HP OpenVMS Systems Documentation |
    
Common Desktop Environment: Internationalization Programmer's Guide 3 Internationalization and Distributed NetworksContents of Chapter: This chapter discusses tasks related to internationalization and distributed networks. Interchange ConceptsThis section describes the way 8-bit user names and 8-bit data can be communicated on a network for communications utilities, such as ftp, mail, or interclient communication between the desktop clients.There are three primary considerations for communicating data:
iconv InterfaceIn a network environment, the code sets of the communicating systems and the protocols of communication determine the transformation of user-specified data so that it can be sent to the remote system in a meaningful way. The user data (not user names) may need to be transformed from the sender's code set to the receiver's code set, or 8-bit data may need to be transformed into a 7-bit form to conform to protocols. A uniform interface is needed to accomplish this.In the following examples, using the iconv interface is illustrated by explaining how to use iconv_open(), iconv(), and iconv_close(). To do the conversion, iconv_open() must be followed by iconv(). The terms 7-bit interchange and 8-bit interchange are used to refer to any interchange encoding used for 7-bit and 8-bit data, respectively.
Sender and Receiver Use the Same Code Sets:
Sender and Receiver Use Different Code Sets:
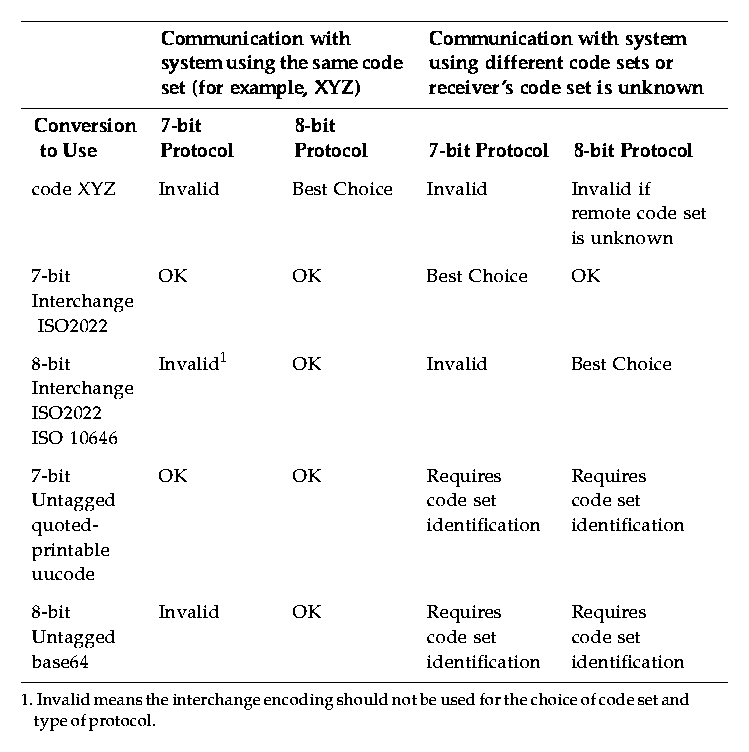
locale_codeset refers to the code set being used locally by the application. Note that while the nl_langinfo(CODESET) function may be used to obtain the code set associated with the current locale, it is implementation-dependent whether any conversion names match the return from the nl_langinfo(CODESET) function.Table 3-1 outlines how iconv can be used to perform conversions for various conditions. Specific protocols may dictate other conversions needed.
Table 3-1 Using iconv to Perform Conversions Stateful and Stateless ConversionsCode sets can be classified into two categories: stateful encodings and stateless encodings.Stateful EncodingsStateful encoding uses sequences of control codes, such as shift-in/shift-out, to change character sets associated with specific code values.For instance, under compound text, the control sequence "ESC$(B" can be used to indicate the start of Japanese 16-bit data in a data stream of characters, and "ESC(B" can be used to indicate the end of this double-byte character data and the start of 8-bit ASCII data. Under this stateful encoding, the bit value 0x43 could not be interpreted without knowing the shift state. The EBCDIC Asian code sets use shift-in/shift-out controls to swap between double- and single-byte encodings, respectively. Converters that are written to do the conversion of stateful encodings to other code sets tend to be a little complex due to the extra processing needed. Stateless EncodingsStateless code sets are those that can be classified as one of two types:
Note: Conversions are meaningful only if the code sets represent the same character set. Simple Text Basic InterchangeWhen a program communicates data to another program residing on a remote host, a need may arise for conversion of data from the code set of the source machine to that of the receiver. For example, this happens when a PC system using PC codes needs to communicate with a workstation using an International Organization for Standardization/Extended UNIX Code (ISO/EUC) encoding. Another example occurs when a program obtains data in one code set but has to display this data in another code set. To support these conversions, a standard program interface is provided based on the XPG4 iconv() function definitions.All components doing code set conversion should use the iconv functions as their interface to conversions. Systems are expected to provide a wide variety of conversions, as well as a mechanism to customize the default set of conversions. iconv Conversion FunctionsThe common method of conversions from one code set to another is through a table-driven method. In some cases, these tables may be too large, hence an algorithmic method may be more desirable. To accommodate such diverse requirements, a framework is defined in XPG4 for code set conversions. In this framework, to convert from one code set to another, open a converter, perform the conversions, and close the converter. The iconv functions are iconv_open(), iconv(), and iconv_close().Code set converters are brought under the framework of the iconv_open(), iconv(), and iconv_close() set of functions. With these functions, it is possible to provide and to use several different types of converters. Applications can call these functions to convert characters in one code set into characters in another code set. With the advent of the iconv framework, converters can be provided in a uniform manner. The access and use of these converters is being standardized under X/Open XPG4. X Interclient (ICCCM) Conversion FunctionsXlib provides the following functions for doing conversions.
