HP OpenVMS Systems Documentation |
Guide to OpenVMS File Applications
8.4.3.1 Sequential AccessYou can use sequential record access mode to retrieve successive records in an indexed file. RMS retrieves the records in successive order by the specified sort order for a key of reference. The key of reference (for example, primary key, first alternate key, second alternate key, and so forth) is established through one of the following services:
When the sequential access mode is used with the Put service to insert
records into an indexed file, successive records must be in the
specified sort order by primary key.
One of the most useful features of indexed files is that you can randomly retrieve records by the record's key value. A key value and a key of reference (such as a primary key, first alternate key, and so forth) can be specified as input to the record-processing service. RMS searches the specified index to locate the record with the specified key value. When reading records in random access by key mode, your program may specify one of four types of key matches:
Exact match requires that the record's key value precisely match the key value specified by the program's Get service. Approximate key match allows the program to select one of the following options:
The advantage of using an approximate key match is that your program can retrieve a record without knowing its precise key value. RMS uses the approximations in your program to return the record with the key value nearest the specified value. If you elect to use a generic key match, your program need provide only a specified number of leading characters in the key, for example, the first 5 bytes (characters) of a 10-byte string data-type key.
RMS uses this information to return the first record with a key value that begins with these characters and meets the specified sorting order requirement. This is useful when attempting to locate a record when only part of the key is known or for applications in which a series of records must be retrieved when only the initial portions of their key values are identical. Generic key match is available for string keys only. For example, if the program specifies the next-key option with a generic match on the three characters RAM using ascending sort order, RMS returns records with key values RAMA, RAMBO, and RAMP in that order. A record having the same key value RAM is not returned. If you specify the next-key option and descending sort order, RMS returns records with key values RAMP, RAMBO, and RAMA in that order. When a generic key match is used with various approximate key match options, the results can vary, as shown in the following example. Consider using a key value of ABB to access records having key values of ABA, ABB, and ABC, respectively.
Now observe the effects of varying the search key option and the length of the generic string.
Now consider an example of how to return all the records in a file with key values that match the generic string AB.
This procedure can be used to return all records that match a specified duplicate key for a key that allows duplicates. An alternative to checking the characters is to specify an ending key value and set the key-limit option when the record access mode is changed to sequential.
When accessing an indexed file randomly by key, the key value must
reside in the area of memory identified by the control block offset
RAB$L_KBF. When using string keys, you should specify the key length in
the location identified by control block offset RAB$B_KSZ.
Random access by RFA is supported for all disk files. Whenever RMS successfully accesses a record, an internal representation of the record's location is returned in the 6-byte RAB field RAB$W_RFA. When a program wants to retrieve the record using random access by RFA, RMS uses this internal data to retrieve the record. One way to use RFA access is to establish a record position for later sequential accesses. Consider a sequential file with variable-length records that can only be accessed randomly using RFA access. Assume the file consists of a list of transactions, sorted previously by account value. Because each account may have multiple transactions, each account value may have multiple records for it in the file. Instead of reading the entire file until it finds the first record for the desired account number, it uses a previously saved RFA value and random access by RFA to set the current-record position using a Find service at the first record of the desired account number. It can then switch to sequential record access and read all successive records for that account, until the account number changes or the end of the file is reached. Figure 8-1 shows how the file is accessed for account C. Figure 8-1 Using RFA Access to Establish Record Position 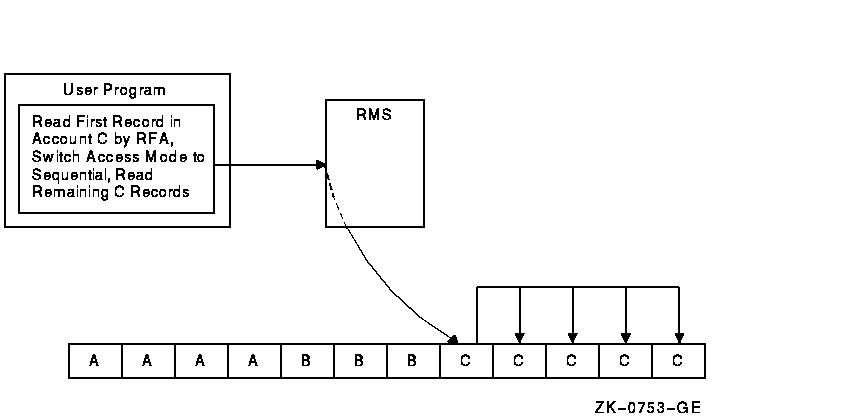
