HP OpenVMS Systems Documentation |
OpenVMS Version 7.3
|
| Previous | Contents | Index |
OpenVMS Alpha Version 7.3 contains software changes that improve SMP scaling. Designed for applications running on the new AlphaServer GS-series systems, many of these improvements will benefit all customer applications. The OpenVMS SMP performance improvements in Version 7.3 include the following:
The SYSMAN utility has the following new commands:
| Command | Description |
|---|---|
| CLASS_SCHEDULE ADD | Creates a new scheduling class |
| CLASS_SCHEDULE DELETE | Deletes a scheduling class |
| CLASS_SCHEDULE MODIFY | Modifies the characteristics of a scheduling class |
| CLASS_SCHEDULE RESUME | Resumes a scheduling class that has been suspended |
| CLASS_SCHEDULE SHOW | Displays the characteristics of a scheduling class |
| CLASS_SCHEDULE SUSPEND | Temporarily suspends a scheduling class |
| Command | Description |
|---|---|
| IO FIND_WWID | Detects all previously undiscovered tapes and medium changers |
| IO REPLACE_WWID | Replaces one worldwide identifier (WWID) with another |
For more information, refer to the SYSMAN section of the OpenVMS System Management Utilities Reference Manual: M--Z.
4.12 New System Parameters
This section contains definitions of system parameters that are new in
OpenVMS Version 7.3.
4.12.1 AUTO_DLIGHT_SAV
AUTO_DLIGHT_SAV is set to either 1 or 0. The default is 0.
If AUTO_DLIGHT_SAV is set to 1, OpenVMS automatically makes the change
to and from daylight saving time.
4.12.2 FAST_PATH_PORTS
FAST_PATH_PORTS is a static parameter that deactivates Fast Path for specific drivers.
FAST_PATH_PORTS is a 32-bit mask. If the value of a bit in the mask is 1, Fast Path is disabled for the driver corresponding to that bit. A value of -1 specifies that Fast Path is disabled for all drivers that the FAST_PATH_PORTS parameter controls.
Bit position zero controls Fast Path for PKQDRIVER (for parallel SCSI), and bit position one controls Fast Path for FGEDRIVER (for Fibre Channel). Currently, the default setting for FAST_PATH_PORTS is 0, which means that Fast Path is enabled for both PKQDRIVER and FGEDRIVER.
In addition, note the following:
For additional information, see FAST_PATH and IO_PREFER_CPUS.
4.12.3 GLX_SHM_REG
On Galaxy systems, GLX_SHM_REG is the number of shared memory region
structures configured into the Galaxy Management Database (GMDB). If
you set GLX_SHM_REG to 0, the default number of shared memory regions
are configured.
4.12.4 LCKMGR_CPUID (Alpha)
The LCKMGR_CPUID parameter controls the CPU that the Dedicated CPU Lock Manager runs on. This is the CPU that the LCKMGR_SERVER process will utilize if you turn this feature on with the LCKMGR_MODE system parameter.
If the specified CPU ID is either the primary CPU or a nonexistent CPU, the LCKMGR_SERVER process will utilize the lowest nonprimary CPU.
LCKMGR_CPUID is a DYNAMIC parameter.
For more information, refer to the LCKMGR_MODE system parameter.
4.12.5 LCKMGR_MODE (Alpha)
The LCKMGR_MODE parameter controls usage of the Dedicated CPU Lock Manager. Setting LCKMGR_MODE to a number greater than zero (0) indicates the number of CPUs that must be active before the Dedicated CPU Lock Manager is turned on.
The Dedicated CPU Lock Manager performs all locking operations on a single dedicated CPU. This can improve system performance on large SMP systems with high MP_Synch associated with the lock manager.
For more information about usage of the Dedicated CPU Lock Manager, see the OpenVMS Performance Management manual.
Specify one of the following:
| Value | Description |
|---|---|
| 0 | Indicates the Dedicated CPU Lock Manager is off. (The default.) |
| >0 | Indicates the number of CPUs that must be active before the Dedicated CPU Lock Manager is turned on. |
LCKMGR_MODE is a DYNAMIC parameter.
