
Lokanath Bagh lokanath.bagh@hp.com
Perdoor Muralidhar Kini muralidhar.kini@hp.com
Chinmay Ghosh chinmay.ghosh@hp.com
Overview
This article aims to explain the salient aspects of directory in OpenVMS file system, its life stages from the time it is created, till it is deleted, and the SYSGEN parameters that can help to improve the overall file system performance. This also aims to explain how a user application can get an optimal performance from file system. This article also includes tips about how some qualifiers with DCL command, in certain scenario, can improve the application response and overall performance.
A brief on OpenVMS file system
OpenVMS file system is called Files-11 file system and also known as on-disk structure (ODS). The functional component that manages the Files-11 file system on OpenVMS is called XQP (Extended QIO processor). The binary file (image) that holds the code for XQP is F11BXQP.EXE. It resides in directories pointed by the logical SYS$LOADABLE_IMAGES.
Files-11 file system currently supports two variants of disk structures. One is called ODS-2 and another one is ODS-5. Compared to ODS-2 structure, the ODS-5 structure supports case sensitive file names, special characters in file names, longer file names, hardlinks, and some additional file attributes. The basic functional model remains same between the two structures.
A file is uniquely identified by a set of three numbers, on a volume. These set of three numbers are called file identification (FID). First part is called the file number, second part is the sequence number and third one is relative volume number. Refer FID diagram Fig. 1.1 for more detail about the FID.
When a file is created, OpenVMS file system returns the file identification (FID) to the user. A user may optionally assign a file name to a file when it is created. User may ask XQP to insert the file name, version and its file identification to a directory file while creating the file itself. XQP also allows a user to make entry for existing file name along with the version and file identification in multiple directories of same volume. In other directories file name and version can be different however file identification remains same. The entries in other directories are called aliases. On ODS-5 alias can be made hardlink, if hardlink characteristic is enabled on the volume. Later file can be opened by specifying the file identification or by specifying the file name and file identification of the directory, where the entry was made during file creation. A file can also be accessed by specifying the alias name and the directory identification where alias was created.
XQP cannot accept file specification which contains subdirectories. RMS (Record Management Services) accepts this specification and finds the file identification of the subdirectories. Each disk volume has the top level directory with name 000000.DIR. It has a fixed file identification which is (4,4,0). This is called MFD (Master File Directory). RMS breaks the file specification which is in the form of device_name:[subdirecty1.subdirectory2]foo.txt and gets file identification of each sub directories and finally file identification of the actual file. RMS starts looking at file identification of first level subdirectory from MFD, file identification of second sub-directory from first sub-directory and so son. Fig. 1.2 shows the directory record structure of a file name along with its version number, FID and other attributes.
In certain circumstances RMS reads directory file and interprets its contents but never modifies the directory file on its own. But a user can write to directory file. XQP does not stop user in doing so, provided user has appropriate rights to modify the directory file. XQP is the sole entity that modifies the directory file. We will explain in details how XQP maintains the directory file.
Fig. 1.1: FID diagram
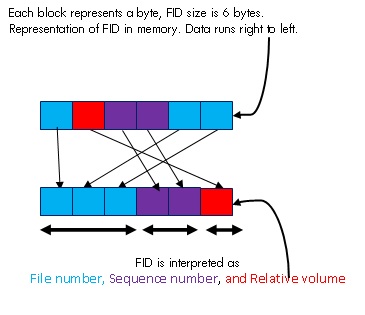
Fig. 1.2: Directory record structures

What is a directory?
A directory is a file which contains information about other files or directories in a given volume. It has few special attributes. These attributes are
- It remains logically contiguous throughout its life time. It can have only one extent.
- Record format is variable length; maximum record size is 512 bytes.
- File organization is sequential
- Each used directory blocks contain at least one filename in the beginning, though under certain condition it may be empty. This is represented as the first word negative and remaining characters are NULLs.
- A file name having many versions where all version numbers do not fit in one block, same file name is repeated in subsequent block.
- File is marked as directory using flag FH2$V_DIRECTORY in file header.