Note: The libXm library does provide the XmStringConvertToCT() and XmStringConvertFromCT() functions; however, these are not recommended because there are some hardcoded assumptions about certain XmString tags. For example, if the tag is bold, XmStringConvertToCT() is implementation-dependent. Across various platforms, the behavior of this function cannot be guaranteed in all international regions.
Refer to "Interclient Communications Conventions for Localized Text" for more information. Window TitlesThe standard way for setting titles is to use resources. But for applications that set the titles of their windows directly, a localized title must be sent to the Window Manager. Use the XCompoundTextStyle encoding defined in XICCEncodingStyle, as well as the following guidelines:
If you are using a window rather than widgets, the XmbSetWMProperties() function automatically converts a localized string into the proper XICCEncodingStyle.Mail Basic InterchangeIn general, electronic mail (email) strategy has been one of turning email into a canonical, labeled format as opposed to optimizing a message given knowledge of the receiver's locale. This means that in the email world, you should always assume that the receiver may be in a different locale. In the desktop world, the default email transport is Simple Mail Transfer Protocol (SMTP), which only supports 7-bit transmission channels.With this understanding, the email strategy for the desktop is as follows:
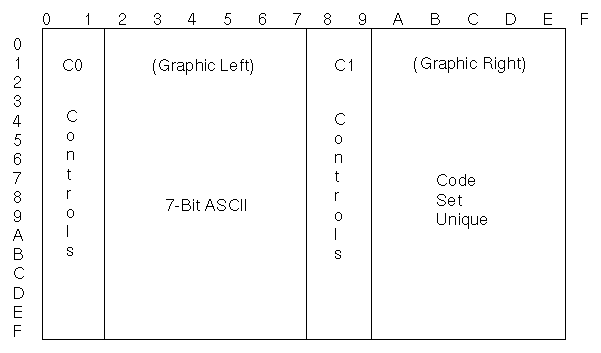
Encodings and Code SetsTo understand code sets, it is necessary to first understand character sets. A character set is a collection of predefined characters based on the specific needs of one or more languages without regard to the encoding values used to represent the characters. The choice of which code set to use depends on the user's data processing requirements. A particular character set can be encoded using different encoding schemes. For example, the ASCII character set defines the set of characters found in the English language. The Japanese Industrial Standard (JIS) character set defines the set of characters used in the Japanese language. Both the English and Japanese character sets can be encoded using different code sets.The ISO2022 standard defines a coded character set as a group of precise rules that defines a character set and the one-to-one relationship between each character and its bit pattern. A code set defines the bit patterns that the system uses to identify characters. Code Set StrategyThe common open software environment code set support is based on International Organization for Standardization (ISO) and industry-standard code sets providing industry-standard code sets that satisfy the data processing needs of users.Each locale in the system defines which code set it uses and how the characters within the code set are manipulated. Because multiple locales can be installed on the system, multiple code sets can be used by different users on the system. While the system can be configured with locales using different code sets, all system utilities assume that the system is running under a single code set. Most commands have no knowledge of the underlying code set being used by the locale. The knowledge of code sets is hidden by the code-set-independent library subroutines (Internationalization libraries), which pass information to the code-set-dependent subroutines. Because many programs rely on ASCII, all code sets include the 7-bit ASCII code set as a proper subset. Because the 7-bit ASCII code set is common to all supported code sets, its characters are sometimes referred to as the portable character set. The 7-bit ASCII code set is based on the ISO646 definition and contains the control characters, punctuation characters, digits (0-9), and the English alphabet in uppercase and lowercase. Code Set StructureEach code set is divided into two principle areas:
Note: The PC code sets use the C1 control area to encode graphic characters. The remaining six columns are used to encode graphic characters (see Table 3-2). Graphic characters are considered to be printable characters, while the control characters are used by devices and applications to indicate some special function
