HP OpenVMS Systems Documentation |
    
Common Desktop Environment: Internationalization Programmer's Guide 1 Introduction to InternationalizationContents of Chapter: Internationalization is the designing of computer systems and applications for users around the world. Such users have different languages and may have different requirements for the functionality and user interface of the systems they operate. In spite of these differences, users want to be able to implement enterprise-wide applications that run at their sites worldwide. These applications must be able to interoperate across country boundaries, run on a variety of hardware configurations from multiple vendors, and be localized to meet local users' needs. This open, distributed computing environment is the reasoning behind common open software environments. The internationalization technology identified within this specification provides these benefits to a global market. Overview of InternationalizationMultiple environments may exist within a common open system for support of different national languages. Each of these national environments is called a locale, which considers the language, its characters, fonts, and the customs used to input and format data. The Common Desktop Environment is fully internationalized such that any application can run using any locale installed in the system.A locale defines the behavior of a program at run time according to the language and cultural conventions of a user's geographical area. Throughout the system, locales affect the following:
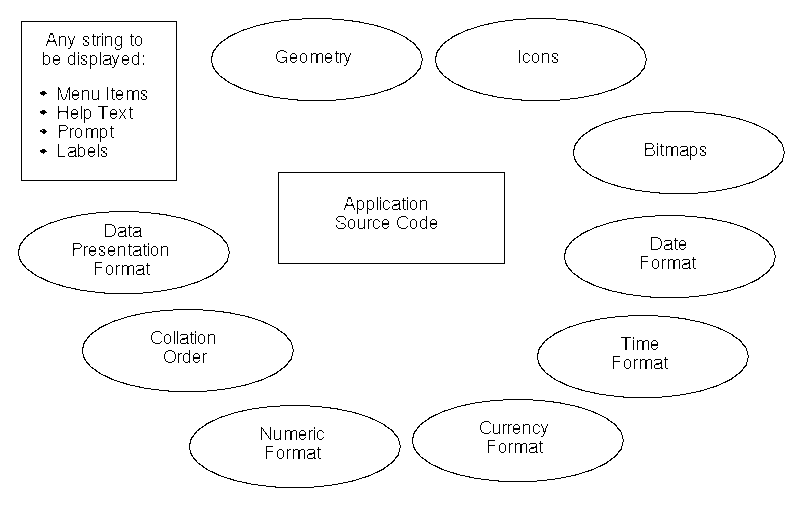
Figure 1-1 shows the kinds of information that should be external to an application to simplify internationalization. Figure 1-1 Information external to the application
By keeping the language- and culture-dependent information separate from the application source code, the application does not need to be rewritten or recompiled to be marketed in different countries. Instead, the only requirement is for the external information to be localized to accommodate local language and customs. An internationalized application is also adaptable to the requirements of different native languages, local customs, and character-string encodings. The process of adapting the operation to a particular native language, local custom, or string encoding is called localization. A goal of internationalization is to permit localization without program source modifications or recompilation. For a quick overview of internationalization, refer to X/Open CAE Specification System Interface Definition, Issue 4, X/Open Company Ltd., 1992, ISBN: 1-872630-46-4. Current State of InternationalizationPreviously, the industry supplied many variants of internationalization from proprietary functions to the new set of standard functions published by X/Open. Also, there have been different levels of enabling, such as simple ASCII support, Latin/European support, Asian multibyte support, and Arabic/Hebrew bidirectional support.The interfaces defined within the X/Open specification are capable of supporting a large set of languages and territories, including:
