| 前へ | 次へ | 目次 | 索引 |
この章では,さまざまな OpenVMS Cluster でスケーラビリティを最大限に活かす方法を説明します。
10.1 スケーラビリティとは?
スケーラビリティは,初期の構成機器をフルに活用しながら,任意のシステム,ストレージ,インターコネクトの各次元で,OpenVMS Cluster システムを拡張できる能力をいいます。 図 10-1 にも示すように OpenVMS Clusterシステムの拡張はさまざまな次元に見られます。また,各次元ではユーザ・アプリケーションの拡張も可能です。
図 10-1 OpenVMS Cluster 拡張次元
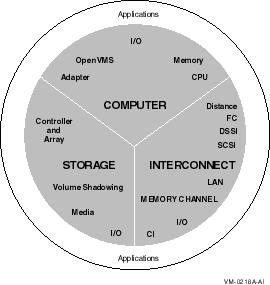
表 10-1 は,OpenVMS Cluster におけるシステム,ストレージ,インターコネクトの拡張次元を図示したものです。
| 対象次元 | 拡張要因 |
|---|---|
| システム | |
| CPU | システム内に SMP を実装。
クラスタにシステムを追加。 クラスタに各種プロセッサ・サイズを格納。 クラスタに大きなシステムを追加。 VAX システムから Alpha システムに移行。 |
| メモリ | システムにメモリを追加。 |
| I/O | インターコネクトとアダプタをシステムに追加。
MEMORY CHANNEL をクラスタに追加して I/O インターコネクトのロードを抑制。 |
| OpenVMS | システム・パラメータの調整。
OpenVMS Alpha の移動。 |
| アダプタ | ストレージ・アダプタをシステムに追加。
CI アダプタと DSSI アダプタをシステムに追加。 LAN アダプタをシステムに追加。 |
| ストレージ | |
| 媒体 | ディスクをクラスタに追加。
テープと CD-ROM をクラスタに追加。 |
| ボリューム・シャドウイング | ディスクのシャドウイングによる可用性の強化。
各コントローラのディスクのシャドウイング。 各システムのディスクのシャドウイング。 |
| I/O | 半導体ディスクまたは DECram ディスクをクラスタに追加。
キャッシュ付きディスクとコントローラをクラスタに追加。 RAID ディスクをクラスタに追加。 |
| コントローラとアレイ | ディスクとテープをシステムからコントローラに移動。
ディスクとテープをアレイに組み合わせ。 コントローラとアレイをクラスタに追加。 |
| インターコネクト | |
| LAN | Ethernet セグメントと FDDI セグメントの追加。
Ethernet から FDDI へのアップグレード。 冗長セグメントの追加とセグメントのブリッジ化。 |
