この章では,DECdtm サービスを利用するソフトウェア (たとえば ACMS,Oracle Rdb,RMS Journaling など) を実行するときに必要な作業を説明します。
この章の内容
この章では次の作業について説明します。
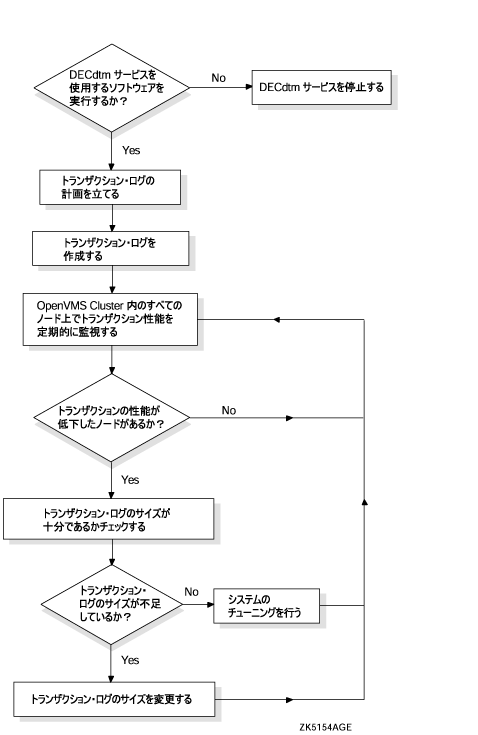
図 14-1 「DECdtm サービスの管理」 は,DECdtm サービスの管理のためのフローチャートです。
このチャートから実際に必要な作業と,その作業の順序を知ることができます。
さらに,次の項目について説明します。
トランザクション・ログとは,あるノード上で行われた DECdtm トランザクションに関する情報を格納するファイルのことです。
ファイルのタイプは .LM$JOURNAL です。
任意のノードで DECdtm トランザクションを実行する場合は,そのノードに対してトランザクション・ログを作成しておく必要があります。
OpenVMS Cluster では,クラスタ内の各ノードでトランザクション・ログを作成します。
ログ・マネージャ制御プログラム (LMCP) ユーティリティを使用して,トランザクション・ログの作成と管理を行います。
DECdtm サービスでは,トランザクション・ログの格納場所は論理名 SYS$JOURNAL によって判断されます。
トランザクション・ログを含むディレクトリを指すように,SYS$JOURNAL に定義する必要があります。
トランザクション・ログのサイズと格納場所は,トランザクションの性能に影響を及ぼします。
トランザクション・ログを作成する前に,そのサイズと格納場所を決定してください。
トランザクション・ログのサイズと格納場所は,作成した後でも変更することができます。
しかし,この段階でログの格納場所とサイズについて十分に検討しておくと,後になって変更する負担が少なくてすみます。
この節では次の作業について説明します。
14.2.1 トランザクション・ログのサイズの決定 |
 |
トランザクション・ログを作成する場合は,そのサイズをブロック単位で指定することができます。
省略時のサイズは 4,000 ブロックです。
この値に設定すれば,ほとんどのシステムで十分な性能を得ることができます。
トランザクションの平均発生数が予想できる場合,トランザクション・ログのサイズは以下の計算式で求めることができます。
トランザクションの平均発生数が分からない場合には,省略時の値の 4,000 ブロックを採用します。
14.2.2 トランザクション・ログの格納場所の決定 |
|
できれば,以下の属性を持つディスクに置いてください。
速度と可用性または信頼性のいずれかとの間で選択を行う必要があることがあります。
たとえば,ノードがワークステーションの場合には,可用性と信頼性のために速度を犠牲にして,ワークステーションに接続されたディスクではなく,それより低速の HSC ベースのシャドウ・ディスク上にノードのトランザクション・ログを置く場合があります。
クラスタ環境では,できるだけトランザクション・ログを複数のディスクに分散させてください。
1 つのディスクに複数のトランザクション・ログが存在すると,トランザクションの性能が低下します。
この節では,DECnet-Plus ネットワークで DECdtm を使用する際に役立つ,次の情報についてまとめます。
-
-
DCEnet-Plus ネットワークでの SCSNODE 名の計画
14.3.1 DECnet-Plus ネームスペースの計画 |
|
DECdtm では,複数の DECnet-Plus ネームスペースをサポートしません。
つまり,DECdtm サービスを使用するソフトウェアを使用したい場合には,ローカル・ネームスペースと DECdns ネームスペースの両方を使用することはできません。
14.3.2 DCEnet-Plus ネットワークでの SCSNODE 名の計画 |
|
SCSNODE は,コンピュータの名前を定義するシステム・パラメータです。
