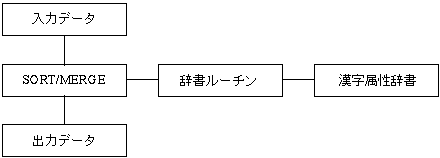
#include <stsdef.h>
struct DESCRIPTOR {
int leng ;
char *ptr ;
};
globalvalue SOR$K_SEQ_ONYOMI,
SOR$M_SEQ_CHECK;
main(){
char infile1[] = "EXAM31.DAT" ,
infile2[] = "EXAM32.DAT" ,
outfile[]= "EXAM3OUT.DAT" ;
struct DESCRIPTOR
inptr1 ={strlen(infile1) , infile1},
inptr2 ={strlen(infile2) , infile2},
outptr ={strlen(outfile) , outfile};
short lrl, key[5] ;
int status, option;
/* initialize the key */
key[0] = 1 ; /* key no. */
key[1] = SOR$K_SEQ_ONYOMI ; /* onyomi */
key[2] = 0 ; /* ascend */
key[3] = 5 ; /* offset */
key[4] = 6 ; /* size */
lrl = 131; /* LRL */
option = SOR$M_SEQ_CHECK; /* check input sequence */
/* merge the files */
if (!((status=sor$pass_files(&inptr1, &outptr)) & STS$M_SUCCESS))
lib$stop(status);
if (!((status=sor$pass_files(&inptr2)) & STS$M_SUCCESS))
lib$stop(status);
if (!((status=sor$begin_merge(key, &lrl, &option)) & STS$M_SUCCESS))
lib$stop(status);
if (!((status=sor$end_sort()) & STS$M_SUCCESS))
lib$stop(status);
}
|