8.5 Block Input/OutputBlock input/output (I/O) lets you bypass the record-processing capabilities entirely. In this manner, your program can process a file as a virtually contiguous set of blocks. Block I/O operations provide an intermediate step between operations and direct use of the Queue I/O Request system service. Using block I/O gives your program full control of the data in the individual blocks of a file while being able to take advantage of the RMS capabilities for opening, closing, and extending a file. In block I/O, a program reads or writes one or more blocks by specifying a starting virtual block number in the file and the length of the transfer. Regardless of the organization of the file, RMS accesses the identified block or blocks. Because RMS files contain internal information meaningful only to RMS itself, Compaq does not recommend that you modify an existing file using block I/O if the file is also to be accessed by record-level operations. (Block I/O does not update any internal record information.) The block I/O facility, however, does allow you to create your own file organizations. This file structure must be maintained through specialized user-written programs and procedures; RMS cannot access these structures with its record access modes.
For more information about using block I/O, see the OpenVMS Record Management Services Reference Manual.
For each RAB connected to a FAB, RMS maintains current context information about the record stream including the current-record position and the next-record position. Furthermore, the current context is different for the various services, as shown in Table 8-3. The current record context is internal to RMS; you have no direct contact with it. However, you should know the context for each service in order to properly access records when you invoke a service.
Notes to Table 8-3:
8.6.1 Current-Record PositionFor the Update, Delete, Release, and Truncate services, the current-record position reflects the location of the target record. The current-record position also facilitates sequential processing on disk devices for a stream. The following list describes situations where the current-record position is undefined:
When the current-record position is undefined, RMS rejects the Update, Delete, Release, or Truncate service. A Get service using sequential record access mode and immediately preceded by the Find service operates on the record specified by the current-record position. If the Find service does not lock the record (for relative and indexed files) and the current record is deleted, the Get service accesses the record at the next-record position. Following successful execution of the Get service or the Find service, the current-record position is set to the target record's RFA. RMS also places the target record's address in the RFA field of the related RAB. The results are as follows:
Table 8-3 summarizes the effect that each successful record
operation has on the context of the current record.
RMS uses the next-record position for doing sequential record access. For sequential record processing, the next-record position is the location of the target record for the next Find service (Get service where appropriate) or Put service. In a relative file, the target record is the record that occupies the next nonvacant cell. The ability to look ahead significantly decreases access time for sequential processing. RMS uses its internal knowledge of file organization and structures to determine the next-record position for each record service. The Connect service initializes the next-record position to one of the following locations:
In any record access mode, the Get service establishes the next-record position as either the next record or the next record cell in the file. This is also true for the Find service in sequential access mode. The Truncate service establishes the end of the file at the current-record position (effectively deleting the record at that location and all records following it) so you need only use Put services to extend the file. Note that you can truncate only sequential files. In random access mode, the Find (or Get) service and the Put service do not affect the next-record position, unless these services are used to add a record with a primary key value or a record number that lies between the corresponding values of the current record and the next record (previous record for reverse search key options). When this occurs, the current-record position is changed to reflect the location of the added record; that is, records are added after the current record, not before the next record. In sequential access mode, the Put service initializes the next-record position to the end of the file in a sequential file. In a relative file, the Put service initializes the next-record position to the next record or record cell. For sequential accesses to an indexed file, the Put service does not define the next-record position. Regardless of access mode, the Delete, Update, Free, and Release services have no effect on the next-record position. For sequential and relative files, the Rewind service establishes the next-record position as the first record or record cell in the file, regardless of the access mode. For indexed files, the Rewind service always establishes the next-record position as the location of the first record for the current key of reference.
