HP OpenVMS Systems Documentation |
HP COBOL
|
| Previous | Contents | Index |
The compiler generates the most efficient code to process the following clauses if a COMP unsigned longword integer (that is, PIC 9(9) COMP) is used in those cases where a variable is needed:
RELATIVE KEY
DEPENDING ON
LINAGE IS
WITH FOOTING AT
LINES AT TOP
LINES AT BOTTOM
ADVANCING LINES
This section provides information on how to optimize the following file types:
For a full discussion of file types, see Chapter 6.
15.7.1 Sequential Files
Sequential files have the simplest structure and the fewest options for definition, population, and handling. You can reduce the number of disk accesses by minimizing record length.
With a sequential disk file, you can use multiblocking to access a buffer area larger than the default. Because the system transfers disk data in 512-byte blocks, a blocking factor with a multiple of 512 bytes improves I/O access time. In the following example, the multiblock count (four) causes reads and writes to FILE-A to access a buffer area of four physical blocks:
FILE SECTION.
FD FILE-A
BLOCK CONTAINS 2048 CHARACTERS
.
.
.
|
If you do not want to calculate the buffer size, but want to specify the number of records in each buffer, use the BLOCK CONTAINS n RECORDS clause. The following example specifies a buffer large enough to hold 15 records:
BLOCK CONTAINS 15 RECORDS |
When using the BLOCK CONTAINS n RECORDS clause for sequential files on disk, RMS calculates the buffer size by using the maximum record unit size and rounding up to a multiple of 512 bytes. Consequently, the buffer could hold more records than you specify.
In the following example, the BLOCK CONTAINS clause specifies five records. RMS calculates the block size as eight records, or 512 bytes.
FILE SECTION.
FD FILE-A
BLOCK CONTAINS 5 RECORDS.
01 FILE-A-REC PIC X(64).
.
.
.
|
By contrast, for magnetic tape, the program code entirely controls
blocking. Hence, efficiency of the program and the file depends on the
programmer's care with magnetic-tape blocking.
15.7.2 Relative Files
I/O optimization of a relative file depends on four concepts:
If you create a relative file with an HP COBOL program, the system sets the maximum record number (MRN) to 0, allowing the file to expand to any size.
If you create a relative file with the CREATE/FDL Utility, select a
realistic MRN, since an attempt to insert a record with a number higher
than the MRN will fail.
15.7.2.2 Cell Size
The system calculates cell size. (However, you can specify a different cell size when you create the file by using the RECORD CONTAINS clause in the file description.) You cannot write records larger than the specified cell size.
Avoid selecting a cell size larger than necessary since this wastes disk space. To optimize the packing of cells into buckets, cell size should be evenly divisible into bucket size.
The system calculates cell size using these formulas:
| Fixed-length records: | cell size = 1 + record size |
| Variable-length records: | cell size = 3 + record size |
For fixed-length records, the overhead byte is a record deletion indicator. Variable-length records use two additional overhead bytes to indicate record length. The following example calculates a cell size of 101 for fixed-length records:
FD A-FILE
RECORD CONTAINS 100 CHARACTERS
.
.
.
|
A bucket's size is from 1 to 63 blocks. A large bucket improves sequential access to a relative file. You can prevent wasted space between the last cell and the end of a bucket by specifying a bucket size that is a multiple of cell size.
If you omit the BLOCK CONTAINS clause, the system calculates a bucket size large enough to hold at least one cell or 512 bytes, whichever is larger (that is, large enough to hold a record and its overhead bytes). Records cannot cross bucket boundaries, although they can cross block boundaries.
Use the BLOCK CONTAINS n CHARACTERS clause of the file description to set your own bucket size (in bytes per bucket). Consider the following example:
FILE-CONTROL.
SELECT A-FILE
ORGANIZATION IS RELATIVE.
.
.
.
DATA DIVISION.
FILE SECTION.
FD A-FILE
RECORD CONTAINS 60 CHARACTERS
BLOCK CONTAINS 1536 CHARACTERS
.
.
.
|
In the preceding example, the bucket size is 3 blocks. Each bucket contains:
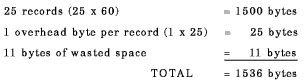
If you use the BLOCK CONTAINS CHARACTERS clause and specify a value that is not a multiple of 512, the I/O system rounds the value to the next higher multiple of 512.