Directory file modification by XQP and the challenges
Over a period of time, the used size of a directory file grows and shrinks. The allocated size also can grow if allocated size is exhausted. New file names can be added to a directory in random order. Files can also be deleted or removed in random order. However XQP always maintains the content of the directory file in alphanumerically sorted order. While inserting a file name in a directory, it first finds out the block which should contain the file name, in sorted order. Space for new file name is created by splitting the block if there is not enough space available in that block. An empty block is created in between the directory file by shifting the blocks towards the end by doing repeated I/Os. This is called directory file in-place shuffle operation. If allocated size is exhausted and block split is required to create space, XQP relocates the directory file to a different location in the disk. It is called expand-shuffle operation.
Similarly if a block becomes empty in between, as a result of file deletion, all the blocks starting from the next to the empty block till the last used block are shifted toward the beginning of the directory file by one block. This is called compress shuffle operation on the directory file.
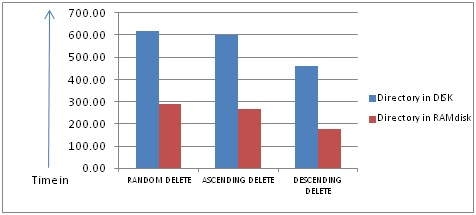
If user wants to delete all or some of the files from a directory, the performance of the delete operation can be improved by deleting the files in reverse alphanumerical order. This will help XQP to avoid doing compress shuffle operation which is shifting blocks by doing repeated I/Os. Figure 1.3 shows the comparison figure of deleting large number of files in random, ascending and descending order. Also it shows the performance when directory file is present in RAM disk, as part of a volume set. Sample command procedure DELETE_REVERSE.COM, provided at the end, shows how to delete all files in reverse order of filenames from directory FOO.DIR present in disk DISK$FOO.
Fig 1.3: File delete comparison for different orders of name
When we issue a DCL "$DELETE *.*;*" command within a directory, files are deleted in ascending order based on their filenames. Deleting files in ascending order is a slower operation as it requires repeated compress shuffle operations.
When an entry is deleted from a block and the block becomes empty, compress shuffle operation is invoked.
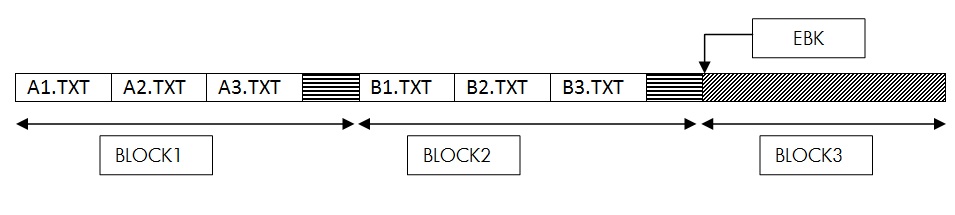
Let’s take an example where a directory has 6 files in it at some point of time. Directory has got 4 blocks allocated to it and currently it has used up 3 blocks. This means EBK of the directory (which is the first free block within the directory) is 4. The files are distributed in the block as follows –
- BLOCK1 of the directory has files A1.TXT, A2.TXT. Rest of BLOCK1 is zeroed out.
- BLOCK2 of the directory has files B1.TXT, B2.TXT. Rest of BLOCK2 is zeroed out.
- BLOCK3 of the directory has files C1.TXT, C2.TXT. Rest of BLOCK3 is zeroed out.
This directory file would appear as below:

If DCL command “$DELETE *.*;*” is executed within this directory, files would be selected from this directory in ascending order of filenames. Below are the sequences of operations triggered by this command.
1) A1.TXT is the first file in the directory and hence, it is selected for deletion. A1.TXT file is present in BLOCK1. Entry for file A1.TXT will be removed and remaining entries will be shifted towards the beginning of the block. The number of blocks within the directory will not change and hence the directory EBK would still be set to 4.
Once this operation is complete, the directory blocks would look as below –

2) A2.TXT is now the first file in the directory and it is the next file selected for deletion. A2.TXT file is present in BLOCK1. As A2.TXT file is the only entry in BLOCK1, a compress shuffle operation would get invoked. As per the compress shuffle operation, the blocks in the directory after BLOCK1 would be moved to the location where BLOCK1 begins.
In this case,
- BLOCK2 is moved to BLOCK1
- BLOCK3 is moved to BLOCK2
This will continue for every remaining used block of the directory file till EBK. As it’s a compress shuffle operation the number of used blocks within the directory will get reduced by 1 and hence the directory EBK will get set to 3.
Once this operation completes, BLOCK3 would be out of the directory used blocks. This is the reason compress shuffle operation does not zero out this block and hence saves an I/O operation. BLOCK3 would continue to have stale information, but this block will no longer be within the directory’s used blocks.