| CI,DSSI,Fibre Channel,SCSI,MEMORY CHANNEL | CI,DSSI,Fibre Channel,SCSI,MEMORY CHANNEL インターコネクトをクラスタに追加,または冗長インターコネクトをクラスタに追加。 |
| I/O | キャパシティを目的とした高速インターコネクトの追加。
キャパシティと可用性を目的とした冗長インターコネクトの追加。 |
| 距離 | 室内または建物内でクラスタを展開。
都市内または数軒のビル間でクラスタを展開。 2 個所のサイト間でクラスタを展開 (距離 40 km)。 |
表 10_1
に掲載した構成要素を,ユーザが選択した任意の方法で追加する機能は,OpenVMS Cluster における重要な機能に位置づけられます。この章や,製品のマニュアル,そしてDIGITAL Systems and Options Catalog
の説明や指針に従って,ハードウェアとソフトウェアはさまざまな方法の組み合わせで追加することができます。特定の次元における OpenVMS Cluster の拡張をする場合は,他の次元との関係で長所や短所を検討してください。 表 10-2
は, OpenVMS Cluster のスケーラビリティを強化するための手法をまとめたものです。これらのスケーラビリティ手法を理解すれば,高いレベルのパフォーマンスと可用性を維持しながら OpenVMS Cluster の拡張に対応することができます。
10.2 スケーラビリティの高い OpenVMS Cluster の構成手法
選択するハードウェアと,その構成に適用する手法は,OpenVMS Cluster のスケーラビリティと重要な関係があります。この項では,スケーラビリティの高い OpenVMS Cluster の構成方法を説明します。
10.2.1 スケーラビリティの手法
表 10-2 は,スケーラビリティについて重要度の高い順に手法を並べています。この章では,この手法の実装方法を多くの図を使って説明します。
| 手法 | 説明 |
|---|---|
| キャパシティの計画 | キャパシティの 80% (ほぼパフォーマンスとしては飽和状態) を超えてシステムを実行している状態では,それ以上の拡張性は望めません。
ビジネスやアプリケーションが拡大するかどうかを見極める必要があります。プロセッサ,メモリ,I/O に将来,どのような仕様が必要になるかを見積もることも大切です。 |
| 全ストレージへの共用の直接アクセス | コンピュータと I/O のパフォーマンスのスケーラビリティは,全システムから全ストレージまで共用の直接アクセスが設定されているかどうかで大きく異なります。
