HP OpenVMS Systems Documentation |
Guide to OpenVMS File Applications
1.7.4 The Create/FDL UtilityThe Create/FDL utility (CREATE/FDL) uses the specifications in an existing FDL file to create a new, empty data file. To invoke this utility, use the following DCL command line format:
The fdl-filespec parameter specifies the source FDL file for creating the data file. The filespec parameter gives you the option of assigning a file specification to the data file. Figure 1-14 shows how the CREATE/FDL utility creates empty data files from the specifications in an FDL file. For more information about the CREATE/FDL utility, see Chapter 4 and the OpenVMS Record Management Utilities Reference Manual. Figure 1-14 Using CREATE/FDL to Create an Empty Data File 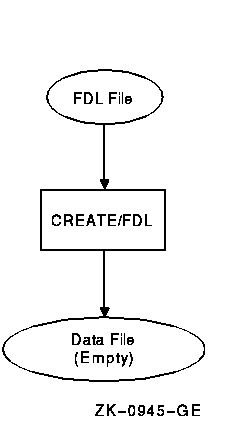
1.7.5 The Edit/FDL UtilityThe Edit/FDL utility (EDIT/FDL) creates and modifies files that contain specifications for RMS data files. The specifications are written in the file definition language, and the files are called FDL files. A completed FDL file is an ordered sequence of file attribute keywords and their associated values. By using an FDL file to specify the characteristics of a data file, you can use most of the RMS capabilities without having to access the RMS control blocks directly. While you are designing the data model, EDIT/FDL informs you of syntax errors and the effects of altering file characteristics. Using EDIT/FDL, you can experiment with attributes that are critical to the record-processing performance of the file, and you can calculate optimum file size. For example, the depth of an index is an important consideration in designing an indexed file, and bucket size is one variable that determines the number of levels. EDIT/FDL can show the effects of varying the bucket size on the index depth to help you choose the optimum bucket size. To invoke this utility, use the following DCL command line format:
The fdl-filespec parameter specifies the FDL file you want to create, modify, or optimize.
For more information about the Edit/FDL utility, see the OpenVMS Record Management Utilities Reference Manual.
To use RMS files efficiently, your application requires various process
and system resources. You may have to adjust specific resources and
quotas for the process running a file application. Before using RMS
options, you should consider their impact on process and system
resources. In some cases, you may need additional memory or disk drives
to ensure that sufficient system resources are available.
One of the most important ways to improve application performance is to allocate larger buffer areas or more buffers for an application. As described in Chapter 7, the number of buffers and the size of buckets and blocks can be fine tuned on the basis of the way the file will be accessed. For indexed files, the index structure and other factors must also be considered. When a file is opened or created, RMS maintains the buffers and control structures charged to process memory use. Memory use generally increases with the number of files to be processed at the same time. The amount of memory needed for I/O buffers can vary greatly for each file, but the amount of memory needed for control structures is fairly constant. The memory use (working set) of a process is governed by three resource limits: These values can ensure that the process has sufficient memory to perform the application with minimum paging. For a complete description of these limits, see the OpenVMS System Manager's Manual. In addition to process requirements, you may want a shared file to use global buffers to avoid needless I/O when the desired buffer is already in memory. Global buffer usage is limited by the following system parameters:
When DCL opens a process-permanent file, RMS places internal structures for the file in a special portion of P1 space called the process I/O segment. The segment size is determined by the system parameter PIOPAGES and cannot be expanded dynamically. If there is insufficient space in the process I/O segment for the internal structures, DCL generates an error message and does not open the file.
For a complete description of these parameters, see the OpenVMS System Manager's Manual.
If you anticipate asynchronous record I/O or are going to access a shared file, you should consider the following process limits:
Chapter 2
|
||||||||||||||||||||||||||||||||||||
| File Organization | |||
|---|---|---|---|
| Access Mode | Sequential | Relative | Indexed |
| Sequential | Yes | Yes | Yes |
|
Random by relative
record number |
Yes 1 | Yes | No |
|
Random by key
value |
No | No | Yes |
|
Random by record
file address |
Yes 2 | Yes | Yes |
The following sections describe the record access modes and the
capability for switching from one mode to another during program
execution.
2.1.1.1 Sequential Access
In sequential access mode, storage or retrieval begins at a designated point in the file and continues sequentially through the file. RMS begins accessing records at the start of the file, unless you either specify the starting point explicitly or establish a starting point through a previous operation.
In the sequential access mode, your program issues a series of requests to RMS to retrieve or store succeeding records in a file. Before acting on these requests, RMS checks the file organization to determine how to proceed. The following sections describe how RMS handles sequential access for each of the three file organizations.