Internationalization StandardsThrough the work of many companies, the functionality of the internationalization application program interface has been standardized over time to include additional requirements and languages, particularly those of East Asia. This work has been centered primarily in the Portable Operating System Interface for Computer Environments (POSIX) and X/Open specifications. The original X/Open specification was published in the second edition of the X/Open Portability Guide (XPG2) and was based on the Native Language Support product released by Hewlett-Packard. The latest published X/Open internationalization standard is referred to as XPG4.It is important that each layer within the desktop use the proper set of standards interfaces defined for internationalization to ensure end users get a consistent, localized interface. The definition of a locale and the common open set of locale-dependent functions are based on the following specifications:
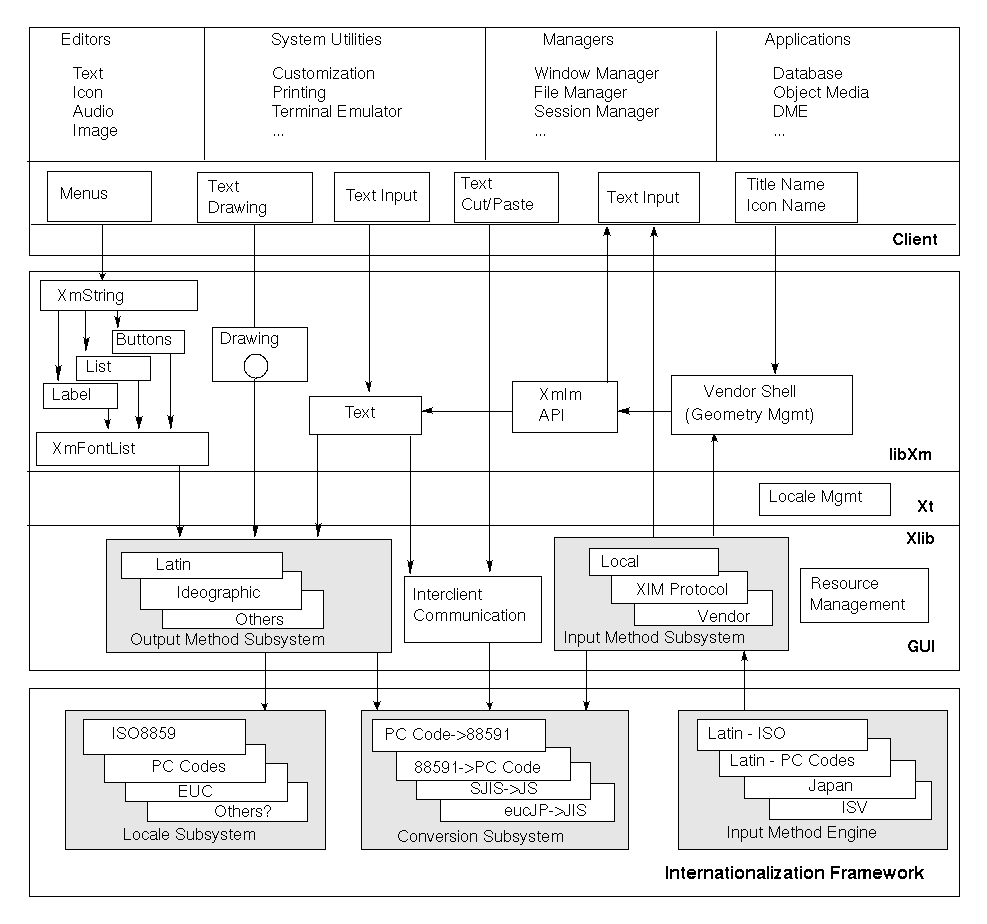
Common Internationalization SystemFigure 1-2 shows a view of how internationalization is pervasive across a specific single-host system. The goal is that the applications (clients) are built to be shipped worldwide for the set of locales supported in the underlying system. Using standard interfaces improves access to global markets and minimizes the amount of localization work needed by application developers. In addition, country representatives can be ensured of consistent localization within systems adhering to the principles of the desktop.Figure 1-2 Common internationalized system
LocalesMost single-display clients operate in a single locale that is determined at run time from the setting of the environment variable, which is usually$LANG or the xnlLanguage resource. Locale environment variables, such as LC_ALL, LC_CTYPE, and LANG, can be used to control the environment. See "Xt Locale Management" for more information.
The
Programs that are enabled for internationalization are expected to call the
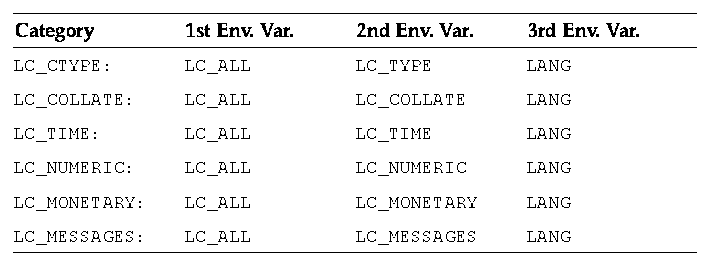
setlocale() function use the $LC_* and $LANG environment variables to determine locale settings. Specifically, setlocale (LC_ALL, "") specifies that the locale should be checked and taken from environment variables in the order shown in Table 1-1 for the various locale categories.