Once this operation is complete, the directory blocks would look as below –

Similar operations would then continue with files B1.TXT, B2.TXT, C1.TXT and C2.TXT.
In this example, we have considered a directory with 6 files distributed over 3 blocks with each block having 2 files each. In a typical production environment, a directory can have hundreds or thousands of files which would be distributed across multiple blocks. In such cases, deleting all the files in the directory would invoke a number of compress shuffle operations resulting in performance degradation.
Creating files in alphanumerical order
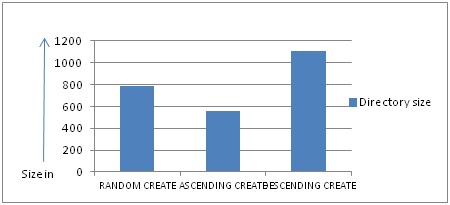
Creating files in alpha numerical order minimizes number of shuffle operations and thus improves the performance. In this scenario file names will always be added at the rear which will avoid the in-place shuffle operation and block shift. There can be expand shuffle operation if all allocated blocks are used. Figure 1.5 shows the comparison among the approaches to create same number of files in random, ascending and descending order. As you can see, creating files in ascending order takes the least amount of time whereas creating files in descending order takes the maximum time because XQP does a number of in-place or expand shuffle and block shift operations.
To understand this better, let us look at different scenarios where filenames are getting created in descending order
Inserting entry in a directory block that can accommodate the new entry
The directory block has enough free space to accommodate the new entry. The entry will be inserted in the right place in the directory block, in order to maintain the sorted order of filenames within the directory.
This would involve moving the entries within the block in order to make room for the new entry.
Example: The following is the contents of the directory file

If a request is made to create A1.TXT file, then XQP will insert the file A1.TXT in BLOCK1 of the directory file to maintain the sorted order. This involves shifting the existing contents of the block i.e. records A2.TXT and A3.TXT towards right in order to make room for the new record i.e. A1.TXT.
Once this operation is complete, the directory would look like below.
Insert Entry in a directory block that cannot accommodate the new entry
If the directory block does not have enough free space to accommodate the new entry, XQP initiates a block split operation. The directory block N is split into two blocks namely N1 and N2.
The contents of the directory block N gets distributed into the blocks N1 and N2. The new filename entry is then added to the block N1 or N2 based on how the block split operation has been performed.
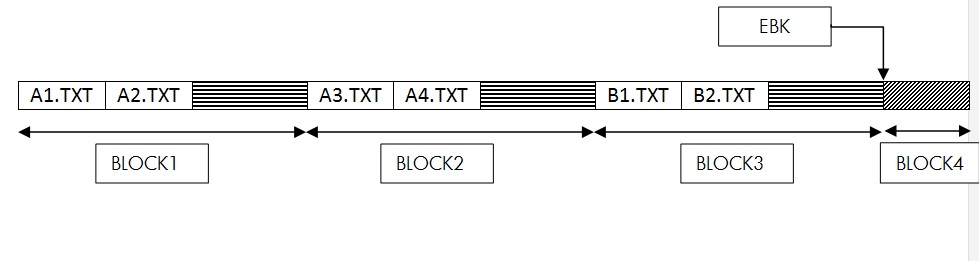
Example:
The following are the contents of the directory file:
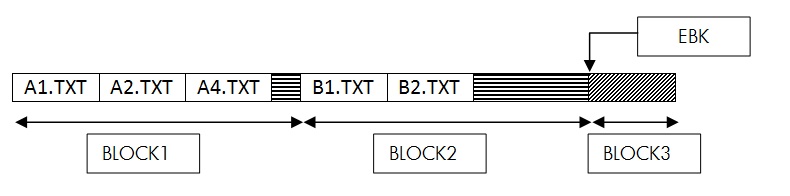
If a request is made to create A3.TXT file, then XQP will insert the file A3.TXT in BLOCK1 of the directory file to maintain the sorted order. However BLOCK1 does not have enough space to accommodate the entry for A3.TXT. Hence XQP initiates a block split operation.
The blocks in the directory from 2 to EBK-1 are shifted to 2 +1 to EBK, thus making the BLOCK2 free.