4.12.6 NPAGECALC
NPAGECALC controls whether the system automatically calculates the initial size for nonpaged dynamic memory.
Compaq sets the default value of NPAGECALC to 1 only during the initial boot after an installation or upgrade. When the value of NPAGECALC is 1, the system calculates an initial value for the NPAGEVIR and NPAGEDYN system parameters. This calculated value is based on the amount of physical memory in the system.
NPAGECALC's calculations do not reduce the values of NPAGEVIR and NPAGEDYN from the values you see or set at the SYSBOOT prompt. However, NPAGECALC's calculation might increase these values.
AUTOGEN sets NPAGECALC to 0. NPAGECALC should always remain 0 after
AUTOGEN has determined more refined values for the NPAGEDYN and
NPAGEVIR system parameters.
4.12.7 NPAGERAD (Alpha)
NPAGERAD specifies the total number of bytes of nonpaged pool that will be allocated for Resource Affinity Domains (RADs) other than the base RAD. For platforms that have no RADs, NPAGERAD is ignored. Notice that NPAGEDYN specifies the total amount of nonpaged pool for all RADs.
Also notice that the OpenVMS system might round the specified values higher to an even number of pages for each RAD, which prevents the base RAD from having too little nonpaged pool. For example, if the hardware is an AlphaServer GS160 with 4 RADs:
NPAGEDYN = 6291456 bytes NPAGERAD = 2097152 bytes |
In this case, the OpenVMS system allocates a total of approximately
6,291,456 bytes of nonpaged pool. Of this amount, the system divides
2,097,152 bytes among the RADs that are not the base RAD. The system
then assigns the remaining 4,194,304 bytes to the base RAD.1
4.12.8 RAD_SUPPORT (Alpha)
RAD_SUPPORT enables RAD-aware code to be executed on systems that support Resource Affinity Domains (RADs); for example, AlphaServer GS160 systems.
A RAD is a set of hardware components (CPUs, memory, and I/O) with
common access characteristics. For more information about using OpenVMS
RAD features, refer to the OpenVMS Alpha Partitioning and Galaxy Guide.
4.12.9 SHADOW_MAX_UNIT
SHADOW_MAX_UNIT specifies the maximum number of shadow sets that can exist on a node. The setting must be equal to or greater than the number of shadow sets you plan to have on a system. Dismounted shadow sets, unused shadow sets, and shadow sets with no write bitmaps allocated to them are included in the total.
This system parameter is not dynamic; that is, a reboot is required when you change the setting.
The default setting on OpenVMS Alpha systems is 500; on OpenVMS VAX systems, the default is 100. The minimum value is 10, and the maximum value is 10,000.
Note that this parameter does not affect the naming of shadow sets. For
example, with the default value of 100, a device name such as DSA999 is
still valid.
4.12.10 VCC_MAX_IO_SIZE (Alpha)
The dynamic system parameter VCC_MAX_IO_SIZE controls the maximum size of I/O that can be cached by the Extended File Cache. It specifies the size in blocks. By default, the size is 127 blocks.
Changing the value of VCC_MAX_IO_SIZE affects reads and writes to volumes currently mounted on the local node, as well as reads and writes to volumes mounted in the future.
If VCC_MAX_IO_SIZE is 0, the Extended File Cache on the local node cannot cache any reads or writes. However, the system is not prevented from reserving memory for the Extended File Cache during startup if a VCC$MIN_CACHE_SIZE entry is in the reserved memory registry.
VCC_MAX_IO_SIZE is a DYNAMIC parameter.
4.12.11 VCC_READAHEAD (Alpha)
The dynamic system parameter VCC_READAHEAD controls whether the Extended File Cache can use read-ahead caching. Read-ahead caching is a technique that improves the performance of applications that read data sequentially.
By default VCC_READAHEAD is 1, which means that the Extended File Cache can use read-ahead caching. The Extended File Cache detects when a file is being read sequentially in equal-sized I/Os, and fetches data ahead of the current read, so that the next read instruction can be satisfied from cache.
To stop the Extended File Cache from using read-ahead caching, set VCC_READAHEAD to 0.
