 |
Guidelines for OpenVMS Cluster Configurations
8.8.2 Advantages
This configuration offers the following advantages:
- All nodes have direct access to all storage.
- This configuration has a high growth capacity for processing and
storage.
- The CI is inherently dual pathed, unlike other interconnects.
8.8.3 Disadvantages
This configuration has the following disadvantage:
- Higher cost than the other configurations.
8.8.4 Key Availability Strategies
The configuration in Figure 8-5 incorporates the following
strategies, which are critical to its success:
- This configuration has no single point of failure.
- Dual porting and volume shadowing provides multiple copies of
essential disks across separate HSC or HSJ controllers.
- All nodes have shared, direct access to all storage.
- At least three nodes are used for quorum, so the OpenVMS Cluster
continues if any one node fails.
- There are no satellite dependencies.
- The uninterruptible power supply (UPS) ensures availability in case
of a power failure.
8.9 Availability in a MEMORY CHANNEL OpenVMS Cluster
Figure 8-6 shows a highly available MEMORY CHANNEL (MC) cluster
configuration. Figure 8-6 is followed by an analysis of the
configuration that includes:
- Analysis of its components
- Advantages and disadvantages
- Key availability strategies implemented
Figure 8-6 MEMORY CHANNEL Cluster
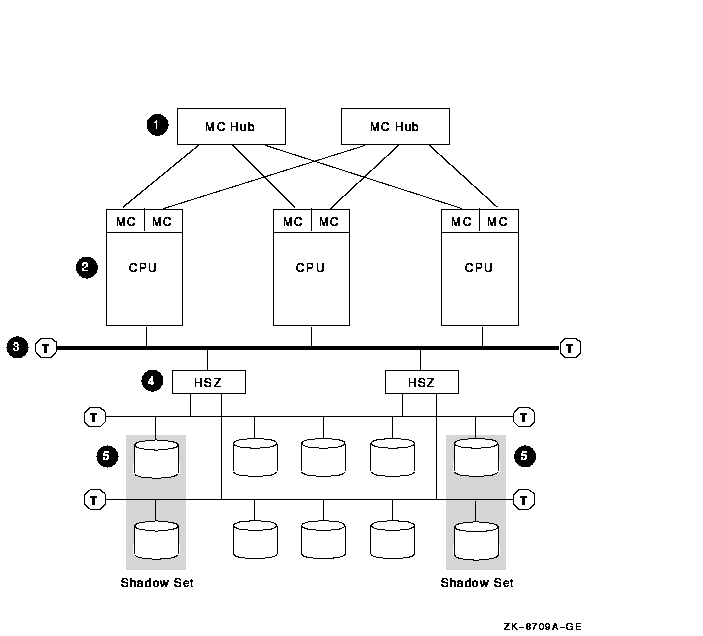
8.9.1 Components
The MEMORY CHANNEL configuration shown in Figure 8-6 has the
following components:
| Part |
Description |
|
1
|
Two MEMORY CHANNEL hubs.
Rationale: Having two hubs and multiple connections to
the nodes prevents having a single point of failure.
|
|
2
|
Three to eight MEMORY CHANNEL nodes.
Rationale: Three nodes are recommended to maintain
quorum. A MEMORY CHANNEL interconnect can support a maximum of eight
OpenVMS Alpha nodes.
Alternative: Two-node configurations require a quorum
disk to maintain quorum if a node fails.
|
|
3
|
Fast-wide differential (FWD) SCSI bus.
Rationale: Use a FWD SCSI bus to enhance data transfer
rates (20 million transfers per second) and because it supports up to
two HSZ controllers.
|
|
4
|
Two HSZ controllers.
Rationale: Two HSZ controllers ensure redundancy in
case one of the controllers fails. With two controllers, you can
connect two single-ended SCSI buses and more storage.
|
|
5
|
Essential system disks and data disks.
Rationale: Shadow essential disks and place shadow set
members on different SCSI buses to eliminate a single point of failure.
|
8.9.2 Advantages
This configuration offers the following advantages:
- All nodes have direct access to all storage.
- SCSI storage provides low-cost, commodity hardware with good
performance.
- The MEMORY CHANNEL interconnect provides high-performance,
node-to-node communication at a low price. The SCSI interconnect
complements MEMORY CHANNEL by providing low-cost, commodity storage
communication.