Table 1-1 Locale Categories
The toolkit already defines a standard command-line option ( Fonts, Font Sets, and Font ListsAll X clients use fonts for drawing text. The basic object used in drawing text is XFontStruct, which identifies the font that contains the images to be drawn.
The desktop already supports fonts by way of the
A font set (for example, an While fonts are identified by their XLFD name, font sets are identified by a list of XLFD names. The list can consist of one or more XLFD names with the exception that only the base characteristics are significant; the encoding of the desired fonts is determined from the locale. Any charsets specified in the XLFD base name list are ignored and users need only concentrate on specifying the base characteristics, such as point size, style, and weight. A font set is said to be locale-sensitive and is used to draw text that is encoded in the code set of the locale. Internationalized applications should use font sets instead of font structs to render text data.
A font list is a libXm Toolkit object that is a collection of one or more font list entries. Font sets can be specified within a font list. Each font list entry designates either a font or a font set and is tagged with a name. If there is no tag in a font list entry, a default tag ( The user is generally asked to specify either a font list (which may contain either a font or font set) or a font set. In an internationalized environment, the user must be able to specify fonts that are independent of the code set because the specification can be used under various locales with different code sets than the character set (charset) of the font. Therefore, it is recommended that all font lists be specified with a font set. Font SpecificationThe font specification can be either an X Logical Function Description (XLFD) name or an alias for the XLFD name. For example, the following are valid font specifications for a 14-point font:
OR
Font Set SpecificationThe font set specification is a list of names (XLFD names or their aliases) and is sometimes called a base name list. All names are separated by commas, with any blank spaces before or after the comma being ignored. Pattern-matching (wildcard) characters can be specified to help shorten XLFD names.Remember that a font set specification is determined by the locale that is running. For example, the ja_JP Japanese locale defines three fonts (character sets) necessary to display all of its characters; the following identifies the set of Gothic fonts needed.
Font List SpecificationA font list specification can consist of one or more entries, each of which can be either a font specification or a font set specification.
Each entry can be tagged with a name that is used when drawing a compound string. The tags are application-defined and are usually names representing the expected style of font; for example,
A font tag is identified when it is prefixed with an = (equal sign); for example,
A font set tag is identified when it is prefixed with a : (colon); for example, Example Font List SpecificationFor the Latin 1 locales, enter:
Base Font Name List SpecificationThe base font name list is a list of base font names associated with a font set as defined by the locale. The base font names are in a comma-separated list and are assumed to be characters from the portable character set; otherwise, the result is undefined. Blank space immediately on either side of a separating comma is ignored.Use of XLFD font names permits international applications to obtain the fonts needed for a variety of locales from a single locale-independent base font name. The single base font name specifies a family of fonts whose members are encoded in the various charsets needed by the locales of interest. An XLFD base font name can explicitly name the font's charset needed for the locale. This enables the user to specify an exact font for use with a charset required by a locale, fully controlling the font selection. If a base font name is not an XLFD name, an attempt is made to obtain an XLFD name from the font properties for the font. The following algorithm is used to select the fonts that are used to display text with font sets. For each charset required by the locale, the base font name list is searched for the first of the following cases that names a set of fonts that exist at the server.
You can supply a base font name list that omits the charsets, which selects fonts for each required code set, as shown in the following example:
Alternatively, the user can supply a single base font name that selects from all available fonts that meet certain minimum XLFD property requirements, as shown in the following example:
Text DrawingThe desktop provides various functions for rendering localized text, including simple text, compound strings, and some widgets. These include functions within the Xlib and Motif libraries.Input MethodsThe Common Desktop Environment provides the ability to enter localized input for an internationalized application that is using the Xm Toolkit. Specifically, theXmText[Field] widgets are enabled to interface with input methods provided by each locale. In addition, the dtterm client is enabled to use input methods.