Changing the value of VCC_READAHEAD affects volumes currently mounted on the local node, as well as volumes mounted in the future.
Readahead I/Os are totally asynchronous from user I/Os and only take place if sufficient system resources are available.
VCC_READAHEAD is a DYNAMIC parameter.
4.12.12 WBM_MSG_INT
WBM_MSG_INT is one of three system parameters that are available for managing the update traffic between a master write bitmap and its corresponding local write bitmaps in an OpenVMS Cluster system. (Write bitmaps are used by the volume shadowing software for minicopy operations.) The others are WBM_MSG_UPPER and WBM_MSG_LOWER. These parameters set the interval at which the frequency of sending messages is tested and also set an upper and lower threshold that determine whether the messages are grouped into one SCS message or are sent one by one.
In single-message mode, WBM_MSG_INT is the time interval in milliseconds between assessments of the most suitable write bitmap message mode. In single-message mode, the writes issued by each remote node are, by default, sent one by one in individual SCS messages to the node with the master write bitmap. If the writes sent by a remote node reach an upper threshold of messages during a specified interval, single-message mode switches to buffered-message mode.
In buffered-message mode, WBM_MSG_INT is the maximum time a message waits before it is sent. In buffered-message mode, the messages are collected for a specified interval and then sent in one SCS message. During periods of increased message traffic, grouping multiple messages to send in one SCS message to the master write bitmap is generally more efficient than sending each message separately.
The minimum value of WBM_MSG_INT is 10 milliseconds. The maximum value is -1, which corresponds to the maximum positive value that a longword can represent. The default is 10 milliseconds.
WBM_MSG_INT is a DYNAMIC parameter.
4.12.13 WBM_MSG_LOWER
WBM_MSG_LOWER is one of three system parameters that are available for managing the update traffic between a master write bitmap and its corresponding local write bitmaps in an OpenVMS Cluster system. (Write bitmaps are used by the volume shadowing software for minicopy operations.) The others are WBM_MSG_INT and WBM_MSG_UPPER. These parameters set the interval at which the frequency of sending messages is tested and also set an upper and lower threshold that determine whether the messages are grouped into one SCS message or are sent one by one.
WBM_MSG_LOWER is the lower threshold for the number of messages sent during the test interval that initiates single-message mode. In single-message mode, the writes issued by each remote node are, by default, sent one by one in individual SCS messages to the node with the master write bitmap. If the writes sent by a remote node reach an upper threshold of messages during a specified interval, single-message mode switches to buffered-message mode.
The minimum value of WBM_MSG_LOWER is 0 messages per interval. The maximum value is -1, which corresponds to the maximum positive value that a longword can represent. The default is 10.
WBM_MSG_LOWER is a DYNAMIC parameter.
4.12.14 WBM_MSG_UPPER
WBM_MSG_UPPER is one of three system parameters that are available for managing the update traffic between a master write bitmap and its corresponding local write bitmaps in an OpenVMS Cluster system. (Write bitmaps are used by the volume shadowing software for minicopy operations.) The others are WBM_MSG_INT and WBM_MSG_LOWER. These parameters set the interval at which the frequency of sending messages is tested and also set an upper and lower threshold that determine whether the messages are grouped into one SCS message or are sent one by one.
WBM_MSG_UPPER is the upper threshold for the number of messages sent during the test interval that initiates buffered-message mode. In buffered-message mode, the messages are collected for a specified interval and then sent in one SCS message.
The minimum value of WBM_MSG_UPPER is 0 messages per interval. The maximum value is -1, which corresponds to the maximum positive value that a longword can represent. The default is 100.
WBM_MSG_UPPER is a DYNAMIC parameter.
4.12.15 WBM_OPCOM_LVL
WBM_OPCOM_LVL controls whether write bitmap system messages are sent to the operator console. (Write bitmaps are used by the volume shadowing software for minicopy operations.) Possible values are shown in the following table:
| Value | Description |
|---|---|
| 0 | Messages are turned off. |
| 1 | The default; messages are provided when write bitmaps are started, deleted, and renamed, and when the SCS message mode (buffered or single) changes. |
| 2 | All messages for a setting of 1 are provided plus many more. |
WBM_OPCOM_LVL is a DYNAMIC parameter.