以下に示す CI と DSSI OpenVMS Cluster の図では,MSCP のオーバヘッドなしでストレージへの共用直接アクセスを実装したさまざまな例を示します。 関連項目: MSCP のオーバヘッドの詳細については, 第 10.8.1 項 を参照してください。 |
| ノード・カウントの範囲を,3 から 16 に制限 | OpenVMS Cluster が小さければパフォーマンスの管理や調整がしやすく,大きな OpenVMS Cluster よりも OpenVMS Cluster 通信のオーバヘッドが少なくて済みます。ノード・カウントを抑制するには,強力なプロセッサにアップグレードし, OpenVMS SMP の能力を活かします。
サーバに負荷がかかり過ぎてコンピューティングのボトルネックになっている場合,アプリケーションをノード間に分散できないか検討します。可能であれば,ノードを追加します。 不可能な場合は,プロセッサ (SMP) を追加します。 |
| システム・ボトルネックを取り除く | OpenVMS Cluster 機能のキャパシティを最大化するにあたっては,その機能を実装するハードウェアとソフトウェアの構成要素を検討します。ボトルネックになっている構成要素があると,他の構成要素のポテンシャルをフルに活せなくなります。ボトルネックを探し出し,その要因を削減すれば,OpenVMS Cluster のキャパシティを強化できます。 |
| MSCP サーバを使用可能にする | MSCP サーバを利用すれば, OpenVMS Cluster にサテライトを追加でき,すべてのストレージへのアクセスをノード間で共用できます。また,MSCP サーバには,インターコネクトに障害が発生すると共用ストレージに対するフェールオーバを実行する機能があります。 |
| 相互依存の緩和と単純な構成 | システム・ディスクが 1 つだけの OpenVMS Cluster システムは,そのディスクだけに OpenVMS Cluster の実行を依存します。ディスクや,そのディスクのサービスをしているノード,あるいはノード間のインターコネクトに障害が発生すると, OpenVMS Cluster システム全体が使用できなくなります。 |
| サービス用リソースの確保 | 容量の小さいディスク・サーバで多くのディスクをサテライトに提供する場合,OpenVMS Cluster 全体のキャパシティが制約されます。サーバが過剰負荷になるとボトルネックになり,フェールオーバによる回復操作を効果的に処理できなくなるので注意してください。 |
| リソースとコンシューマを近づける | サーバ (リソース) とサテライト (コンシューマ) の間を近づけます。OpenVMS Cluster のノード数を追加する場合は,まず分割することを検討してください。詳細については, 第 11.2.4 項 を参照してください。 |