8.9.3 Disadvantages
This configuration has the following disadvantage:
- The fast-wide differential SCSI bus is a single point of failure.
One solution is to add a second, fast-wide differential SCSI bus so
that if one fails, the nodes can fail over to the other. To use this
functionality, the systems must be running OpenVMS Version 7.2 or
higher and have multipath support enabled.
8.9.4 Key Availability Strategies
The configuration in Figure 8-6 incorporates the following
strategies, which are critical to its success:
- Redundant MEMORY CHANNEL hubs and HSZ controllers prevent a single
point of hub or controller failure.
- Volume shadowing provides multiple copies of essential disks across
separate HSZ controllers.
- All nodes have shared, direct access to all storage.
- At least three nodes are used for quorum, so the OpenVMS Cluster
continues if any one node fails.
8.10 Availability in an OpenVMS Cluster with Satellites
Satellites are systems that do not have direct access to a system disk
and other OpenVMS Cluster storage. Satellites are usually workstations,
but they can be any OpenVMS Cluster node that is served storage by
other nodes in the cluster.
Because satellite nodes are highly dependent on server nodes for
availability, the sample configurations presented earlier in this
chapter do not include satellite nodes. However, because
satellite/server configurations provide important advantages, you may
decide to trade off some availability to include satellite nodes in
your configuration.
Figure 8-7 shows an optimal configuration for a OpenVMS Cluster
system with satellites. Figure 8-7 is followed by an analysis of the
configuration that includes:
- Analysis of its components
- Advantages and disadvantages
- Key availability strategies implemented
The base configurations in Figure 8-4 and Figure 8-5 could
replace the base configuration shown in Figure 8-7. In other words,
the FDDI and satallite segments shown in Figure 8-7 could just as
easily be attached to the configurations shown in Figure 8-4 and
Figure 8-5.
Figure 8-7 OpenVMS Cluster with Satellites
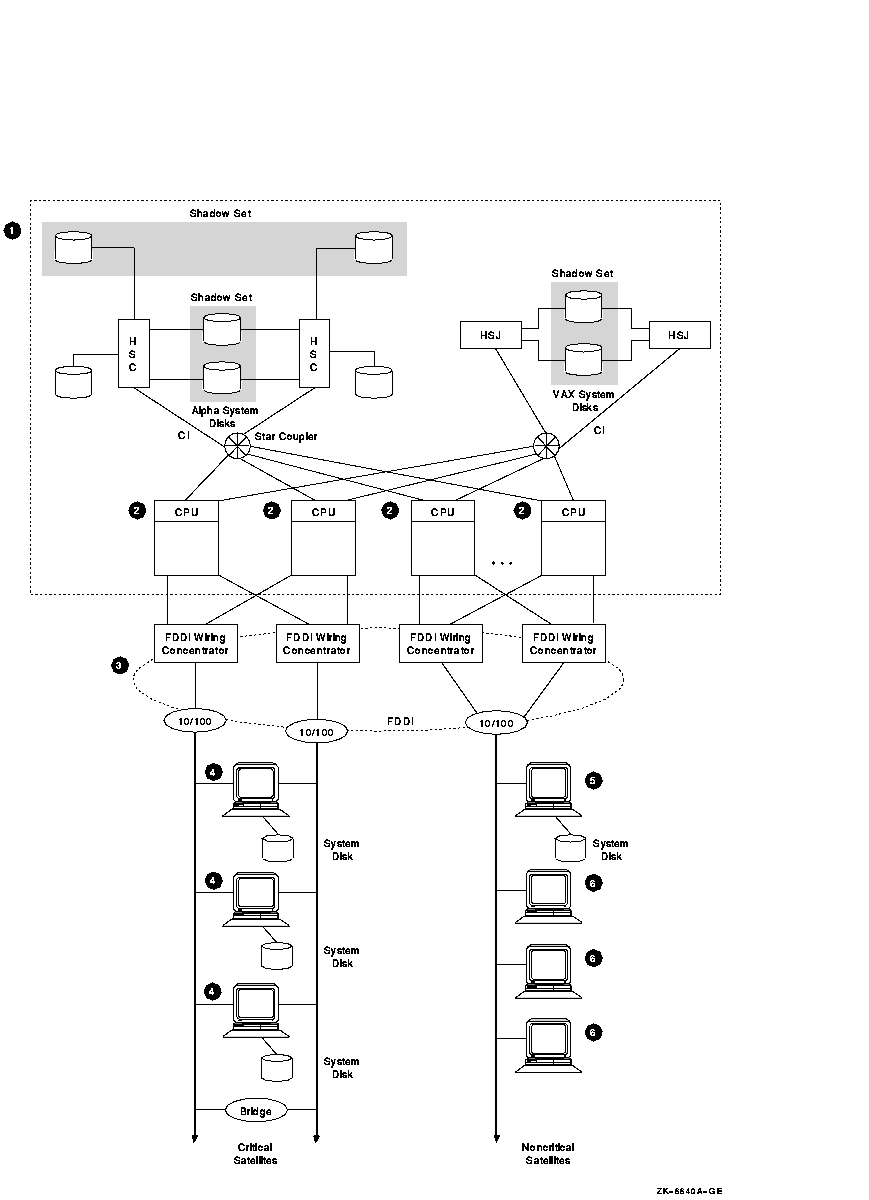
8.10.1 Components
This satellite/server configuration in Figure 8-7 has the following
components:
| Part |
Description |
|
1
|
Base configuration.