DECnet-Plus ネットワークを使用しているときに,異なる OpenVMS Clusterまたは異なるスタンドアロン・コンピュータにまたがる DECdtm トランザクションを実行したい場合には,SCSNODE 名を選択する際に次の規則に従う必要があります。
DECnet-Plus ネットワークを使用していて,異なる OpenVMS Cluster または異なるスタンドアロン・コンピュータにまたがる DECdtm トランザクションを実行する場合には,SCSNODE 名が次の規則に従っているかどうかを確認する必要があります。
-
トランザクション・グループ内の各コンピュータの SCSNODE 名は,次の名前と異なる名前でなければならない。
-
トランザクション・グループ内の他のコンピュータの SCSNODE 名。
SCSNODE 名は,同じトランザクション・グループ内で一意な名前でなければならない。
-
同じローカル・ルートの他のコンピュータの DECnet 単純名。
-
ネットワーク全体の他のコンピュータの DECnet 同意語。
トランザクション・グループについての詳細は,14.3.2.2 項 「トランザクション・グループについて」を参照。
-
コンピュータが OpenVMS Cluster 内にあるときは,SCSNODE 名は次の名前と異なる名前でなければならない。
-
同じクラスタ内の他のコンピュータの DECnet 単純名。
-
他のクラスタ・メンバと同じローカル・ルートのコンピュータの DECnet 単純名。
14.3.2.2 トランザクション・グループについて
トランザクション・グループとは,DECdtm トランザクションに関係するコンピュータのグループであり,その SCSNODE 名は,14.3.2.1 項 「SCSNODE 名に関する規則」で説明する規則に従わなければなりません。
トランザクション・グループは,次のガイドラインに従います。
-
各コンピュータは 1 つのトランザクション・グループに属す。
-
OpenVMS Cluster 内のすべてのコンピュータは,同一トランザクション・グループに属す。
-
1 つのトランザクションがコンピュータ A とコンピュータ B にまたがる場合には,コンピュータ A とコンピュータ B は同一トランザクション・グループに属す。
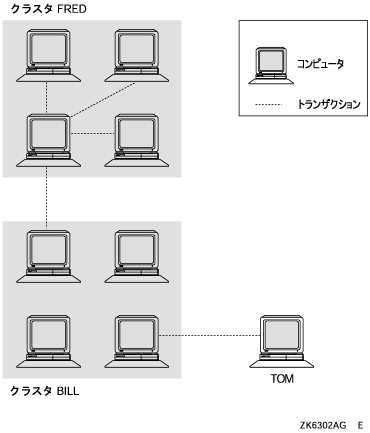
図 14-2 「トランザクション・グループ」 は,トランザクション・グループの例を示しています。
この図で,9 台のコンピュータはすべて同じトランザクション・グループに属します。
これは次の理由によります。
-
トランザクションは,クラスタ FRED 内のコンピュータとクラスタ BILL 内のコンピュータにまたがっている。
つまり,クラスタ FRED 内の 4 台のコンピュータと,クラスタ BILL 内の 4 台のコンピュータは,同じトランザクション・グループに属す。
-
トランザクションは,スタンドアロン・コンピュータ TOM とクラスタ BILL 内のコンピュータにまたがっている。
つまり,スタンドアロン・コンピュータ TOM は,クラスタ BILL 内のコンピュータと同じトランザクション・グループに属す。
任意のノードで DECdtm サービスを利用する場合は,そのノードに対してトランザクション・ログを作成する必要があります。
OpenVMS Cluster 環境では,ノードごとにトランザクション・ログを作成します。
作業方法
-
14.2 項 「トランザクション・ログの計画」 のガイドラインに従って,ノードごとにトランザクション・ログのサイズと格納場所を決定する。
ディスクにはトランザクション・ログを格納するのに十分な連続領域が存在する必要がある。
-
クラスタ環境の場合,トランザクション・ログを作成するディスクがクラスタ全体でマウントされていることを確認する。
-
トランザクション・ログを作成するディレクトリを決定する。
必要であれば,トランザクション・ログ専用のディレクトリを作成する。
-
次のようにトランザクション・ログのディレクトリを SYS$JOURNAL に定義する。
DO DEFINE/SYSTEM/EXECUTIVE_MODE SYS$JOURNAL ディレクトリ指定 [,...]