| 適切なシステム・パラメータの設定 | OpenVMS Cluster の拡張度合いがめざましい場合,重要なシステム・パラメータが現状に合わなくなることがあります。このようなときは,重要なシステム・パラメータを自動的に計算し,ページ,スワップ,ダンプの各ファイルのサイズ調整ができる AUTOGEN を実行してください。 |
10.3 CI OpenVMS Cluster におけるスケーラビリティ
1 つの CI スター・カプラには,最高で 32 のノードを付けることができます。その内,16 ノードをシステムにでき,残りをストレージ・コントローラとストレージにできます。
図 10_2
, 図 10_3
, 図 10-4
は,2 ノード CI OpenVMS Cluster から 7 ノード CI OpenVMS Cluster への拡張状況を示しています。
10.3.1 2 ノード CI OpenVMS Cluster
図 10-2 では,クォーラム・ディスクを含むストレージまで 2 つのノードから共用の直接アクセスが設定されています。VAX システムと Alpha システムのどちらにも専用のシステム・ディスクが設定されています。
図 10-2 2 ノード CI OpenVMS Cluster
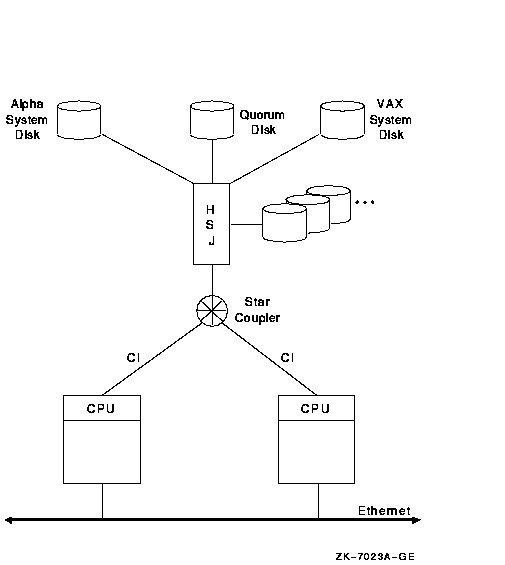
図 10-2 に示すこの構成の長所と短所は次のとおりです。
ストレージ・リソースや処理リソースの需要が増加すると,OpenVMS Cluster の構成は 図 10-3 のようになります。
10.3.2 3 ノード CI OpenVMS Cluster
図 10-3 では,3 つのノードは CI インターコネクトで 2 つの HSC コントローラに接続されています。重要なシステム・ディスクは,デュアル・ポート化され,シャドウ化されています。
図 10-3 3 ノード CI OpenVMS Cluster
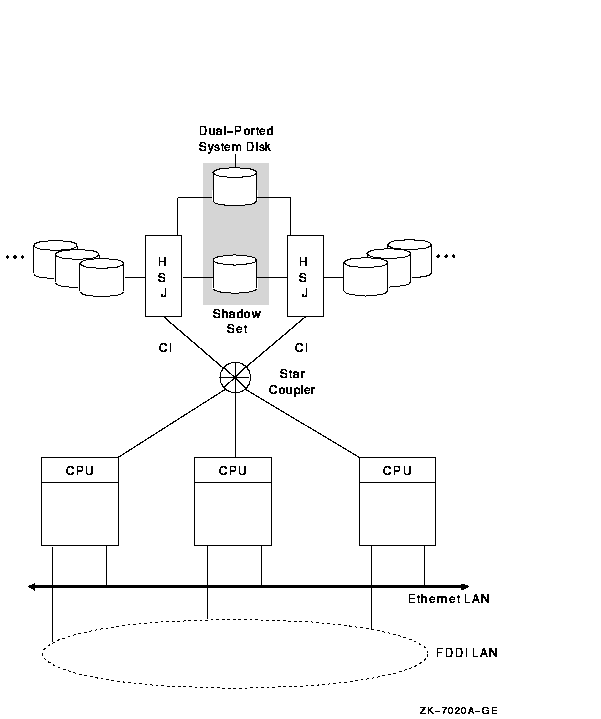
図 10-3 に示すこの構成の長所と短所は次のとおりです。
I/O 処理が CI インターコネクトのキャパシティを超えると,OpenVMS Cluster の構成は 図 10-4 のようになります。
10.3.3 7 ノード CI OpenVMS Cluster
図 10-4 に示す 7 ノードは,それぞれ 2 つのスター・カプラとすべてのストレージに直接アクセスできます。
図 10-4 7 ノード CI OpenVMS Cluster
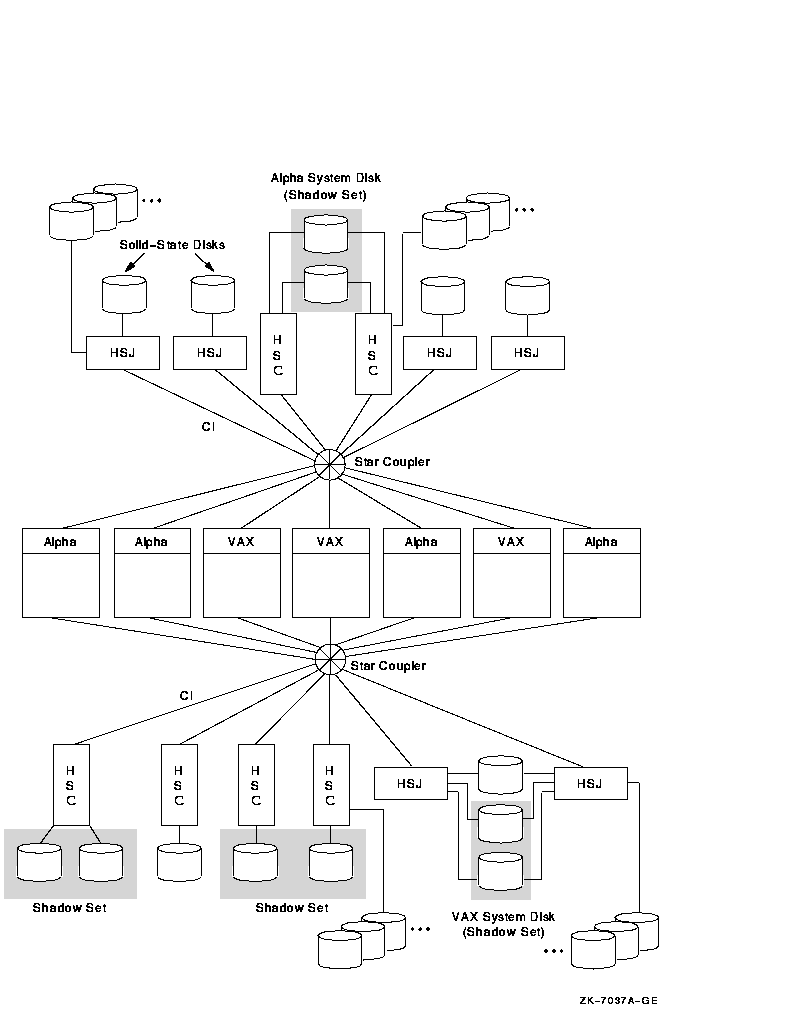
図 10-4 に示すこの構成の長所と短所は次のとおりです。