The base configuration performs server functions for satellites.
|
|
2
|
Three to 16 OpenVMS server nodes.
Rationale: At least three nodes are recommended to
maintain quorum. More than 16 nodes introduces excessive complexity.
|
|
3
|
FDDI ring between base server nodes and satellites.
Rationale: The FDDI ring has increased network
capacity over Ethernet, which is slower.
Alternative: Use two Ethernet segments instead of the
FDDI ring.
|
|
4
|
Two Ethernet segments from the FDDI ring to attach each critical
satellite with two Ethernet adapters. Each of these critical satellites
has its own system disk.
Rationale: Having their own boot disks increases the
availability of the critical satellites.
|
|
5
|
For noncritical satellites, place a boot server on the Ethernet segment.
Rationale: Noncritical satellites do not need their
own boot disks.
|
|
6
|
Limit the satellites to 15 per segment.
Rationale: More than 15 satellites on a segment may
cause I/O congestion.
|
8.10.2 Advantages
This configuration provides the following advantages:
- A large number of nodes can be served in one OpenVMS Cluster.
- You can spread a large number of nodes over a greater distance.
8.10.3 Disadvantages
This configuration has the following disadvantages:
- Satellites with single LAN adapters have a single point of failure
that causes cluster transitions if the adapter fails.
- High cost of LAN connectivity for highly available satellites.
8.10.4 Key Availability Strategies
The configuration in Figure 8-7 incorporates the following
strategies, which are critical to its success:
- This configuration has no single point of failure.
- The FDDI interconnect has sufficient bandwidth to serve satellite
nodes from the base server configuration.
- All shared storage is MSCP served from the base configuration,
which is appropriately configured to serve a large number of nodes.
8.11 Multiple-Site OpenVMS Cluster System
Multiple-site OpenVMS Cluster configurations contain nodes that are
located at geographically separated sites. Depending on the technology
used, the distances between sites can be as great as 150 miles. FDDI,
asynchronous transfer mode (ATM), and DS3 are used to connect these
separated sites to form one large cluster. Available from most common
telephone service carriers, DS3 and ATM services provide long-distance,
point-to-point communications for multiple-site clusters.
Figure 8-8 shows a typical configuration for a multiple-site OpenVMS
Cluster system. Figure 8-8 is followed by an analysis of the
configuration that includes:
- Analysis of components
- Advantages
Figure 8-8 Multiple-Site OpenVMS Cluster Configuration
Connected by WAN Link
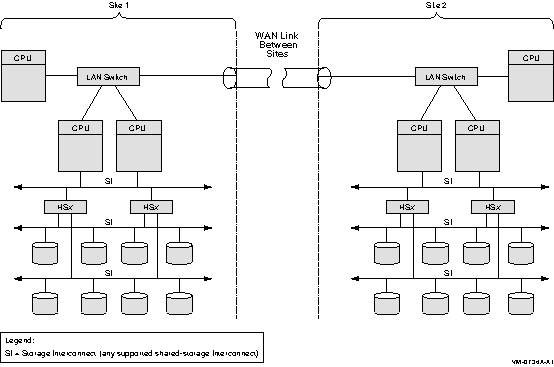
8.11.1 Components
Although Figure 8-8 does not show all possible configuration
combinations, a multiple-site OpenVMS Cluster can include:
- Two data centers with an intersite link (FDDI, ATM, or DS3)
connected to a DECconcentrator or GIGAswitch crossbar switch.