Table 3-2 Code Set Overview Control CharactersBased on the ISO definition, a control character initiates, modifies, or stops a control operation. A control character is not a graphic character, but can have graphic representation in some instances. The control characters in the ISO646-IRV character set are present in all supported code sets,and the encoded values of the C0 control characters are consistent throughout the code sets.Graphic CharactersEach code set can be considered to be divided into one or more character sets, such that each character is given a unique coded value. The ISO standard reserves six columns for encoding characters and does not allow graphic characters to be encoded in the control character columns.Single-Byte Code SetsCode sets that use all 8 bits of a byte can support European, Middle Eastern, and other alphabetic languages. Such code sets are called single-byte code sets. This provides a limit of encoding 191 characters, not including control characters.Multibyte Code SetsThe term multibyte code sets is used to refer to all possible code sets regardless of the number of bytes needed to encode any specific character. Because the operating system should be capable of supporting any number of bits to encode a character, a multibyte code set may contain characters that are encoded with 8, 16, 32, or more bits. Even single-byte code sets are considered to be multibyte code sets.Extended UNIX Code (EUC) Code SetThe EUC code set uses control characters to identify characters in some of the character sets. The encoding rules are based on the ISO2022 definition for the encoding of 7-bit and 8-bit data. The EUC code set uses control characters to separate some of the character sets.The term EUC denotes these general encoding rules. A code set based on EUC conforms to the EUC encoding rules but also identifies the specific character sets associated with the specific instances. For example, eucJP for Japanese refers to the encoding of the JIS characters according to the EUC encoding rules. The first set (CS0) always contains an ISO646 character set. All of the other sets must have the most-significant bit (MSB) set to 1, and they can use any number of bytes to encode the characters. In addition, all characters within a set must have:
Each character in the fourth set (CS3) is always preceded with the control character SS3 (single-shift 3, 0x8f). Code sets that conform to EUC do not use the SS3 control character other than to identify the fourth set. ISO EUC Code SetsThe following code sets are based on definitions set by the International Organization for Standardization (ISO).
ISO646-IRVThe ISO646-IRV code set defines the code set used for information processing based on a 7-bit encoding. The character set associated with this code set is derived from the ASCII characters.ISO8859-1ISO8859-1 encoding is a single-byte encoding that is based on and is compatible with other ISO, American National Standards Institute (ANSI), and European Computer Manufacturer's Association (ECMA) code extension techniques. The ISO8859 encoding defines a family of code sets with each member containing its own unique character sets. The 7-bit ASCII code set is a proper subset of each of the code sets in the ISO8859 family.The ISO8859-1 code set is called the ISO Latin-1 code set and consists of two character sets:
While the ASCII code set defines an order for the English alphabet, the Graphic Right (GR) characters are not ordered according to any specific language. The language-specific ordering is defined by the locale. Other ISO8859 Code SetsThis section lists the other significant ISO8859 code sets. Each code set includes the ASCII character set plus its own unique characters.
ISO8859-2Latin alphabet, No. 2, Eastern Europe
ISO8859-5Latin/Cyrillic alphabet
ISO8859-6Latin/Arabic alphabet
ISO8859-7Latin/Greek alphabet
ISO8859-8Latin/Hebrew alphabet
ISO8859-9Latin/Turkish alphabet
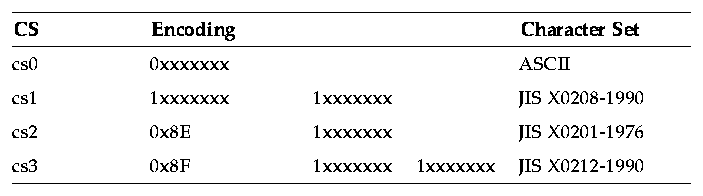
eucJPThe EUC for Japanese consists of single-byte and multibyte characters (2 and 3 bytes). The encoding conforms to ISO2022 and is based on JIS and EUC definitions, see Table 3-3.
Table 3-3 Encoding for eucJP
JIS X0208-1990A code of the Japanese graphic character set for information interchange (1990 version) that contains 147 special characters, 10 numeric digits, 83 Hiragana characters, 86 Katakana characters, 52 Latin characters, 48 Greek characters, 66 Cyrillic characters, 32 line-drawing elements, and 6355 Kanji characters.
JIS X0201A code for information interchange that contains 63 Katakana characters.