In this case, there is only one directory block after BLOCK1, hence contents of BLOCK2 get copied to BLOCK3 and EBK of the directory file is updated to 4. The contents of BLOCK1 are split in to two blocks. BLOCK1 would retain the entries for A1.TXT and A2.TXT. BLOCK2 would have entry for A4.TXT. The entry for A3.TXT is then added in BLOCK2.
Once this operation is complete, the directory would look like below.
Now let us look at scenarios where filenames are created in ascending order
Insert Entry in a directory block that can accommodate the new entry
The directory block has enough free space to accommodate the new entry. As the filenames are generated in ascending order, the filename entry will always be inserted as the last record in the directory block. Hence there is no need of moving any entries within the directory block for adding a filename entry.
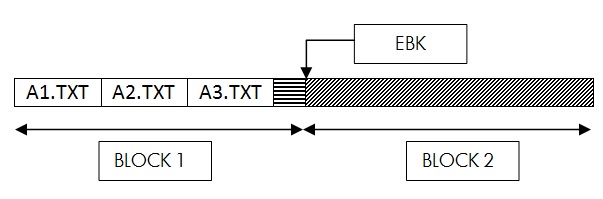
Example:
The following is the contents of the directory file

If a request is made to create A3.TXT file, then XQP will insert the file A3.TXT in BLOCK1 of the directory file to maintain the sorted order. As filenames are generated in ascending order, A3.TXT happens to be the last file in the BLOCK1. Hence, there is no need to shift existing entries in the block. Entry for A3.TXT is added as the last entry in the block.
Once this operation is complete, the directory would look like below.
Insert entry in a directory block that can’t accommodate the new entry
The directory block does not enough free space to accommodate the new entry.
As the filenames are generated in ascending order of filenames, the new entry would have to be the last file in the directory. XQP will not initiate a block split operation on the last block, but instead would use subsequent unused block and make entry for the new filename in the new block. Hence this operation would not involve any block split operation. But if all allocated blocks are exhausted XQP has to perform expand shuffle operation.
Example:
The following is the contents of the directory file –
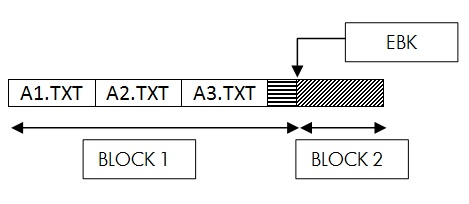
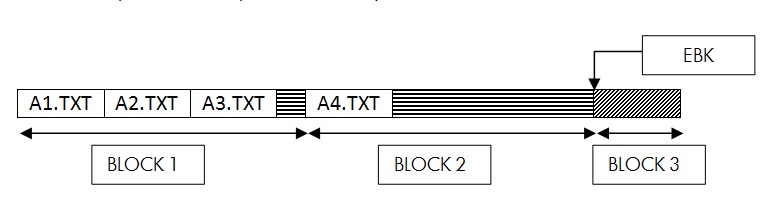
If a request is made to create A4.TXT file, then XQP will insert the file A4.TXT in the last block of the directory file to maintain the sorted order. BLOCK1 does not have enough space to accommodate the entry for A4.TXT. As the filename to be inserted in the directory has to be the last file in the block, XQP will use another unused block of the directory and inserts the entry for the new filename in the new block added and updates the EBK by 1. This operation would be faster as no block split operation is involved.
Once this operation is complete, the directory would look like below.
Growth of directory file size with respect to alphanumerical naming order of creation
Used and allocated size of a directory file may grow faster if files are created in descending order of names. This happens because XQP has to split the directory block which always happens to be the block lying at the beginning of directory. While splitting directory blocks which is not the last used block of the directory, split happens in the middle. So, all the blocks will be half filled. If the files are created in ascending order, all blocks will be completely filled and final directory file size will be smaller. In case of file names arriving in random order, some blocks will be half filled and some full. So directory file size will be around average size of the cases of ascending and descending order. Figure 1.4 shows the graphical comparison for a set of a large number of files creation for three orders mentioned above.
Fig. 1.4: Directory file size growth with respect to creation of order of file
Pre-allocate enough space to directory file to avoid directory movement Directory file can be created using DCL CREATE/DIRECTORY command or by calling system service SYS$QIO(W) with appropriate parameters. At least a cluster size is allocated when directory file is created.
When allocated size of the directory is used up completely and a new file is created in it, XQP extends the directory file implicitly by an amount which is either 100 blocks or half of the directory file size, whichever is less. The minimum amount is 1 block. Extent amount is always rounded to cluster factor.