- Intersite link performance that is compatible with the applications
that are shared by the two sites.
- Up to 96 Alpha and VAX (combined total) nodes. In general, the
rules that apply to OpenVMS LAN and extended LAN (ELAN) clusters also
apply to multiple-site clusters.
Reference: For
LAN configuration guidelines, see Section 4.12.6. For ELAN configuration
guidelines, see Section 10.7.7.
8.11.2 Advantages
The benefits of a multiple-site OpenVMS Cluster system include the
following:
- A few systems can be remotely located at a secondary site and can
benefit from centralized system management and other resources at the
primary site. For example, a main office data center could be linked to
a warehouse or a small manufacturing site that could have a few local
nodes with directly attached, site-specific devices. Alternatively,
some engineering workstations could be installed in an office park
across the city from the primary business site.
- Multiple sites can readily share devices such as high-capacity
computers, tape libraries, disk archives, or phototypesetters.
- Backups can be made to archival media at any site in the cluster. A
common example would be to use disk or tape at a single site to back up
the data for all sites in the multiple-site OpenVMS Cluster. Backups of
data from remote sites can be made transparently (that is, without any
intervention required at the remote site).
- In general, a multiple-site OpenVMS Cluster provides all of the
availability advantages of a LAN OpenVMS Cluster. Additionally, by
connecting multiple, geographically separate sites, multiple-site
OpenVMS Cluster configurations can increase the availability of a
system or elements of a system in a variety of ways:
- Logical volume/data availability---Volume shadowing or redundant
arrays of independent disks (RAID) can be used to create logical
volumes with members at both sites. If one of the sites becomes
unavailable, data can remain available at the other site.
- Site failover---By adjusting the VOTES system parameter, you can
select a preferred site to continue automatically if the other site
fails or if communications with the other site are lost.
Reference: For additional information about
multiple-site clusters, see OpenVMS Cluster Systems.
8.12 Disaster-Tolerant OpenVMS Cluster Configurations
Disaster-tolerant OpenVMS Cluster configurations make use of Volume
Shadowing for OpenVMS, high-speed networks, and specialized management
software.
Disaster-tolerant OpenVMS Cluster configurations enable systems at two
different geographic sites to be combined into a single, manageable
OpenVMS Cluster system. Like the multiple-site cluster discussed in the
previous section, these physically separate data centers are connected
by FDDI or by a combination of FDDI and ATM, T3, or E3.
The OpenVMS disaster-tolerant product was formerly named the Business
Recovery Server (BRS). BRS has been subsumed by a services offering
named Disaster Tolerant Cluster Services, which is a system management
and software service package. For more information about Disaster
Tolerant Cluster Services, contact your Compaq Services representative.
Chapter 9
Configuring CI OpenVMS Clusters for Availability and Performance
There are many ways to configure a CI (cluster interconnect) OpenVMS
Cluster system. This chapter describes how to configure CI OpenVMS
Clusters to maximize both availability and performance. This is done by
presenting a series of configuration examples of increasing complexity,
followed by a comparative analysis of each example. These
configurations illustrate basic techniques that can be scaled upward to
meet the availability, I/O performance, and storage connectivity needs
of very large clusters.
9.1 CI Components
The CI is a radial bus through which OpenVMS Cluster systems
communicate with each other and with storage. The CI consists of the
following components:
- CI host adapter
- HSJ or HSC storage controller
An HSJ or HSC storage controller
is optional but generally present.
- CI cables
For each of the CI's two independent paths (called
path A and path B), there is a transmit and receive cable pair.
- Star coupler
This is a passive device that serves as a common
connection point for signals between OpenVMS nodes and HSC or HSJ
controllers that are connected to the CI. A star coupler consists of
two completely independent and electrically isolated "path
hubs." Each CI path hub is extremely reliable because it contains
only transformers carrying low-power signals.
Availability and performance can both be increased by adding
components. Components added for availability need to be configured so
that a redundant component is available to assume the work being
performed by a failed component. Components added for performance need
to be configured so that the additional components can work in parallel
with other components.
Frequently, you need to maximize both availability and performance. The
techniques presented here are intended to help achieve these dual goals.