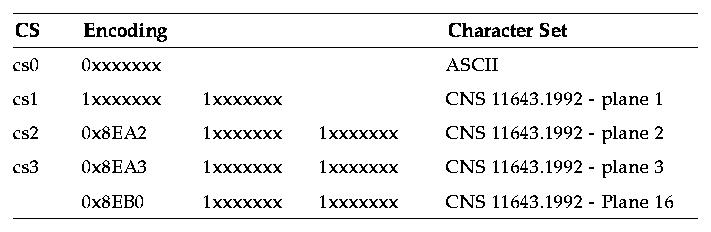
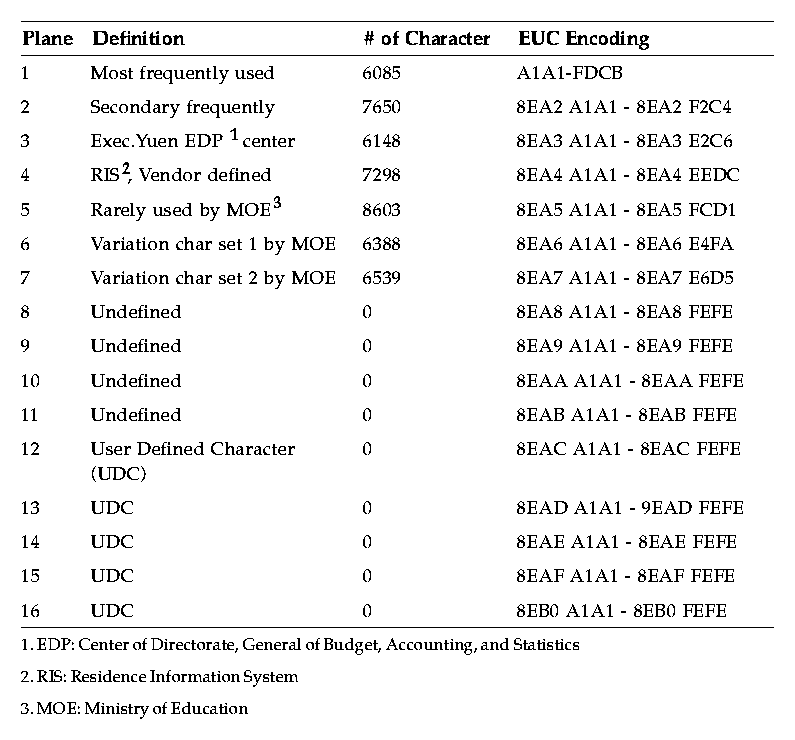
JIS X0212-1990A code of the supplementary Japanese graphic character set for information interchange (1990 version) that contains 21 additional special characters, 21 additional Greek characters, 26 additional Cyrillic characters, 27 additional Latin characters, 171 Latin characters with diacritical marks, and 5801 additional Kanji characters.eucTWThe EUC for Traditional Chinese is an encoding consisting of characters that contain single-byte and multibyte (2 and 4 bytes) characters. The EUC encoding conforms to ISO2022 and is based on the Chinese National Standard (CNS) as defined by the Republic of China and the EUC definition, see Table 3-4.
Table 3-4 Encoding for eucTW CNS 11643-1992 defines 16 planes for the Chinese Standard Interchange Code, each plane can support up to 8836 characters (94x94). Currently, only planes 1 through 7 have characters assigned. Table 3-5 shows the 16 planes of the CNS 11643-1992 standard.
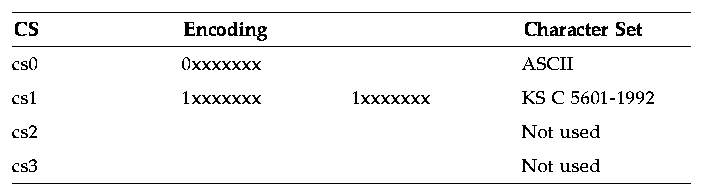
Table 3-5 16 Planes of the CNS 11643-1992 Standard eucKRThe EUC for Korean is an encoding consisting of single-byte and multibyte characters (shown in Table 3-6). The encoding conforms to ISO2022 and is based on Korean Standard Code (KSC) set and EUC definitions.
Table 3-6 Encoding for eucKR. KSC 5601-1992 (code of the Korean character set for information interchange, 1992 version) contains 432 special characters, 30 Arabic and Roman numeral characters, 94 Hangul alphabet characters, 52 Roman characters, 48 Greek characters, 27 Latin characters, 169 Japanese characters, 66 Russian characters, 68 line-drawing elements, 2344 precomposed Hangul characters, and 4888 Hanja characters. One Hangul character can be comprised of several consonants and vowels. Most Hangul words can be expressed in Hanja words. Hanja is a set of Traditional Chinese characters, which is currently used by Korean people. Each Hanja character has its own meaning and is thus more specific than Hangul most of the time.
|