ここで,ディレクトリ指定 は,作成する 1 つ以上のトランザクション・ログを格納するディレクトリの完全ファイル指定である。
このとき,トランザクション・ログを格納するすべてのディレクトリを指定する必要がある。
指定する順序は自由。
クラスタ環境では,SYSMAN を使用して SYS$JOURNAL をクラスタ全体で定義する。
-
コマンド・プロシージャ SYS$MANAGER:SYLOGICALS.COM に,SYS$JOURNAL の定義を追加する。
独自の SYLOGICALS.COM を使用しているすべてのノードで同じ作業を行う。
-
LMCP の CREATE LOG コマンドを使用して,ノードごとに 1 つのトランザクション・ログを作成する。
CREATE LOG [/SIZE= サイズ ] ディレクトリ指定 SYSTEM$ ノード.LM$JOURNAL
-
DECdtm サービスを次のように開始する。
手順 | 作業 |
|---|
a. | 論理名 SYS$DECDTM_INHIBIT が定義されているかどうかを調べる。
$ SHOW LOGICAL SYS$DECDTM_INHIBIT
|
|
b. | SYS$DECDTM_INHIBIT の定義状態
|
例
この例では,OpenVMS Cluster 内のノード (SCSNODE 名が BLUE および RED) にトランザクション・ログを作成する方法を示します。
どちらのノードも,ノード固有のSYLOGICALS.COM を使用していないものとします。
トランザクション・ログの格納場所とサイズを次にように決定します。
ノード | ログのサイズ (ブロック数) | ディスク |
|---|
BLUE | 5000 | DUA1 |
RED | 4000 | DUA2 |
ディスクをクラスタ全体でマウントします。
$ MOUNT/CLUSTER/SYSTEM DUA1: LOG1
$ MOUNT/CLUSTER/SYSTEM DUA2: LOG2
|
トランザクション・ログ用のディレクトリを作成します。
$ CREATE/DIRECTORY DISK$LOG1:[LOGFILES]
$ CREATE/DIRECTORY DISK$LOG2:[LOGFILES]
|
SYS$JOURNAL を定義します。
$ RUN SYS$SYSTEM:SYSMAN
SYSMAN> SET ENVIRONMENT/CLUSTER
SYSMAN> DO DEFINE/SYSTEM/EXECUTIVE_MODE SYS$JOURNAL -
_SYSMAN> DISK$LOG1:[LOGFILES], DISK$LOG2:[LOGFILES]
SYSMAN> EXIT
|
コマンド・プロシージャSYS$MANAGER:SYLOGICALS.COM に以下の行を追加します。
$ !
$ DEFINE/SYSTEM/EXECUTIVE_MODE SYS$JOURNAL DISK$LOG1:[LOGFILES], -
_$DISK$LOG2:[LOGFILES]
$ !
|
トランザクション・ログを作成します。
$ RUN SYS$SYSTEM:LMCP
LMCP> CREATE LOG/SIZE=5000 DISK$LOG1:[LOGFILES]SYSTEM$BLUE.LM$JOURNAL
LMCP> CREATE LOG DISK$LOG2:[LOGFILES]SYSTEM$RED.LM$JOURNAL
LMCP> EXIT
|
DECdtm サービスが開始されたことを確認します。
$ SHOW LOGICAL SYS$DECDTM_INHIBIT
%SHOW-S-NOTRAN, no translation for logical name SYS$DECDTM_INHIBIT
|
SYS$DECDTM_INHIBIT が定義されていないため,DECdtm サービスが使用できます。
負荷の増加など,システム構成を変更することでトランザクション性能に影響がでることがあります。
毎月一度はノード上でトランザクションを監視し,トランザクション性能が低下していないことを確認してください。
OpenVMS Cluster 環境では,クラスタ内のすべてのノードでトランザクション性能を監視してください。
作業方法
-
MONITOR ユーティリティの MONITOR TRANSACTIONS コマンドを使用してトランザクションを監視する。
MONITOR TRANSACTION/SUMMARY[= ファイル指定 ]
/ENDING= 終了時刻 /NODE= ノード名 [,...]