There is an extra overhead involved when directory file is extended. The way directory file is extended is different than the way other files get extended. One of the key differences is that a directory file should be logically contiguous. It can‘t have more than one extent. So when a directory file is extended, OpenVMS file system (XQP) has to grab required number of logically contiguous blocks from the volume. The required number is the sum of current directory file size and the amount of extended quantity, calculated as per criteria mentioned in above paragraph. If XQP fails to get required number of logically contiguous blocks, then XQP will abort the current file operation and report appropriate error to user.
Once the required amount of logically contiguous space is acquired, data from old location is copied to new location, in two phases, depending on the where current entry will be inserted in the directory file. If the entry is to be inserted at the end of the directory file, i.e. the file name falls alphabetically at the end, directory blocks will be moved from beginning blocks to the end of blocks to new location. If the file name entry is to be inserted somewhere in the middle, directory blocks are copied in two segments. However overheads are same for both the cases, because entire directory data blocks are copied to new location.
After directory blocks are copied from old location to new location, old blocks are de-allocated. This is an extra overhead. Figure 1.5 depicts the directory file relocation operation. For simplicity it is assumed that a block will be full after inserting a single entry, and an attempt to insert another entry will result in a block split.
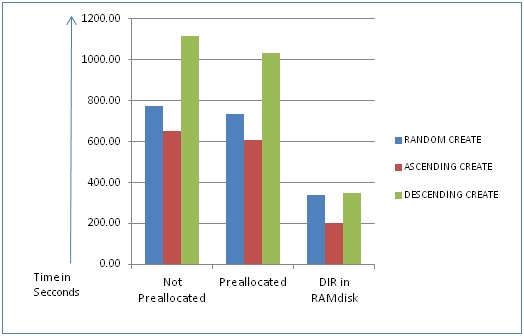
The above overhead can be avoided by pre-allocating sufficient number of blocks during directory file creation. The DCL command CREATE/DIRECTORY provides a qualifier ‘/ALLOCATION’/ to specify the pre-allocated size. Figure 1.6 shows comparison of time taken to create large number of files in a directory having enough blocks pre-allocated and with one cluster block allocated initially. The figure also shows the performance when the directory file is in RAM disk, as part of a volume set.
Fig 1.5: Directory file expand shuffle operation
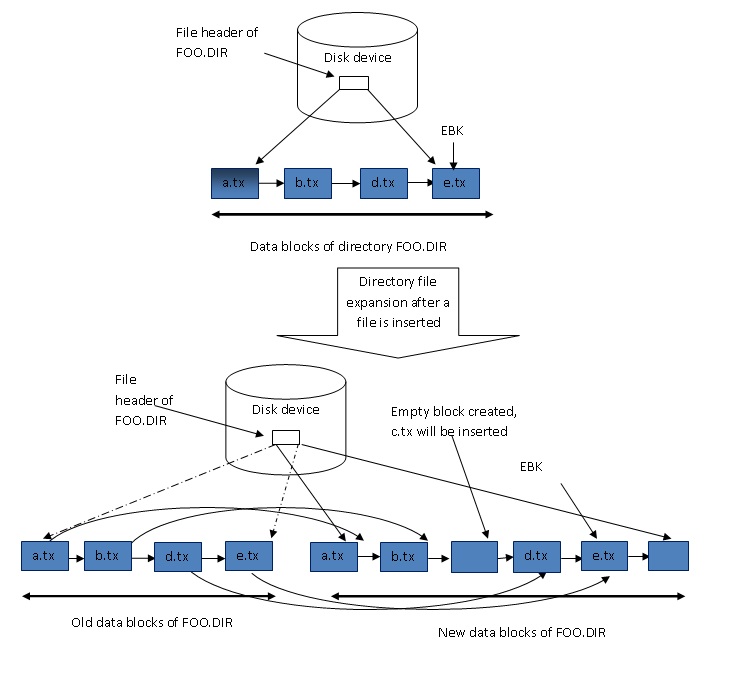
Fig. 1.6: File creation performance comparisons against pre-allocated directory space and without pre-allocated space:
Increase XQP SYSGEN parameters ACP_* to facilitate XQP to perform big I/O while doing shuffle (in-place, expand and compress) operation
XQP SYSGEN parameters:
- ACP_DIRCACHE - number of pages for caching directory blocks
- ACP_MAXREAD - maximum number of directory blocks read in one I/O operation
- ACP_DINDXCACHE - number of buffers used on a cache wide basis
OpenVMS file system (XQP) needs virtual memory (RAM) to read directory data blocks from disk, update its contents and write the modified data back to disk. The virtual memory is allocated from paged pool, when a device is mounted. When system disk is mounted during boot up process, a chunk of memory is allocated to be used by XQP for file system related operation. This is called XQP buffer cache. XQP buffer cache is dealt with unit of blocks i.e. 512 bytes. Subsequent mount of any other device will be using this chunk unless the device is mounted with DCL command MOUNT with qualifier /PROCESSOR=UNIQUE. In general a single XQP buffer is used, which is the buffer that was allocated when the system disk was mounted. The XQP buffer cache has four segments. Each segment size depends upon the ACP SYSGEN parameter. In one of the segment, directory data blocks are stored. This segment size depends on the ACP SYSGEN parameter ACP_DIRCACHE. This SYSGEN parameter value represents the number of directory data blocks can be cached in buffer. Attempt to read more number of directory blocks will result in one of the directory blocks to go away from cache. Victim buffer is selected based on LRU (least recently used) algorithm.