9.2 Configuration Assumptions
The configurations shown here are based on the following assumptions:
- MSCP serving is enabled.
- Volume Shadowing for OpenVMS is installed.
- When performance is being discussed:
- CI host adapters are CIPCA or CIXCD.
Older CI adapter models
are significantly slower.
- CI storage controllers are HSJ50s.
Compared with HSJ50s, HSJ40s
are somewhat slower, and HSC models are significantly slower.
9.3 Configuration 1
Configuration 1, shown in Figure 9-1, provides no single point of
failure. Its I/O performance is limited by the bandwidth of the star
coupler.
Figure 9-1 Redundant HSJs and Host CI Adapters Connected to
Same CI (Configuration 1)
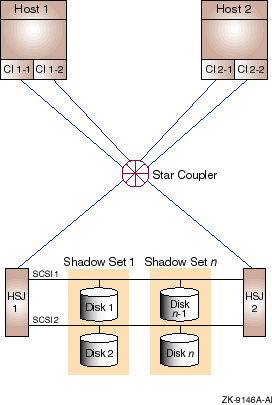
9.3.1 Components
The CI configuration shown in Figure 9-1 has the following
components:
| Part |
Description |
|
Host 1, Host 2
|
Dual CI capable OpenVMS Alpha or VAX hosts.
Rationale: Either host can fail and the system can
continue. The full performance of both hosts is available for
application use under normal conditions.
|
|
CI 1-1,CI 1-2, CI 2-1,CI 2-2
|
Dual CI adapters on each host.
Rationale: Either of a host's CI adapters can fail and
the host will retain CI connectivity to the other host and to the HSJ
storage controllers.
|
|
Star Coupler
|
One star coupler cabinet containing two independent path hubs. The star
coupler is redundantly connected to the CI host adapters and HSJ
storage controllers by a transmit/receive cable pair per path.
Rationale: Either of the path hubs or an attached
cable could fail and the other CI path would continue to provide full
CI connectivity. When both paths are available, their combined
bandwidth is usable for host-to-host and host-to-storage controller
data transfer.
|
|
HSJ 1, HSJ 2
|
Dual HSJ storage controllers in a single StorageWorks cabinet.
Rationale: Either storage controller can fail and the
other controller can assume control of all disks by means of the SCSI
buses shared between the two HSJs. When both controllers are available,
each can be assigned to serve a portion of the disks. Thus, both
controllers can contribute their I/O-per-second and bandwidth capacity
to the cluster.
|
|
SCSI 1, SCSI 2
|
Shared SCSI buses between HSJ pairs.
Rationale: Provide access to each disk on a shared
SCSI from either HSJ storage controller. This effectively dual ports
the disks on that bus.
|
|
Disk 1, Disk 2, . . . Disk
n-1, Disk
n
|
Critical disks are dual ported between HSJ pairs by shared SCSI buses.
Rationale: Either HSJ can fail, and the other HSJ will
assume control of the disks that the failed HSJ was controlling.
|
|
Shadow Set 1 through Shadow Set
n
|
Essential disks are shadowed by another disk that is connected on a
different shared SCSI.
Rationale: A disk or the SCSI bus to which it is
connected, or both, can fail, and the other shadow set member will
still be available. When both disks are available, their combined READ
I/O capacity and READ data bandwidth capacity are available to the
cluster.
|
9.3.2 Advantages
This configuration offers the following advantages:
- All nodes have direct access to storage.
- Highly expandable.
- CI is inherently dual pathed.
- No single component failure can disable the cluster.
- If a CI adapter fails, or both its paths are disabled, OpenVMS will
automatically fail over all I/O and cluster traffic to the other CI
adapter.
- Disks are dual ported between HSJ controllers; automatic disk
failover to the other controller if an HSJ fails or if an HSJ loses
both paths to a star coupler.
- Redundant storage controllers can be used to provide additional
performance by dividing disks between the two storage controllers.
Disks can be assigned to HSJ storage controllers by the OpenVMS
Prefer utility supplied in SYS$EXAMPLES, or by issuing a $QIO call with
IO$_SETPRFPATH and IO$M_FORCEPATH modifiers, or by using the HSJ
SET_PREFERRED command (less desirable; use only for this configuration).
- Critical disks are shadowed with shadow set members on different
SCSI buses.
- Read I/Os are automatically load balanced across shadow set
members for performance.
- Lowest cost.