最適な情報を得るためには,トランザクションの監視を 24 時間連続して行うこと。
MONITOR TRANSACTION コマンドをコマンド・プロシージャに追加すれば,トランザクションの監視をバッチ・モードで行うことができる。
MONITOR TRANSACTION コマンドについての詳細は,『OpenVMS システム管理 ユーティリティ・リファレンス・マニュアル』を参照。
-
要約ファイルを調査する。
要約ファイルには,いくつかの異なるデータ項目の値が含まれている。
各ノードについて,以下の項目に注目する。
-
-
実行時間 (発生から終了までの時間) 別のトランザクション数の平均。
以上の値をメモしておく。
-
今回の監視セッションの結果を前回のセッションの結果と比較する。
作業負荷が変化していなければ,トランザクションの発生数と実行時間はほとんど同じはずである。
次のような場合は性能が低下していると考えられる。
-
1 秒あたりに終了したトランザクション数の平均値が小さくなっている。
-
トランザクションの実行時間の平均値が大きくなっている。
トランザクションの実行時間の平均値が大きくなっているかどうかを調べるには,実行時間別のトランザクションの平均数を比較する。
実行時間が長くなったトランザクションが多ければ,実行時間の平均値が大きくなっていることになる。
いくつかの監視セッションを通じて各値がどのように変化したかを調べる。
1 つの監視セッションから次の監視セッションの間に見られる変化は,システム上の作業負荷の変化が原因であることが考えられる。
任意のノードでトランザクション性能が低下したと考えられる場合は,そのトランザクション・ログのサイズが十分かどうかチェックする (14.6 項 「トランザクション・ログのサイズが十分かどうかのチェック」を参照)。
トランザクション・ログのサイズが十分であるにもかかわらず,トランザクション性能が低下している場合は,システムのチューニングを検討する。
システムのチューニングについての詳細は,『OpenVMS Performance Management』を参照。
例
この例では BLUE と RED の 2 つのノードを持つ OpenVMS Cluster のトランザクション性能を監視しています。
ノード BLUE と RED のトランザクションは 24 時間連続して監視します。
$ MONITOR TRANSACTION/SUMMARY=DISK$LOG1:[LOGFILES]TRANSACTIONS.SUM -
_$ /ENDING="+1-"/NODE=(BLUE,RED)
|
要約ファイルを調べます。
DISTRIBUTED TRANSACTION STATISTICS
on node BLUE From: 16-OCT-2000 14:23:51
SUMMARY To: 17-OCT-2000 14:23:51
CUR AVE MIN MAX
Start Rate 49.02 43.21 31.30 49.02
Prepare Rate 48.70 43.23 30.67 48.70
One Phase Commit Rate 0.00 0.00 0.00 0.00
Total Commit Rate 48.70 43.19 31.30 48.70
Abort Rate 0.00 0.00 0.00 0.00
End Rate 48.70 43.19 31.30 48.70
Remote Start Rate 0.00 0.00 0.00 0.00
Remote Add Rate 0.00 0.00 0.00 0.00
Completion Rate 0-1 21.42 13.57 0.63 21.42
by Duration 1-2 25.97 29.15 24.59 33.87
in Seconds 2-3 1.29 0.47 0.00 4.47
3-4 0.00 0.00 0.00 0.00
4-5 0.00 0.00 0.00 0.00
5+ 0.00 0.00 0.00 0.00
SUMMARIZING
DISTRIBUTED TRANSACTION STATISTICS
on node RED From: 16-OCT-2000 14:23:52
SUMMARY To: 17-OCT-2000 14:23:52
⋮
|
以下の値に注目します。
-
平均終了トランザクション数。
ノード BLUE の場合,1 秒あたり平均 43.19 のトランザクションが終了している。
-
実行時間別平均トランザクション数。
ノード BLUE の場合は以下のとおり。
-
0 ~ 1 秒で終了したトランザクション数は 13.57
-
1 ~ 2 秒で終了したトランザクション数は 29.15
-
2 ~ 3 秒で終了したトランザクション数は 0.47
今回の監視セッションの結果を以前のセッションの結果と比較します。
セッション | 終了数 | 実行時間別トランザクション数 |
|---|
| | | 0 ~ 1 秒 | 1 ~ 2 秒 | 2 ~ 3 秒 |
|---|
6 月 | 42.13 | 12.98 | 28.13 | 1.02 |
7 月 | 38.16 | 10.35 | 25.80 | 2.01 |
8 月 | 43.19 | 13.57 | 29.15 | 0.47 |