While shifting directory blocks XQP reads a set of directory data blocks and writes them to different location in the disk. It does repetitive I/Os to do that operation. XQP shifts them using big I/O, that needs larger buffer. XQP grabs memory for larger buffer from paged pool. The larger buffer size is controlled by ACP SYSGEN parameter ACP_MAXREAD. If XQP fails to get ACP_MAXREAD number blocks, it tries for ACP_MAXREAD/2 blocks; still if it fails it tries with ACP_MAXREAD/4 number and so on. If XQP fails to get at least 2 blocks of memory, XQP uses its internal buffer whose size is one block.
So to improve performance, it is advisable that user should increase the SYSGEN parameter ACP_DIRCACHE and ACP_MAXREAD to larger value. This will help to increase the performance of file creation where user asks to create directory entry. While XQP is doing directory entry updates and there is not enough virtually contiguous memory available from paged pool area, XQP may end up using small buffer sizes to do block shifts and which will result into performance degradation. DCL command SHOW MEMORY shows paged pool usages.
$ sh mem
.
.
.
Dynamic Memory Usage: | Total | Free | In Use | Largest |
Nonpaged Dynamic Memory (MB) | 19.25 | 12.00 | 7.24 | 10.25 |
Paged Dynamic Memory (MB) | 11.02 | 5.86 | 5.16 | 5.85 |
Lock Manager Dyn Memory (MB) | 1.71 | 0.28 | 1.42 |
SDA command ‘SDA> show pool/page/header/summary’ tells about paged pool usages.
SYSGEN parameter ACP_DINDXCACHE XQP does binary search in a directory while doing lookup operation for a particular file name, because directory contents are always sorted alphanumerically. While reading/modifying the directory blocks XQP builds memory based index structure which is called directory index cache. The space used to build indexed structure is one block, i.e. 512 bytes. This helps XQP in future operation to quickly find the point, the starting block, from where to start the lookup operation for a given file name.
512 bytes of memory is divided into fixed cell based on directory file’s used size and is used to build index structure called directory index cache. In the fixed cell, fixed numbers of characters are stored which can be complete file name or part of it if file name is long. This partial file name is the entry found at the end of a directory data block. The part of the file name that is present in the index cache cell tells that a particular name can be found below or above a particular block that index cache points to. But if parts of file names that are stored in directory index cache are not unique then the purpose of the directory index cache diminishes.
Customer can also increase this SYSGEN parameter, if a system has more than ACP_DINDXCACHE number of directory files and that are accessed at the same time. It is the sum of directories present in all the disk devices mounted without qualifier '/PROCESSOR=UNIQUE'.
Files used for temporary storage for a duration of a program (Image) execution
Sometimes user creates files as temporary storage and immediately deletes those files once program finishes its execution. This type of files should be created as a temporary file, which will ask XQP to mark them for deletion at the time of file creation itself. In this scenario XQP will not create an entry in the directory file and file will be deleted once it is closed.
