HP OpenVMS Systems Documentation |
HP Fortran for OpenVMS
|
| Previous | Contents | Index |
HP Fortran supports record structures provided by Compaq Fortran 77. Compaq Fortran 77 record structures use the RECORD statement and optionally the STRUCTURE statement, which are extensions to the FORTRAN-77, Fortran 90, and Fortran 95 standards. The order of data items in a STRUCTURE statement determines the order in which the data items are stored.
HP Fortran stores a record in memory as a linear sequence of values, with the record's first element in the first storage location and its last element in the last storage location. Unless you specify the /ALIGNMENT=RECORDS=PACKED qualifier, padding bytes are added if needed to ensure data fields are naturally aligned.
The following example contains a structure declaration, a RECORD statement, and diagrams of the resulting records as they are stored in memory:
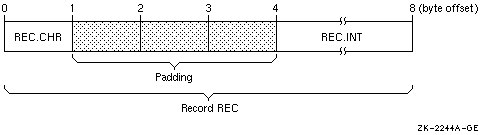
STRUCTURE /STRA/ CHARACTER*1 CHR INTEGER*4 INT END STRUCTURE . . . RECORD /STRA/ REC |
Figure 5-5 shows the memory diagram of record REC for naturally aligned records.
Figure 5-5 Memory Diagram of REC for Naturally Aligned Records
On data declaration statements, see the HP Fortran for OpenVMS Language Reference Manual.
5.3.4 Qualifiers Controlling Alignment
The following qualifiers control whether the HP Fortran compiler adds padding (when needed) to naturally align multiple data items in common blocks, derived-type data, and Compaq Fortran 77 record structures:
The default behavior is that multiple data items in derived-type data and record structures will be naturally aligned; data items in common blocks will not be naturally aligned (/ALIGNMENT=(COMMONS=(PACKED, NOMULTILANGUAGE), RECORDS=NATURAL).
In derived-type data, using the SEQUENCE statement prevents /ALIGNMENT=RECORDS=NATURAL from adding needed padding bytes to naturally align data items.
On the /ALIGNMENT qualifier, see Section 2.3.3.
5.4 Using Arrays Efficiently
The following sections discuss these topics:
Many of the array access efficiency techniques described in this section are applied automatically by the HP Fortran loop transformation optimizations (see Section 5.8.1).
Several aspects of array use can improve run-time performance. The following sections describe these aspects.
Array Access
The fastest array access occurs when contiguous access to the whole array or most of an array occurs. Perform one or a few array operations that access all of the array or major parts of an array instead of numerous operations on scattered array elements.
Rather than use explicit loops for array access, use elemental array operations, such as the following line that increments all elements of array variable A:
A = A + 1. |
When reading or writing an array, use the array name and not a DO loop or an implied DO-loop that specifies each element number. Fortran 90/95 array syntax allows you to reference a whole array by using its name in an expression. For example:
REAL :: A(100,100)
A = 0.0
A = A + 1. ! Increment all elements of A by 1
.
.
.
WRITE (8) A ! Fast whole array use
|
Similarly, you can use derived-type array structure components, such as:
TYPE X
INTEGER A(5)
END TYPE X
.
.
.
TYPE (X) Z
WRITE (8) Z%A ! Fast array structure component use
|
Make sure multidimensional arrays are referenced using proper array syntax and are traversed in the natural ascending order (column major) for Fortran. With column-major order, the leftmost subscript varies most rapidly with a stride of one. Writing a whole array uses column-major order.
Avoid row-major order, as is done by C, where the rightmost subscript varies most rapidly.
For example, consider the nested DO loops that access a two-dimension array with the J loop as the innermost loop:
INTEGER X(3,5), Y(3,5), I, J
Y = 0
DO I=1,3 ! I outer loop varies slowest
DO J=1,5 ! J inner loop varies fastest
X (I,J) = Y(I,J) + 1 ! Inefficient row-major storage order
END DO ! (rightmost subscript varies fastest)
END DO
.
.
.
END PROGRAM
|
Since J varies the fastest and is the second array subscript in the expression X (I,J), the array is accessed in row-major order.
To make the array accessed in natural column-major order, examine the array algorithm and data being modified.