Sequential Access to Sequential Files
In a sequential file, records are stored adjacent to one other. To retrieve a particular record within the file, your program must open the file and successively retrieve all records between the current record position and the selected record.
Figure 2-1 shows a disk surface. Each lettered section on the surface represents a record in a sequential file, beginning with record A. When the program requests sequential access to the file records, RMS interprets each request in the context of the file's organization.
Because this particular file is sequential, RMS complies with each request (except for the first request) by accessing the record immediately following the previously accessed record. For example, after RMS accesses record A, it updates the current-record position to record B in anticipation of the next request.
Figure 2-1 Sequential Access to a Sequential File
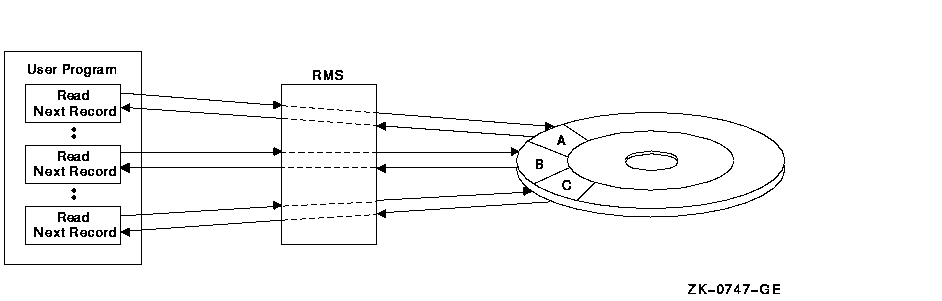
There are limitations imposed by sequential access. When accessing data sequentially, a program can access a previous record only by reopening or rewinding the file, or by switching to a random access mode. (See Chapter 8 for details.) Another limitation of sequential access is that you can add records only to the end of the file.
Sequential Access to Relative Files
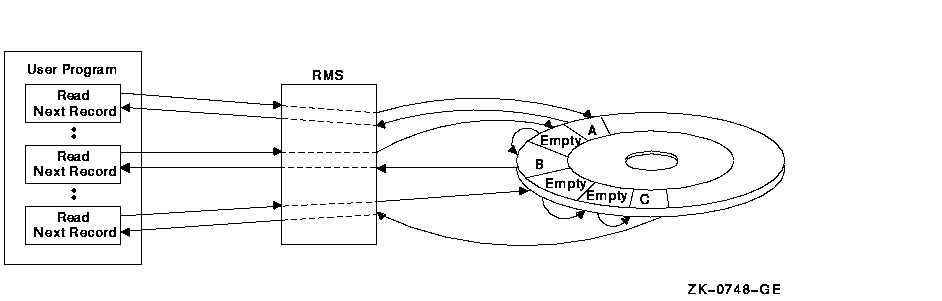
Relative files may be accessed sequentially even if some of the fixed-length file cells are empty (because records were never stored in them or because records were deleted from them). RMS ignores empty cells and sequentially searches for the next occupied cell. For example, assume a relative file contains records only in cells 1, 3, and 6. RMS responds to a sequential retrieval request by retrieving the record in cell 1, then the record in cell 3, and then the record in cell 6.
Figure 2-2 shows how RMS checks each cell, ignores an empty cell when it finds one, and then checks the next cell for a record.
Figure 2-2 Sequentially Retrieving Records in a Relative File
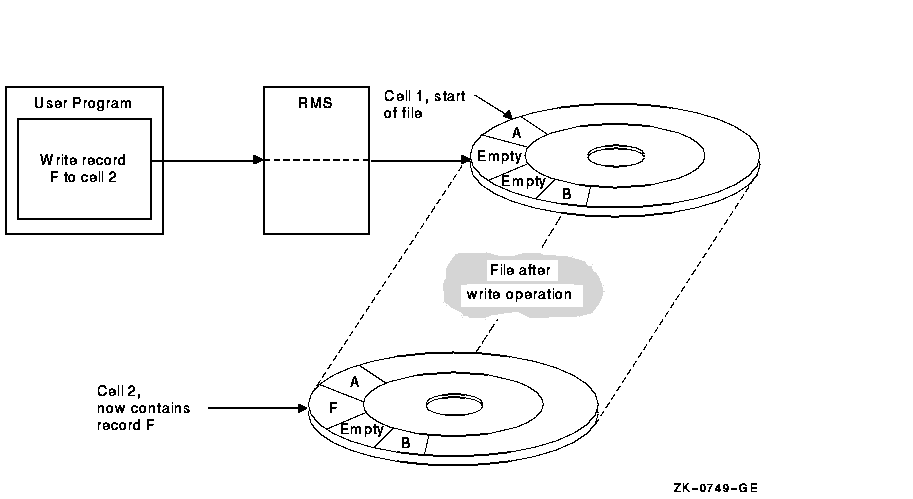
When storing records sequentially in a relative file, RMS places each new record in the cell whose relative record number is one higher than the most recently accessed cell, provided the cell is empty. If the cell is not empty, the new record cannot be stored in it. Instead, RMS returns an error status.