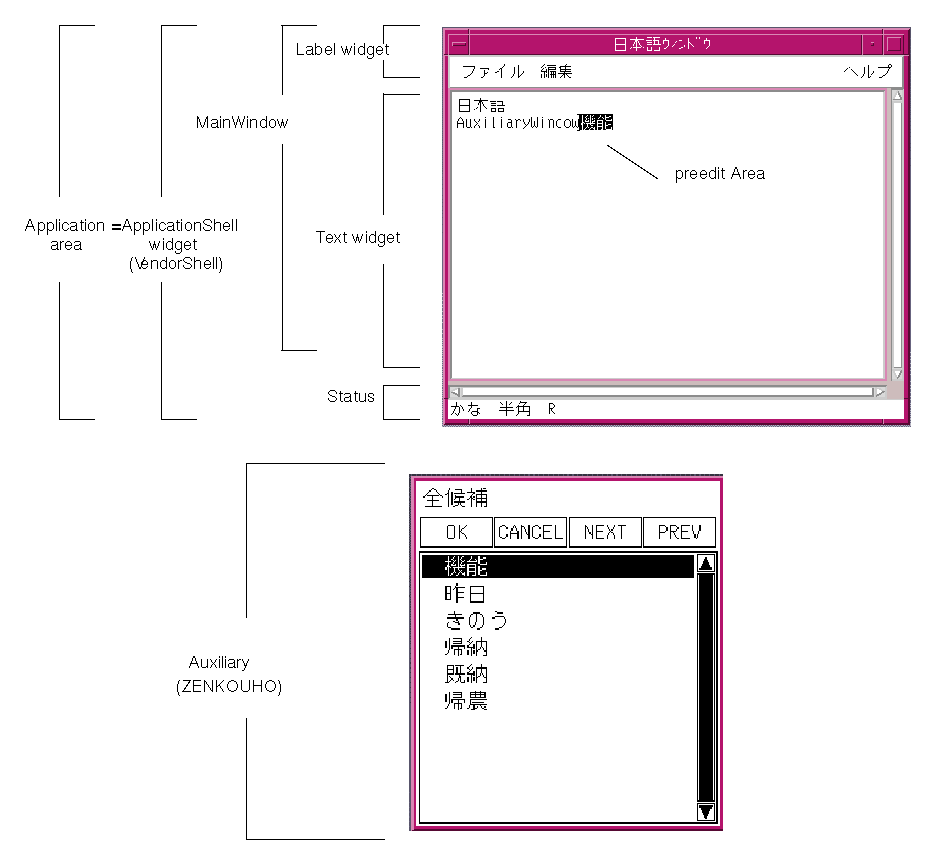
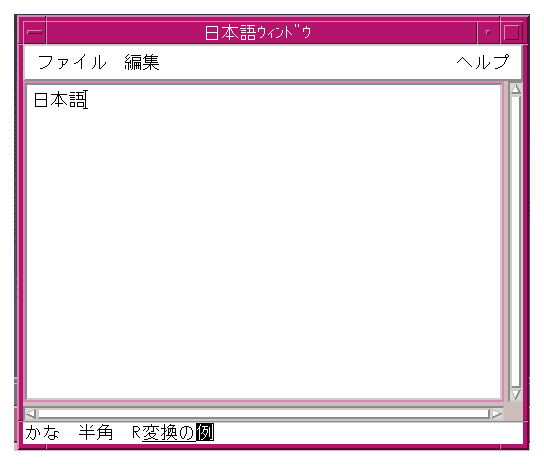
By default, each internationalization client that uses the libXm Toolkit uses the input method associated with a locale specified by the user. The The user interface of the input method consists of several elements. The need for these areas is dependent on the input method being used. They are usually needed by input methods that require complex input processing and dialogs. See Figure 1-3 for an illustration of these areas. Figure 1-3 Example of VendorShell widget with auxiliary (Japanese)
Preedit AreaA preedit area is used to display the string being preedited. The input method supports four modes of preediting: OffTheSpot, OverTheSpot (default), Root, and None.