ノード BLUE のデータを見るかぎり,性能が低下した兆候は見られません。
トランザクション性能が低下しているノードが見つかった場合は,そのノードのトランザクション・ログのサイズが十分かどうかを調べる必要があります。
14.5 項 「トランザクション性能の監視」 では,トランザクション性能の低下を発見する方法を説明しています。
作業方法
-
トランザクション・ログが置かれているノードにログインする。
-
LMCP ユーティリティの SHOW LOG/CURRENT コマンドを使用して,トランザクション・ログがストールした回数を調べる。
$ RUN SYS$SYSTEM:LMCP
LMCP> SHOW LOG/CURRENT
|
表示されたチェックポイントと発生したストールの数に注目する。
-
5 分後に SHOW LOG/CURRENT コマンドを繰り返し実行する。
実行後,チェックポイントとストールの数に再び注目する。
-
SHOW LOG/CURRENT コマンドからの情報と比較する。
2 回のチェックでチェックポイントの数が同じ場合は,システムの負荷が大きい時間に同じ作業をもう一度行う。
チェックポイントの数が増え,さらにストールの回数が1 回以上増えている場合は,トランザクション・ログが小さすぎるといえる。
-
トランザクション・ログのサイズが小さいときは,そのサイズを大きくする。
トランザクション・ログのサイズを変更する方法については,14.7 項 「トランザクション・ログのサイズの変更」を参照。
例
ノード BLUE のトランザクション・ログのサイズが不十分かどうかを調べます。
ノード BLUE にログインし,トランザクション・ログがストールした回数を調べます。
$ RUN SYS$SYSTEM:LMCP
LMCP> SHOW LOG/CURRENT
Checkpoint starts/ends 2464/2464
Stall starts/ends 21/21
Log status: no checkpoint in progress, no stall in progress.
|
チェックポイントの数は 2,464 で,トランザクションのストール回数は 21 回であることが分かります。
5 分後,SHOW LOG/CURRENT コマンドをもう一度入力します。
LMCP> SHOW LOG/CURRENT
Checkpoint starts/ends 2514/2514
Stall starts/ends 28/28
Log status: no checkpoint in progress, no stall in progress.
|
チェックポイントの数が増え,さらにトランザクション・ログが現在 28 回ストールしており,ストール回数が 5 分間に 7 回増えていることが分かります。
したがって,トランザクション・ログのサイズが不十分であるといえます。
トランザクション・ログのサイズが不十分な場合,そのサイズを大きくする必要があります。
14.6 項 「トランザクション・ログのサイズが十分かどうかのチェック」を参照してください。
作業方法
-
トランザクション・ログに対応するノードにログインする。
-
LMCP の SHOW LOG コマンドを使用して,トランザクション・ログが置かれているディレクトリを探す。
SHOW LOG SYSTEM$ノード.LM$JOURNAL
ノードは,トランザクション・ログが置かれているノードの名前。
-
トランザクション・ログをリネームする。
RENAME ディレクトリ指定 SYSTEM$ ノード .LM$JOURNAL ディレクトリ指定 SYSTEM$ ノード.LM$OLD
-
ノードを全くシャットダウンしないで DECdtm サービスを使用しているすべてのソフトウェアを停止できるか。
可能な場合は,次のようにトランザクション・ログを閉じる。
不可能な場合は,ノードをリブートしてトランザクション・ログを閉じる。
リブートされたらノードにログインする。
-
LMCP ユーティリティの CONVERT LOG コマンドを使用して,トランザクション・ログのサイズを変更する。
CONVERT LOG/SIZE= サイズ SYSTEM$ ノード.LM$OLD
ディレクトリ指定 SYSTEM$ ノード.LM$JOURNAL
-
ステップ 4 で DECdtm サービスを使用しているソフトウェアを停止した場合は,そのソフトウェアを再起動する。
-
旧トランザクション・ログを削除する。
DELETE ディレクトリ指定 SYSTEM$ ノード.LM$OLD;
例
この例は,ノード RED のトランザクション・ログのサイズを 6000 ブロックに変更しています。
ノード RED は OpenVMS Cluster 内に存在し,そのトランザクション・ログは DISK$LOG2:[LOGFILES] に置かれています。
ノード RED にログインします。
RED のトランザクション・ログが置かれているディレクトリを探し,そのトランザクション・ログの名前を変更します。
$ RUN SYS$SYSTEM:LMCP
LMCP> SHOW LOG SYSTEM$RED.LM$JOURNAL
Directory of DISK$LOG2:[LOGFILES]
SYSTEM$RED.LM$JOURNAL;1
Total of 1 file.