Slower performance while creating files in a large directory
In a loaded system where large numbers of files are created/deleted in/from a directory by many processes the performance may be slower. This would be because of XQP which has to deal with larger directory file size. Directory file access, both read and write, is serialized across cluster. So larger directory file size may degrade file creation performance, when multiple processes are trying to create files in the same directory with different names. If each process’s requested operation results in either in-place shuffle, compress or expand shuffle, then XQP has to shift many blocks for each operation. So the processes those are in rear of the queue will have to wait relatively longer period of time to get their requested operation complete.
Creating volume set with RAM disk to create directory file on RAM disk
For applications that perform large number of file creation and deletion in many directories, RAM disk can be used to create a volume set along with physical disk(s) and place the directories in the RAM disk. For example while creating a directory using DCL command CREATE/DIRECTORY, the qualifier ‘/VOLUME’ can be used to place them in the RAM disk part of the volume set. This will help XQP to make entry in directory file faster. However, if the system crashes or in the event of a system shutdown, the entire content of the RAM disk will be lost and the volume set may not be useable any more. Users will have to create all the files once again after initializing the volume set. This is a very risky option and user can opt for this when non availability of the RAM disk will not hamper their operation.
Below example shows how to create a volume set using a RAM disk and a physical disk- Command to create RAMdisk:
$ RUN SYS$SYSTEM:SYSMAN SYSMAN> IO CONNECT MDA0:/DRIVER=SYS$MDDRIVER/NOADAPTER SYSMAN> EXIT
DCL Command “$MC MDMANAGER” can also be used to create RAM disk.
Command to initialize RAMdisk:
$ INITIALIZE MDA0 RAMDISK /SIZE=300
The following command will create a volume set using a physical disk $1$DKB100 having volume label TEMP and a RAMdisk MDA0 having volume label RAMDISK. The volume can be accessed using the logical TEST.
$ MOUNT/SYS/BIND=TEST $1$DKB100:,MDA0: TEMP,RAMDISK TEST
For more help to create volume set refer to DCL help on command MOUNT/BIND.
Useful commands to analyze directory files
Here are some of the useful commands that will help a system administrator to analyze directory files-
1) Dump the content of directory file (block and record dump)
- Block dump, used blocks only
$ DUMP FOO.DIR - Block dump, all allocated blocks
$ DUMP/ALLOCATED FOO.DIR - Record dump, used blocks only
$ DUMP/DIRECTORY FOO.DIR - Record dump, all allocated blocks
$ DUMP/DIRECTORY/ALLOCATED FOO.DIR
2) Reset directory file flag and modifying EBK of directory
- Make a directory file as non-directory file to delete the directory file. Please note that there is no command available to reset the file flag back to directory. Entries present in the directory if any will be lost. ANALYZE/DISK/REPAIR can be run to recover them to [SYSLOST] directory. $SET FILE FOO.DIR/NODIRECTORY
- To change the used block count of directory file
$SET FILE FOO.DIR/ATTRIB=(EBK=##)
Sample command procedure DELETE_REVERSE.COM
$ SET NOON
$ ON ERROR THEN GOTO ERR_EXIT
$ IF F$SEARCH("TEMP.COM") .NES. "" THEN DELETE/NOLOG TEMP.COM;*
$ OPEN/WRITE/ERROR=ERR_EXIT IN TEMP.COM
$ START:
$ FILE = F$SEARCH("DISK$FOO:[FOO]*.*;*")
$ IF FILE .EQS. "" THEN GOTO FILE_CLOSE
$ FILE = "$DELETE " + FILE
$ WRITE IN FILE
$ GOTO START
$ FILE_CLOSE:
$ CLOSE IN
$ LRL = F$FILE_ATTRIBUTES("TEMP.COM","LRL")
$ SORT/KEY=(DESC,POSI:1,SIZE:'LRL) TEMP.COM TEMP.COM
$ PURGE/NOLOG TEMP.COM
$ @TEMP.COM
$ ERR_EXIT:
$ EXIT
Summary
Directory files store the file names of the files and sub-directories in alphanumerically sorted order. It doesn’t contain any other index structure. So creating a file in a directory, or accessing it or deleting files from it may result in poor application response time depending on several scenarios explained above. Tuning some of the OpenVMS file system parameters or some application configuration changes like create file in alphanumerical order or deleting files in descending order, wherever possible, will improve the overall application/file system performance.
For more information
- VMS file system internals by Kirby McCoy ISBN:1-55558-056-4
- HP OpenVMS I/O User’s Reference Manual http://h71000.www7.hp.com/doc/84FINAL/ba554_90018/ba554_90018.pdf