As Figure 2-3 shows, the program directs RMS to store record F in cell 2. Record A already occupies cell 1 but cell 2 is empty, so RMS can store the record in this cell. If this request is followed by a request to sequentially store the next record, RMS stores the record in cell 3, which is also empty. However, if the program tries to store a new record in the next cell (which already contains record B), the attempt fails.
Note that although RMS cannot store a new record in a cell that is already occupied, your program can modify the record occupying the cell.
Figure 2-3 Sequentially Storing Records in a Relative File
Sequential Access to Indexed Files
When a program sequentially accesses an indexed file, RMS uses one or more indexes to determine the order in which to process the file records. Because index entries are ordered by key values, an index represents a logical ordering of the records in the file. If you define more than one key for the file, each index associated with a key represents a different logical ordering of the records in the file. Your program can then use the sequential access mode to retrieve records in the logical order represented by any index.
To retrieve records sequentially from an indexed file, your program must first specify a key of reference (for example, primary key, first alternate key, second alternate key, and so on). For successive retrievals, RMS uses the appropriate index to retrieve records based on how the records are ordered in the index.
If RMS accesses the index in ascending sort order, it returns the record with a key value equal to or higher than the key value in the previously accessed record. Conversely, if RMS accesses records in descending order, it accesses the next record having a key value equal to or lower than the key value in the previously accessed record. In contrast to a request to retrieve data sequentially from an indexed file, a request to store data sequentially in an indexed file does not require a key of reference. Rather, RMS uses the definition of the primary key to place the record in the primary index and, where applicable, uses the definition of the appropriate alternate key to place a record pointer in the alternate index.
When a program issues a series of requests to sequentially store data,
RMS verifies that the key value in each successive record is ordered
correctly.
2.1.1.2 Random Access by Key Value or Relative Record Number
RMS supports random access for all relative files, all indexed files, and a restricted set of sequential disk files---those having fixed-length records. In random access mode, your program (not the file organization) determines the record processing order. For example, to randomly access a record in a relative file or a record in a sequential disk file having fixed-length records, your program must provide the relative record number of the cell containing the record. Similarly, to randomly access a record from an indexed file, your program must provide the appropriate key of reference and key value.
Random Access to Sequential and Relative Files
Unlike sequential access, random access follows no specific pattern. Your program may make successive requests for storing or retrieving records anywhere within the file. In Figure 2-4, the program directs RMS to retrieve the record from the sixth cell in a relative file (record C) and then requests RMS to retrieve record F, which occupies the second cell.
Figure 2-4 Random Access by Relative Record Number
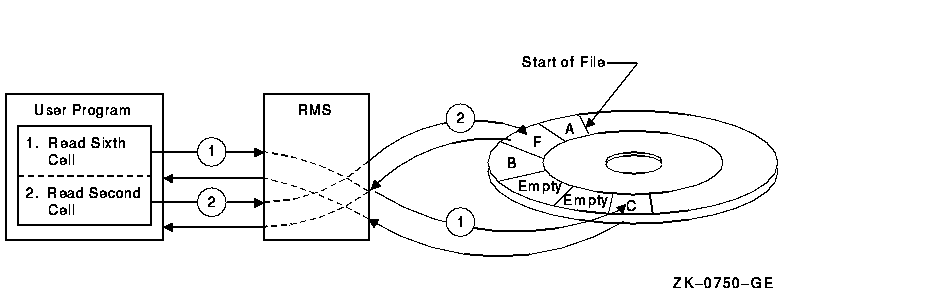
Compare Figure 2-4 with Figure 2-1 and Figure 2-2.
Random Access to Indexed Files
To randomly access a record from an indexed file, your program must specify both a key value and the index that RMS must search (for example, primary index, first alternate key index, and so on). When RMS finds a record with a matching key value, it passes the record to your program.
Your program can use several methods to randomly access a record by key:
In contrast to record retrieval requests, program requests to store records randomly in an indexed file do not require the separate specification of a key value. All keys (primary and any alternate key values) are in the record itself.