LMCP> EXIT
$ RENAME DISK$LOG2:[LOGFILES]SYSTEM$RED.LM$JOURNAL -
_$ DISK$LOG2:[LOGFILES]SYSTEM$RED.LM$OLD
|
DECdtm サービスを使用しているすべてのソフトウェアを終了します。
次に,トランザクション・ログを閉じます。
$ RUN SYS$SYSTEM:LMCP
LMCP> CLOSE LOG
Transaction log closed, TP_SERVER process stopped
LMCP> EXIT
|
TP_SERVER プロセスを再起動します。
$ @ SYS$STARTUP:DECDTM$STARTUP.COM
|
トランザクション・ログのサイズを変更します。
$ RUN SYS$SYSTEM:LMCP
LMCP> CONVERT LOG/SIZE=6000 DISK$LOG2:[LOGFILES]SYSTEM$RED.LM$OLD -
_LMCP> DISK$LOG2:[LOGFILES]SYSTEM$RED.LM$JOURNAL
Log file DISK$LOG2:[LOGFILES]SYSTEM$RED.LM$JOURNAL;1 created.
Log file DISK$LOG2:[LOGFILES]SYSTEM$RED.LM$OLD converted.
LMCP> EXIT
|
DECdtm サービスを使用するソフトウェアを再起動します。
旧トランザクション・ログを削除します。
$ DELETE DISK$LOG2:[LOGFILES]SYSTEM$RED.LM$OLD;
|
次の場合には,トランザクション・ログを移動します。
-
トランザクション・ログをより高速なディスク上に置きたい。
-
作業方法
-
14.2.2 項 「トランザクション・ログの格納場所の決定」 で示したガイドラインに従って,トランザクション・ログの移動先を決定する。
ディスクにはトランザクション・ログを格納するのに十分な連続領域が存在する必要がある。
-
トランザクション・ログが置かれているノードにログインする。
-
OpenVMS Cluster 環境の場合,トランザクション・ログを移動するディスクが,クラスタ全体でマウントされていることを確認する。
-
トランザクション・ログの移動先のディレクトリを決定する。
必要であれば,トランザクション・ログ専用のディレクトリを作成する。
-
LMCP の SHOW LOG コマンドを使用して,トランザクション・ログが置かれているディレクトリを探す。
SHOW LOG SYSTEM$ ノード.LM$JOURNAL
ノードは,トランザクション・ログが置かれているノードの名前。
-
トランザクション・ログをリネームする。
RENAME ディレクトリ指定 SYSTEM$ ノード.LM$JOURNAL
ディレクトリ指定 SYSTEM$ ノード.LM$OLD
-
ノードを全くシャットダウンしないで DECdtm サービスを使用しているすべてのソフトウェアを停止できるか。
可能な場合は,次のようにトランザクション・ログを閉じる。
手順 | 作業 |
|---|
a. | DECdtm サービスを使用しているすべてのソフトウェアを終了する。 |
b. | LMCP の CLOSE LOG コマンドを使用して,トランザクション・ログを閉じる。
$ RUN SYS$SYSTEM:LMCP
LMCP> CLOSE LOG
|
CLOSE LOG コマンドはトランザクション・ログを閉じてから DECdtm TP_SERVER プロセスを終了する。
DECdtm サービスを使用しているソフトウェアが1 つでもあれば コマンドは失敗する。 |
c. | CLOSE LOG コマンドの実行に成功したか。
- 成功
TP_SERVER プロセスを再起動する。
$ @SYS$STARTUP:DECDTM$STARTUP.COM
|
- 失敗
30 秒間待ってから手順 7b および 7c を繰りかえす。
|
不可能な場合は,ノードをリブートしてトランザクション・ログを閉じる。
リブートされたらノードにログインする。
-
論理名 SYS$JOURNAL に,ログの移動先のディレクトリが定義されていることを確認する。
定義されていない場合は,SYS$JOURNAL を再定義する。
DO DEFINE/SYSTEM/EXECUTIVE_MODE SYS$JOURNAL ディレクトリ指定 [,...]