以下の指針に従って,CI OpenVMS Cluster を構成してください。
関連項目: システム・ディスクの詳細については, 第 11.2 節 を参照してください。
一般に,合計値の計算には以下の規則を適用します。
10.3.5 CI OpenVMS Cluster のボリューム・シャドウイングにおける指針
ボリューム・シャドウイングは,可用性の強化を目的としたもので,パフォーマンスは対象外です。ただし,以下のボリューム・シャドウイングの手法では, I/O キャパシティを最大限に維持しながら可用性の強化することができます。以下の例では,CI の構成を示していますが,DSSI と SCSI の構成にも適用できます。
図 10-5 シングル・コントローラ上のボリューム・シャドウイング
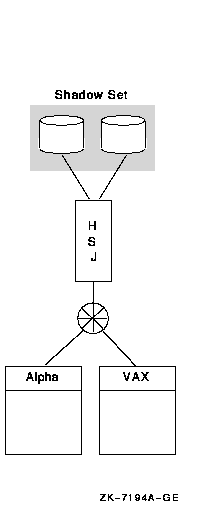
図 10-5 では,2 つのメンバ・シャドウ・セットとともに HSJ に 2 ノードが接続されています。
この方法の短所として,コントローラが単一点障害の要因になる可能性があります。 図 10-6 における構成は,すべてのコントローラ間のシャドウイングの例を示しています。これにより,1 つのコントローラに障害が発生しても全体が使用できなくなることはありません。すべての HSJ コントローラや HSC コントローラにシャドウイングをすると,OpenVMS Cluster システムにおけるスケーラビリティと可用性を最適化できます。
図 10-6 すべてのコントローラに対するボリューム・シャドウイング
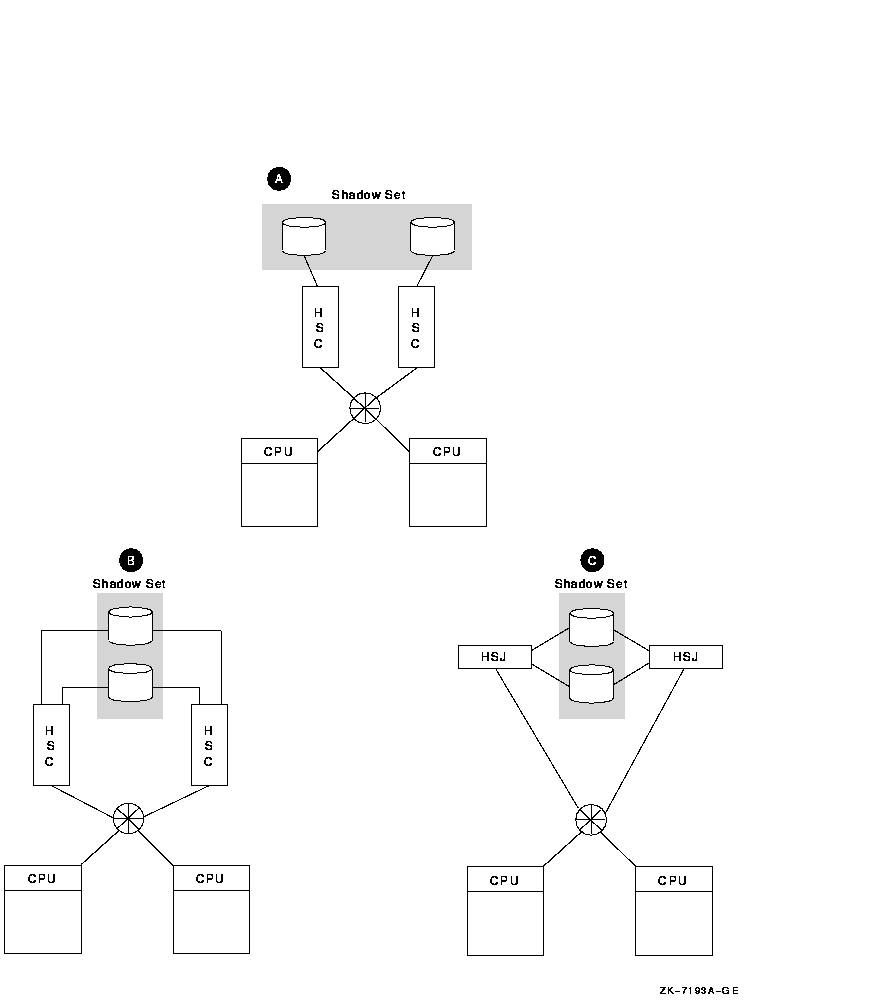
図 10-6 にあるように,すべてのコントローラに対してシャドウイングする方法は,3 通りあります。
図 10-7 は,すべてのノードを対象にしたシャドウイングの例です。
図 10-7 すべてのノードを対象にしたボリューム・シャドウイング
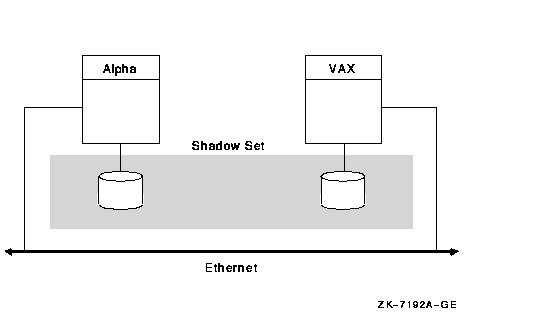
図 10-7 にあるように,すべてのノードでシャドウイングすると距離面で融通性があり有利です。ただし,書き込み I/O で MSCP サーバにオーバヘッドがかかります。また,ノードのどれかに障害が発生し, OpenVMS Cluster へ復帰する際にコピー操作が必要になります。
ボリュームが複数あれば,コントローラ内のシャドウイングと,すべてのコントローラに対するシャドウイングの方が,すべてのノードに対してシャドウイングをするよりも効果的です。
関連項目: 詳細については,『Volume Shadowing for OpenVMS』を参照してください。
| 前へ | 次へ | 目次 | 索引 |