Any unsuccessful record operation has no effect on the next record.
Your program can handle record operations on a file in one of two ways: synchronously or asynchronously. When operating synchronously, the program issuing the record-operation request regains control only when the request is completely satisfied. Most high-level languages support synchronous operation only. In asynchronous operations, the program can regain control before the request is completely satisfied. You can specify record operations and file operations to be either synchronous or asynchronous for each record stream. For instance, when reading a record from a file synchronously, the program regains control only after the record is passed to the program. In other words, the program waits until the record returns; no other processing for this program takes place during this read-and-return cycle. On the other hand, when reading a record asynchronously, the program might be able to regain control before the record is passed to the program. The program can thus use the time normally required for the record transfer between the file and memory to perform some other computations. Another record operation cannot be started on the same stream until the previous record operation is complete. However, record operations on other streams can be initiated. Whether the program regains control before the record operation finishes depends on several factors. For example, the required record may already reside in the I/O buffer, or the operating system may schedule another process, thus possibly allowing a necessary I/O operation to be completed before the original program is rescheduled.
One factor to consider in the use of asynchronous record operations is
that you must include a separate completion routine or a wait request
in the issuing program. This routine (or wait request) is required to
determine when the record operation is completed because the results of
the operation are not available, and the next record operation for that
stream cannot be initiated until the previous operation is concluded.
To declare a synchronous operation, you must clear the RAB$V_ASY option in the RAB$L_ROP field. Normally, you do not have to clear this option because it is already cleared (by default). However, if the RAB$V_ASY option had been set previously, then you must explicitly clear it. Normally, you do not use success and error routines with synchronous operations. Instead, you test the completion status code for an error and change the flow of the program accordingly. However, if you use these routines, they are executed as asynchronous system traps (ASTs) before the service returns to your program (unless ASTs are disabled).
User-mode AST routines may be executed before the completion of a
synchronous record operation (see the OpenVMS Record Management Services Reference Manual). If an AST routine
attempts to perform operations on a record stream that is being called
from a non-AST level, it must be prepared to handle stream-activity
errors (RMS$_RSA or RMS$_BUSY).
To declare an asynchronous record operation, you must set the asynchronous (RAB$V_ASY) option in the RAB$L_ROP field. You can switch between synchronous and asynchronous operations during processing of a record stream by setting or clearing the RAB$V_ASY option on a per-operation basis. You can specify completion routines to be executed as ASTs if success or error conditions occur. Within such routines, you can issue additional operations, but they should also be asynchronous. If they are not, all other asynchronous requests currently active in your program cannot have their completion routines executed until the synchronous operation completes. If an asynchronous operation is not completed at the time of return from a call to a service, the completion status field of the RAB is 0, and a success status code of RMS$_PENDING is returned in Register 0. This status code indicates that the operation was initiated but is not yet complete.
If you issue a second record operation request for the same stream before a previous request is completed, you receive an RMS$_RSA or RMS$_BUSY error status code, indicating that the record stream is still active. This can also occur when an AST-level routine attempts to use an active record stream; the original I/O request may be synchronous or asynchronous. An additional error (RMS$_BUSY) can be encountered by attempting an operation using the same record stream (RAB) from an error or success routine when the main program is awaiting completion of the initial operation. In all cases, it is your responsibility to recognize this possibility and prevent the problem. Most problems can be prevented by using a Wait service. When the Wait service concludes, it returns control to your program. Note that the Connect operation may be performed asynchronously. If the RAB$V_ASY option is set, a Wait service should follow the Connect service to synchronize with the completion of the Connect service. Another technique is to use the Connect service synchronously and set the RAB$V_ASY option at run time, after the Connect service.
|