When your program opens an indexed file to store a new record, RMS uses
the key definitions in the file to find each key field in the record
and to determine the length of each key. After writing the new record
into the file, RMS uses the record's key values to make appropriate
entries in the related indexes so that the record can be accessed
subsequently using any of its key values.
2.1.1.3 Random Access by Record File Address
Every record on disk has a unique file address---the record file address (RFA)---that provides another way to randomly retrieve records in all types of file organizations.
RFA mode provides the only means of randomly accessing variable-length records in a sequential file. |
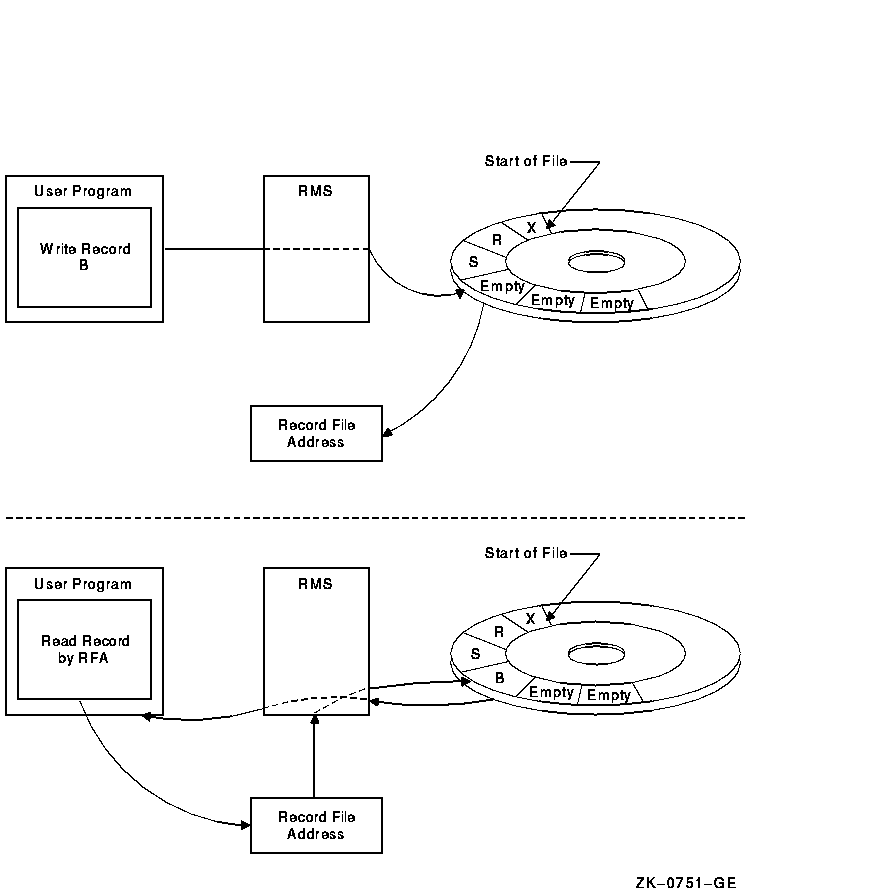
Figure 2-5 contains two illustrations. The first shows that when a record is stored, its RFA is returned to the program. The second shows that when the program wants to access the record randomly, it provides RMS with the RFA.
Figure 2-5 Random Access by Record File Address
Except for the key values that are part of the records in indexed files, RMS is less concerned with the record content than with the record's format, that is, the way the record physically appears on the recording surface of the storage medium.
RMS supports four record formats:
The fixed-length and variable-length record formats are supported for all three file organizations. The variable-length with fixed-length control field (VFC) record format is supported only for sequential and relative files.
In relative files, all records are in fixed-length cells regardless of their format. |
At the VAX MACRO level, you may specify the record format for a file
directly by using the FAB$B_RFM field in the FAB.
2.1.2.1 Fixed-Length Record Format
When you specify fixed-length record format, all file records are the same length and each record begins on an even-byte boundary. For example, when you specify 9-byte, fixed-length records, each block can hold up to 51 records (512/10) not 56 records (512/9).
When you accept the block span option (the default), the maximum fixed-length record size for sequential files is 32767 bytes. If you specify no block spanning, the maximum fixed-length record size is 512 bytes (one block). For additional information about selecting the block span option, see the OpenVMS Record Management Services Reference Manual.
The record length set at file-creation time cannot be changed. It becomes part of the information that RMS stores and maintains for the file.
For the fixed-length record format, each record occupies the same amount of space in the file, and the specified length must be able to accommodate the longest record in the file. If any record fields are not used, your program must be able to detect them and provide appropriate error processing. If you specify the block span option, records are limited to 512 bytes.
| Previous | Next | Contents | Index |