binary RFAs plus a file number
when sorting multiple input files. A program accesses the records by
using the pointers.
- Index sorting creates an output file containing both RFAs and key
fields plus a file number when sorting multiple files. The format of
these key fields is the same as in the input files. If the program
needs the key field contents for a decision during future processing,
select index sorting rather than address sorting.
If you need to reorder records from one file in several ways for
different purposes, store several output files from address or index
sorting. Use the output files to access the records in the main file in
the sorted order that you want.
- The temporary storage space available for sorting
Tag sorting
uses less temporary storage space than record sorting. Because
record sorting keeps the record intact during the
sort, it uses much more work space when the files are large. Address
and index sorting use little temporary storage space.
- The type of input and output device used
Record sorting is the
only process that can accept input from cards, magnetic tape, and
disks. Output from tag and record sorting can go to any output device.
Output from address and index sorting must go to a device that accepts
binary data.
- The differences in speed
If you plan to retrieve the sorted
records at some point in the operation, record sorting is usually the
fastest process. Otherwise, address and index sorting are the fastest
processes.
|