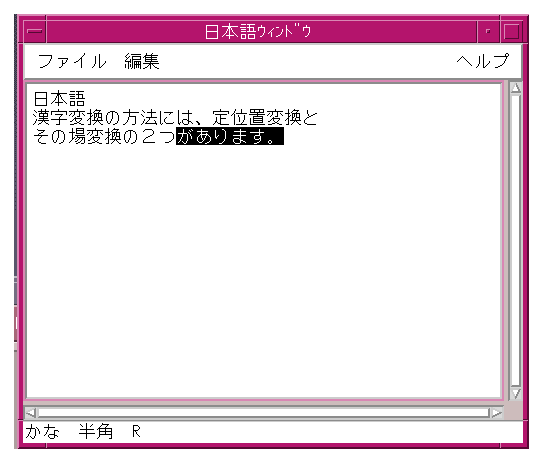
Note: A string that has been committed cannot be reconverted. The status of the string is moved from the preedit area to the location where the user is entering characters.. OffTheSpotIn OffTheSpot mode preediting using an input method, the location of preediting is fixed at just below the MainWindow area and on the right side of the status area as shown in Figure 1-4. A Japanese input method is used for the example.Figure 1-4 Example of OffTheSpot preediting with the VendorShell widget (Japanese)
In the system environment, when preediting using an input method, the preedit string being preedited may be highlighted in some form depending on the input method.
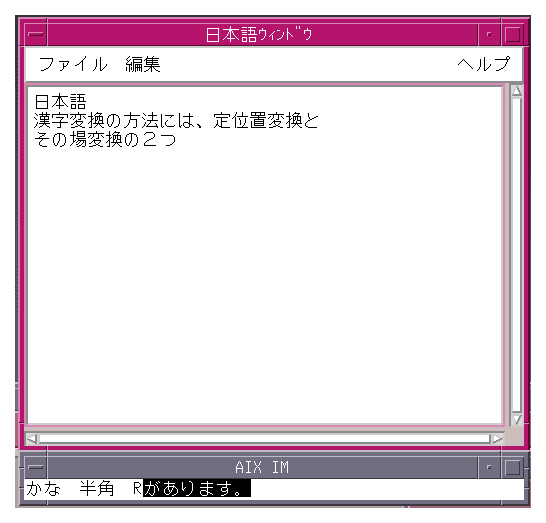
To use OffTheSpot mode, set the OverTheSpot (Default)In OverTheSpot mode, the location of the preedit area is set to where the user is trying to enter characters (for example, the insert cursor position of theText widget that has the current focus). The characters in a preedit area are displayed at the cursor position as an overlay window, and they can be highlighted depending on the input method. Although a preedit area may consist of multiple lines in OverTheSpot mode. The preedit area is always within the MainWindow area and cannot cross its edges in any direction.
Keep in mind that although the preEdit string under construction may be displayed as though it were part of the
To use OverTheSpot mode explicitly, set the Figure 1-5 Example of OverTheSpot preediting with the VendorShell widget (Japanese)
RootIn Root mode, the preedit and status areas are located separate from the client's window. The Root mode behavior is similar to OffTheSpot. See Figure 1-6 for an illustration.Figure 1-6 Example of Root preediting with the VendorShell widget (Japanese)
Status AreaA status area reports the input or keyboard status of the input method to the users. For OverTheSpot and OffTheSpot styles, the status area is located at the lower left corner of the VendorShell window.
VendorShell widget provides geometry management so that a status area is rearranged at the bottom corner of the VendorShell window if the VendorShell window is resized.Auxiliary AreaAn auxiliary area helps the user with preediting. Depending on the particular input method, an auxiliary area can be created. The Japanese input method in Figure 1-3 creates the following types of auxiliary areas:
MainWindow AreaA MainWindow area is the widget used as the working area of the input method. In the system environment, the sole child of theVendorShell widget is the MainWindow widget. It can be any container widget, such as a RowColumn widget. The user creates the container widget as the child of the VendorShell widget.Focus AreaA focus area is any descendant widget under theMainWindow widget subtree that currently has focus. The Motif application programmer using existing widgets does not need to worry about the focus area. The important information to remember is that only one widget can have input method processing at a time. The input method processing moves to the window (widget) that currently has the focus.Interclient Communications Conventions (ICCC)The Interclient Communications Conventions (ICCC) defines the mechanism used to pass text between clients. Because the system is capable of supporting multiple code sets, it may be possible that two applications that are communicating with each other are using different code sets. ICCC defines how these two clients agree on how the data is passed between them. If two clients have incompatible character sets (for example, Latin1 and Japanese (JIS)), some data may be lost when characters are transported.
However, if two clients have different code sets but compatible character sets, ICCC enables these clients to pass information with no data lost. If code sets of the two clients are not identical, CompoundText encoding is used as the interchange with the
Titles and icon names need to be communicated to the Window Manager using the The libXm library and all desktop clients should follow these conventions.
|