ここで,ディレクトリ指定 は 1 つまたは複数のトランザクション・ログを格納するディレクトリの完全ファイル指定である。
トランザクション・ログの移動後にトランザクション・ログを格納するすべてのディレクトリを指定する。
ディレクトリの順序は自由。
OpenVMS Cluster 環境では,SYSMAN を使用して SYS$JOURNAL をクラスタ全体で再定義する必要がある。
-
ステップ 8 で SYS$JOURNAL を再定義した場合は,それに合わせてコマンド・プロシージャSYS$MANAGER:SYLOGICALS.COMの 中の SYS$JOURNAL の定義を更新する。
ノード独自の SYLOGICALS.COM を作成している場合は,そのコマンド・プロシージャのすべてを更新する。
-
LMCP ユーティリティの CONVERT LOG コマンドを使用して,トランザクション・ログを移動する。
CONVERT LOG 古いディレクトリ指定 SYSTEM$ ノード.LM$OLD
新しいディレクトリ指定 SYSTEM$ ノード.LM$JOURNAL
-
ステップ 7 で DECdtm サービスを使用しているソフトウェアを停止した場合は,そのソフトウェアを再起動する。
-
旧トランザクション・ログを削除する。
DELETE ディレクトリ指定 SYSTEM$ ノード.LM$OLD;
例
この例は,BLUE のトランザクション・ログの移動方法を紹介しています。
BLUE は OpenVMS Cluster 内に存在します。
クラスタ・メンバおよびトランザクション・ログの格納場所を次のように想定しています。
ノード | ログを格納するディレクトリ |
|---|
BLUE | DISK$LOG1:[LOGFILES] |
RED | DISK$LOG2:[LOGFILES] |
どちらのノードも独自の SYLOGICALS.COM を使用していないものとします。
BLUE のトランザクション・ログの移動先を決定します。
この例では,DISK$LOG3:[LOGFILES] に移動します。
ノード BLUE にログインします。
次にディスクをクラスタ全体でマウントしてから,トランザクション・ログ用に新しいディレクトリを作成します。
$ MOUNT/CLUSTER/SYSTEM DUA3: LOG3
$ CREATE/DIRECTORY DISK$LOG3:[LOGFILES]
|
BLUE のトランザクション・ログが置かれているディレクトリを探し,トランザクション・ログの名前を変更します。
$ RUN SYS$SYSTEM:LMCP
LMCP> SHOW LOG SYSTEM$BLUE.LM$JOURNAL
Directory of DISK$LOG1:[LOGFILES]
SYSTEM$BLUE.LM$JOURNAL;1
Total of 1 file.
LMCP> EXIT
$ RENAME DISK$LOG1:[LOGFILES]SYSTEM$BLUE.LM$JOURNAL -
_$ DISK$LOG1:[LOGFILES]SYSTEM$BLUE.LM$OLD
|
DECdtm サービスを使用しているすべてのソフトウェアを終了します。
次にトランザクション・ログを閉じます。
$ RUN SYS$SYSTEM:LMCP
LMCP> CLOSE LOG
Transaction log closed, TP_SERVER process stopped
LMCP> EXIT
|
TP_SERVER プロセスを再起動します。
$ @SYS$STARTUP:DECDTM$STARTUP.COM
|
SYS$JOURNAL を再定義します。
$ RUN SYS$SYSTEM:SYSMAN
SYSMAN> SET ENVIRONMENT/CLUSTER
SYSMAN> DO DEFINE/SYSTEM/EXECUTIVE_MODE SYS$JOURNAL -
_SYSMAN> DISK$LOG2:[LOGFILES], DISK$LOG3:[LOGFILES]
SYSMAN> EXIT
|
コマンド・プロシージャ SYS$MANAGER:SYLOGICALS.COMの SYS$JOURNAL の定義内容を更新します。
その後,トランザクション・ログを移動します。
$ RUN SYS$SYSTEM:LMCP
LMCP> CONVERT LOG DISK$LOG1:[LOGFILES]SYSTEM$BLUE.LM$OLD -
_LMCP> DISK$LOG3:[LOGFILES]SYSTEM$BLUE.LM$JOURNAL
Log file DISK$LOG3:[LOGFILES]SYSTEM$BLUE.LM$JOURNAL;1 created.