In the following example, the BLOCK CONTAINS clause specifies one record per bucket. Because the cell needs only 61 bytes, there are 451 wasted bytes in each bucket.
FILE-CONTROL.
SELECT B-FILE
ORGANIZATION IS RELATIVE.
.
.
.
DATA DIVISION.
FILE SECTION.
FD A-FILE
RECORD CONTAINS 60 CHARACTERS
BLOCK CONTAINS 1 RECORD.
.
.
.
|
To improve I/O access time: (1) specify a small bucket size, and (2) use the BLOCK CONTAINS n RECORDS clause to specify the number of records (cells) in each bucket. This example creates buckets that contain eight records.
FD A-FILE
RECORD CONTAINS 60 CHARACTERS
BLOCK CONTAINS 8 RECORDS.
.
.
.
|
In the preceding example, the bucket size is one 512-byte block. Each bucket contains:
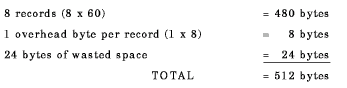
Calculating a file's size helps you determine its space requirements. A file's size is a function of its bucket size. When you create a relative file, use the following calculations to determine the number of blocks that you need, rounding up the result in each case:
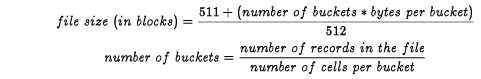
Assume that you want to create a relative file able to hold 3,000 records. The records are 255 bytes long (plus 1 byte per record for overhead), with 4 cells to a bucket (BLOCK CONTAINS 4 RECORDS). To determine file size: (see Section 15.7.2.3)

To allocate the 1500 calculated blocks to populate the entire file, use the APPLY CONTIGUOUS-BEST-TRY PREALLOCATION clause; otherwise, allocate fewer blocks.
Before writing a record to a relative file, the I/O system must have
formatted all buckets up to and including the bucket to contain the
record. Each time bucket reformatting occurs, response time suffers.
Therefore, writing the highest-numbered record first forces formatting
of the entire file only once. However, this technique can waste disk
space if the file is only partially loaded and not preallocated.
15.7.3 Indexed Files
An indexed file contains data records and pointers to facilitate record access.
All data records and record pointers are stored in buckets. A bucket contains an integral number of contiguous, 512-byte blocks. The number of blocks is the bucket size.
Every indexed file must have a primary key, a field in the record description that contains a value for each record. When the I/O system writes records to the indexed file, it collates them according to increasing primary key value in a series of chained buckets. Thus, you can access the records sequentially by specifying ACCESS SEQUENTIAL.
As the I/O system writes records, it builds and maintains a tree-like structure of key-value and location pointers. The highest level of the index is a single bucket, called the root bucket. The I/O system scans one bucket at each level until it reaches the bottom, or data level. In a primary key index, this level contains actual data records. Buckets in each higher level, called index levels, contain index records. Successive levels of an index file are numbered. The data level is level zero. The number of levels above level zero is called the index depth. Figure 15-2 shows a 2-level primary index.
Figure 15-2 Two-Level Primary Index
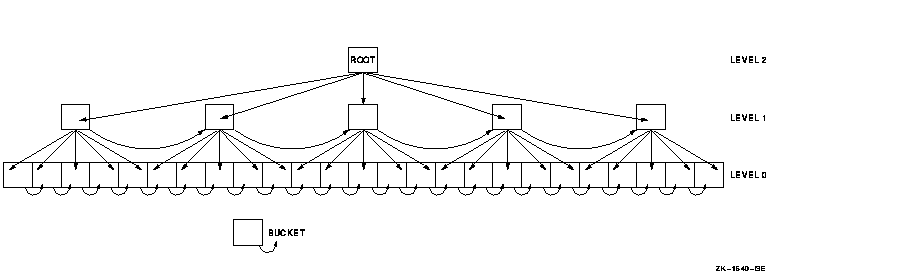
An index is also built for each alternate key that you define for the file. Like the primary index, alternate key indexes are contained in the file. The collating and chaining done for primary keys are also done for alternate keys. However, alternate keys do not contain data records at the data level; instead, they contain pointers, or secondary index data records (SIDRs), to data records in the data level of the primary index.
| Previous | Next | Contents | Index |