1 The system actually rounds up to an even number of pages on each RAD. In addition, the base RAD is never assigned a value less than the smaller of the value of NPAGEDYN and 4 megabytes. |
4.13 Volume Shadowing for OpenVMS
Volume Shadowing for OpenVMS introduces three new features, the
minicopy operation enabled by write bitmaps, new qualifiers for
disaster tolerant support for OpenVMS Cluster systems, and a new
/SHADOW qualifier to the INITIALIZE command. These features are
described in this section.
4.13.1 Minicopy in Compaq Volume Shadowing for OpenVMS (Alpha)
The new minicopy feature of Compaq Volume Shadowing for OpenVMS and its enabling technology, write bitmap, are fully implemented on OpenVMS Alpha systems. OpenVMS VAX nodes can write to shadow sets that use this feature but they can neither create master write bitmaps nor manage them with DCL commands.
The minicopy operation is a streamlined copy operation. Minicopy is designed to be used in place of a copy operation when you return a shadow set member to the shadow set. When a member has been removed from a shadow set, a write bitmap tracks the changes that are made to the shadow set in its absence, as shown in Figure 4-1.
Figure 4-1 Application Writes to a Write Bitmap
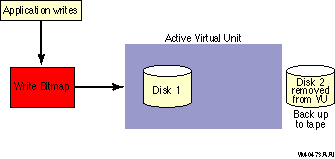
When the member is returned to the shadow set, the write bitmap is used to direct the minicopy operation, as shown in Figure 4-2. While the minicopy operation is taking place, the application continues to read and write to the shadow set.
Figure 4-2 Member Returned to the Shadow Set (Virtual Unit)
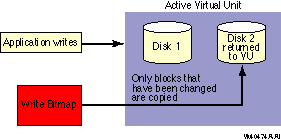
Thus, minicopy can significantly decrease the time it takes to return the member to membership in the shadow set and can significantly increase the availability of the shadow sets that use this feature.
Typically, a shadow set member is removed from a shadow set to back up the data on the disk. Before the introduction of the minicopy feature, Compaq required that the virtual unit (the shadow set) be dismounted to back up the data from one of the members. This requirement has been removed, provided that the guidelines for removing a shadow set member for backup purposes, as documented in Volume Shadowing for OpenVMS, are followed.
For more information about this new feature, including additional
memory requirements for this version of Compaq Volume Shadowing for
OpenVMS, refer to Volume Shadowing for OpenVMS.
4.13.2 New Volume Shadowing Features for Multiple-Site OpenVMS Cluster Systems
OpenVMS Version 7.3 introduces new command qualifiers for the DCL commands DISMOUNT and SET for use with Volume Shadowing for OpenVMS. These new command qualifiers provide disaster tolerant support for multiple-site OpenVMS Cluster systems. Designed primarily for multiple-site clusters that use Fibre Channel for a site-to-site storage interconnect, they can be used in other configurations as well. For more information about using these new qualifiers in a multiple-site OpenVMS Cluster system, see the white paper Using Fibre Channel in a Disaster-Tolerant OpenVMS Cluster System, which is posted on the OpenVMS Fibre Channel web site at:
http://www.openvms.compaq.com/openvms/fibre/ |
The new command qualifiers are described in this section. Section 4.13.2.1 describes how to use these new qualifiers.
One new qualifier to the DISMOUNT command, DISMOUNT/FORCE_REMOVAL ddcu:, is provided. If connectivity to a device has been lost and the shadow set is in mount verification, /FORCE_REMOVAL ddcu: can be used to immediately expell a named shadow set member (ddcu:) from the shadow set. If you omit this qualifier, the device is not dismounted until mount verification completes. Note that this qualifier cannot be used in conjunction with the /POLICY=MINICOPY (=OPTIONAL) qualifier.
The device specified must be a member of a shadow set that is mounted on the node where the command is issued.
The following new qualifiers to the SET DEVICE command have been created for managing shadow set members located at multiple sites:
| Previous | Next | Contents | Index |