Using arrays X and Y, the array can be accessed in natural column-major order by changing the nesting order of the DO loops so the innermost loop variable corresponds to the leftmost array dimension:
INTEGER X(3,5), Y(3,5), I, J
Y = 0
DO J=1,5 ! J outer loop varies slowest
DO I=1,3 ! I inner loop varies fastest
X (I,J) = Y(I,J) + 1 ! Efficient column-major storage order
END DO ! (leftmost subscript varies fastest)
END DO
.
.
.
END PROGRAM
|
The Fortran 90/95 whole array access ( X = Y + 1 ) uses efficient column major order. However, if the application requires that J vary the fastest or if you cannot modify the loop order without changing the results, consider modifying the application program to use a rearranged order of array dimensions. Program modifications include rearranging the order of:
In this case, the original DO loop nesting is used where J is the innermost loop:
INTEGER X(5,3), Y(5,3), I, J
Y = 0
DO I=1,3 ! I outer loop varies slowest
DO J=1,5 ! J inner loop varies fastest
X (J,I) = Y(J,I) + 1 ! Efficient column-major storage order
END DO ! (leftmost subscript varies fastest)
END DO
.
.
.
END PROGRAM
|
Code written to access multidimensional arrays in row-major order (like C) or random order can often make inefficient use of the CPU memory cache. For more information on using natural storage order during record I/O operations, see Section 5.5.3.
Use the available Fortran 90/95 array intrinsic procedures rather than create your own.
Whenever possible, use Fortran 90/95 array intrinsic procedures instead of creating your own routines to accomplish the same task. HP Fortran array intrinsic procedures are designed for efficient use with the various HP Fortran run-time components.
Using the standard-conforming array intrinsics can also make your program more portable.
Noncontiguous Access
With multidimensional arrays where access to array elements will be noncontiguous, avoid leftmost array dimensions that are a power of 2 (such as 256, 512).
Since the cache sizes are a power of 2, array dimensions that are also a power of 2 may make inefficient use of cache when array access is noncontiguous. If the cache size is an exact multiple of the leftmost dimension, your program will probably make little use of the cache. This does not apply to contiguous sequential access or whole array access.
One work-around is to increase the dimension to allow some unused elements, making the leftmost dimension larger than actually needed. For example, increasing the leftmost dimension of A from 512 to 520 would make better use of cache:
REAL A (512,100)
DO I = 2,511
DO J = 2,99
A(I,J)=(A(I+1,J-1) + A(I-1, J+1)) * 0.5
END DO
END DO
|
In this code, array A has a leftmost dimension of 512, a power of 2. The innermost loop accesses the rightmost dimension (row major), causing inefficient access. Increasing the leftmost dimension of A to 520 (REAL A (520,100)) allows the loop to provide better performance, but at the expense of some unused elements.
Because loop index variables I and J are used in the calculation,
changing the nesting order of the DO loops changes the results.
5.4.2 Passing Array Arguments Efficiently
In HP Fortran, there are two general types of array arguments:
When passing arrays as arguments, either the starting (base) address of the array or the address of an array descriptor is passed:
Passing an assumed-shape array or array pointer to an explicit-shape array can slow run-time performance. This is because the compiler needs to create an array temporary for the entire array. The array temporary is created because the passed array may not be contiguous and the receiving (explicit-shape) array requires a contiguous array. When an array temporary is created, the size of the passed array determines whether the impact on slowing run-time performance is slight or severe.
Table 5-3 summarizes what happens with the various combinations of array types. The amount of run-time performance inefficiency depends on the size of the array.
| Input Arguments Array Types | Explicit-Shape Arrays | Deferred-Shape and Assumed-Shape Arrays |
|---|---|---|
| Explicit-Shape Arrays | Very efficient. Does not use an array temporary. Does not pass an array descriptor. Interface block optional. | Efficient. Only allowed for assumed-shape arrays (not deferred-shape arrays). Does not use an array temporary. Passes an array descriptor. Requires an interface block. |
| Deferred-Shape and Assumed-Shape Arrays |
When passing an allocatable array, very efficient. Does not use an
array temporary. Does not pass an array descriptor. Interface block
optional.
When not passing an allocatable array, not efficient. Instead use allocatable arrays whenever possible. Uses an array temporary. Does not pass an array descriptor. Interface block optional. |
Efficient. Requires an assumed-shape or array pointer as dummy argument. Does not use an array temporary. Passes an array descriptor. Requires an interface block. |
On arrays and their data declaration statements, see the HP Fortran for OpenVMS Language Reference Manual.