9.3.3 Disadvantages
This configuration has the following disadvantages:
- Second CI adapter in each host is unlikely to enhance performance.
- Both HSJs have to share the bandwidth of a single CI.
- Failure of a CI path hub or path cable halves the bandwidth
available to all CI components that use the failed component.
- Physical damage to a star coupler or associated cables is likely
to disable the entire CI, rendering the cluster unusable.
- Physical damage to the StorageWorks cabinet could render the
cluster unusable.
9.3.4 Key Availability and Performance Strategies
This configuration incorporates the following strategies:
- All components are duplicated.
- Redundant storage controllers are included.
- This configuration has no single point of failure.
- Dual porting and volume shadowing provide multiple copies of
essential disks across separate HSJ controllers.
- All nodes have shared, direct access to all storage.
- A quorum disk allows other node to continue if one node fails.
(Alternatively, at least three nodes could be used.)
9.4 Configuration 2
The configuration illustrated in Figure 9-2 with redundant HSJs,
host CI adapters, and CIs provides no electrical single point of
failure. Its two star couplers provide increased I/O performance and
availability over configuration 1.
Figure 9-2 Redundant HSJs and Host CI Adapters Connected to
Redundant CIs (Configuration 2)
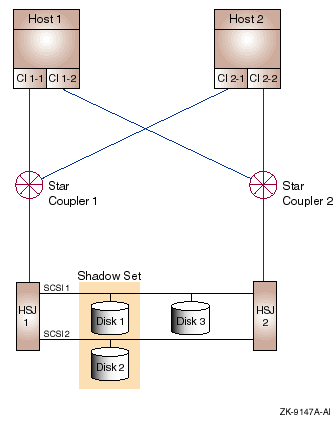
9.4.1 Components
Configuration 2 has the following components:
| Part |
Description |
|
Host 1, Host 2
|
Dual CI capable OpenVMS Alpha or VAX hosts.
Rationale: Either host can fail and the system can
continue to run. The full performance of both hosts is available for
application use under normal conditions.
|
|
CI 1-1,CI 1-2, CI 2-1, CI 2-2
|
Dual CI adapters on each host. Adapter CI 1-
n is Host 1's CI adapter connected to CI
n, and so on.
Rationale: Either of a host's CI adapters can fail,
and the host will retain CI connectivity to the other host and to the
HSJ storage controllers. Each CI adapter on a host is connected to a
different star coupler. In the absence of failures, the full data
bandwidth and I/O-per-second capacity of both CI adapters is available
to the host.
|
|
Star Coupler 1, Star Coupler 2
|
Two star couplers, each consisting of two independent path hub
sections. Each star coupler is redundantly connected to the CI host
adapters and HSJ storage controllers by a transmit/receive cable pair
per path.
Rationale: Any of the path hubs or an attached cable
could fail and the other CI path would continue to provide full
connectivity for that CI. Loss of a path affects only the bandwidth
available to the storage controller and host adapters connected to the
failed path. When all paths are available, the
combined bandwidth of both CIs is usable.
|
|
HSJ 1, HSJ 2
|
Dual HSJ storage controllers in a single StorageWorks cabinet.
Rationale: Either storage controller can fail and the
other controller can control any disks the failed controller was
handling by means of the SCSI buses shared between the two HSJs. When
both controllers are available, each can be assigned to serve a subset
of the disks. Thus, both controllers can contribute their
I/O-per-second and bandwidth capacity to the cluster.
|
|
SCSI 1, SCSI 2
|
Shared SCSI buses connected between HSJ pairs.
Rationale: Either of the shared SCSI buses could fail
and access would still be provided from the HSJ storage controllers to
each disk by means of the remaining shared SCSI bus. This effectively
dual ports the disks on that bus.
|
|
Disk 1, Disk 2, . . . Disk
n-1, Disk
n
|
Critical disks are dual ported between HSJ pairs by shared SCSI buses.
Rationale: Either HSJ can fail and the other HSJ will
assume control of the disks the failed HSJ was controlling.
|
|
Shadow Set 1 through Shadow Set
n
|
Essential disks are shadowed by another disk that is connected on a
different shared SCSI.
Rationale: A disk or the SCSI bus to which it is
connected, or both, can fail and the other shadow set member will still
be available. When both disks are available, both can provide their
READ I/O capacity and their READ data bandwidth capacity to the cluster.
|
|