5.5 Improving Overall I/O Performance
Improving overall I/O performance can minimize both device I/O and actual CPU time. The techniques listed in this section can greatly improve performance in many applications.
A bottleneck determines the maximum speed of execution by being the slowest process in an executing program. In some programs, I/O is the bottleneck that prevents an improvement in run-time performance. The key to relieving I/O bottlenecks is to reduce the actual amount of CPU and I/O device time involved in I/O. Bottlenecks may be caused by one or more of the following:
Improved coding practices can minimize actual device I/O, as well as the actual CPU time.
HP offers software solutions to system-wide problems like minimizing
device I/O delays (see Section 5.1.1).
5.5.1 Use Unformatted Files Instead of Formatted Files
Use unformatted files whenever possible. Unformatted I/O of numeric data is more efficient and more precise than formatted I/O. Native unformatted data does not need to be modified when transferred and will take up less space on an external file.
Conversely, when writing data to formatted files, formatted data must be converted to character strings for output, less data can transfer in a single operation, and formatted data may lose precision if read back into binary form.
To write the array A(25,25) in the following statements, S1 is more efficient than S2:
S1 WRITE (7) A
S2 WRITE (7,100) A
100 FORMAT (25(' ',25F5.21))
|
Although formatted data files are more easily ported to other systems,
HP Fortran can convert unformatted data in several formats (see
Chapter 9).
5.5.2 Write Whole Arrays or Strings
The general guidelines about array use discussed in Section 5.4 also apply to reading or writing an array with an I/O statement.
To eliminate unnecessary overhead, write whole arrays or strings at one
time rather than individual elements at multiple times. Each item in an
I/O list generates its own calling sequence. This processing overhead
becomes most significant in implied-DO loops. When accessing whole
arrays, use the array name (Fortran 90/95 array syntax) instead of
using implied-DO loops.
5.5.3 Write Array Data in the Natural Storage Order
Use the natural ascending storage order whenever possible. This is column-major order, with the leftmost subscript varying fastest and striding by 1 (see Section 5.4). If a program must read or write data in any other order, efficient block moves are inhibited.
If the whole array is not being written, natural storage order is the
best order possible.
5.5.4 Use Memory for Intermediate Results
Performance can improve by storing intermediate results in memory
rather than storing them in a file on a peripheral device. One
situation that may not benefit from using intermediate storage is a
disproportionately large amount of data in relation to physical memory
on your system. Excessive page faults can dramatically impede virtual
memory performance.
5.5.5 Defaults for Blocksize and Buffer Count
HP Fortran provides OPEN statement defaults for BLOCKSIZE and BUFFERCOUNT that generally offer adequate I/O performance. The default for BLOCKSIZE and BUFFERCOUNT is determined by SET RMS_DEFAULT command default values.
Specifying a BUFFERCOUNT of 2 (or 3) allows Record Management Services (RMS) to overlap some I/O operations with CPU operations. For sequential and relative files, specify a BLOCKSIZE of at least 1024 bytes.
Any experiments to improve I/O performance should try to increase the amount of data read by each disk I/O. For large indexed files, you can reduce disk I/O by specifying enough buffers (BUFFERCOUNT) to keep most of the index portion of the file in memory.
When creating a file, you should consider specifying a RECL value that provides for adequate I/O performance. The RECL value unit differs for unformatted files (4-byte units) and formatted files (1-byte units).
The RECL value unit for formatted files is always 1-byte units. For unformatted files, the RECL unit is 4-byte units, unless you specify the /ASSUME=BYTERECL qualifier to request 1-byte units (see Section 2.3.7).
When porting unformatted data files from non-HP systems, see Section 9.6.
Unless a certain record type is needed for portability reasons (see Section 6.5.3), choose the most efficient type, as follows:
DO loop collapsing reduces a major overhead in I/O processing. Normally, each element in an I/O list generates a separate call to the HP Fortran RTL. The processing overhead of these calls can be most significant in implied-DO loops.
HP Fortran reduces the number of calls in implied-DO loops by replacing up to seven nested implied-DO loops with a single call to an optimized run-time library I/O routine. The routine can transmit many I/O elements at once.
Loop collapsing can occur in formatted and unformatted I/O, but only if certain conditions are met:
| Previous | Next | Contents | Index |