Log file DISK$LOG1:[LOGFILES]SYSTEM$BLUE.LM$OLD converted.
LMCP> EXIT
|
DECdtm サービスを使用するソフトウェアを再起動します。
次に旧トランザクション・ログを削除します。
$ DELETE DISK$LOG1:[LOGFILES]SYSTEM$BLUE.LM$OLD;
|
ディスクをディスマウントするには,ディスク上のトランザクション・ログをすべて閉じておく必要があります。
ここでは,トランザクション・ログを持っているディスクのディスマウント方法を説明します。
作業方法
-
LMCP の SHOW LOG コマンドを使用して,ディスマウントしたいディスク上に置かれているトランザクション・ログを探す。
$ RUN SYS$SYSTEM:LMCP
LMCP> SHOW LOG
|
-
ノードを全くシャットダウンしないで,DECdtm サービスを使用しているすべてのソフトウェアを終了する。
ソフトウェアを終了できなければ,ステップ 3 で 1 つまたは複数のノードをリブートする必要がある。
-
ディスク上の各トランザクション・ログに対して次のステップを実行する。
-
トランザクション・ログが置かれているノードにログインする。
-
トランザクション・ログの名前を変更する。
RENAME ディレクトリ指定 SYSTEM$ ノード.LM$JOURNAL
ディレクトリ指定 SYSTEM$ ノード.LM$TEMP
-
DECdtm サービスを使用しているすべてのソフトウェアをステップ 2 で終了したか。
終了済みの場合は,次のようにトランザクション・ログを閉じる。
手順 | 作業 |
|---|
1) | LMCP の CLOSE LOG コマンドを使用してトランザクション・ログを閉じる。
$ RUN SYS$SYSTEM:LMCP
LMCP> CLOSE LOG
|
CLOSE LOG コマンドはトランザクション・ログを閉じてから DECdtm TP_SERVER プロセスを終了する。
DECdtm サービスを使用しているソフトウェアが 1 つでもあれば コマンドは失敗する。 |
2) | CLOSE LOG コマンドの実行に成功したか。
- 成功
TP_SERVER プロセスを再起動する。
$ @SYS$STARTUP:DECDTM$STARTUP.COM
|
- 失敗
30 秒間待ってから手順 3c を繰り返す。
|
未終了の場合は,ノードをリブートしてトランザクション・ログを閉じる。
リブートされたらノードにログインする。
-
ディスクをディスマウントする。
ディスクのディスマウントに関しては,14.9 項 「ディスクのディスマウント」を参照。
-
ディスクを再度マウントしたいときは,次のステップを実行する。
-
ディスクをマウントする。
ディスクのマウントに関しては,『OpenVMS システム管理 ユーティリティ・リファレンス・マニュアル(上巻)』 を参照。
クラスタの場合は,クラスタ全体でディスクをマウントする。
-
ディスク上の各トランザクション・ログの名前を変更する。
RENAME ディレクトリ指定 SYSTEM$ ノード.LM$TEMP
ディレクトリ指定 SYSTEM$ ノード.LM$JOURNAL
-
DECdtm サービスを使用するソフトウェアを終了した場合は,そのソフトウェアを再起動する。
例
次の例は,ディスク DISK$LOG3 のディスマウントの方法を説明しています。
ディスク上にあるトランザクション・ログを探す。
$ RUN SYS$SYSTEM:LMCP
LMCP> SHOW LOG
⋮
Directory of DISK$LOG3:[LOGFILES]
SYSTEM$BLUE.LM$JOURNAL;1
|
DISK$LOG3 上に存在するトランザクション・ログは,ノード BLUE のトランザクション・ログだけである。
DECdtm サービスを使用するすべてのソフトウェアを終了する。
ノード BLUE にログインする。
次にトランザクション・ログの名前を変更する。
$ RENAME DISK$LOG3:[LOGFILES]SYSTEM$BLUE.LM$JOURNAL -
_$ DISK$LOG3:[LOGFILES]SYSTEM$BLUE.LM$TEMP
|
トランザクション・ログを閉じる。
$ RUN SYS$SYSTEM:LMCP
LMCP> CLOSE LOG
Transaction log closed, TP_SERVER process stopped
LMCP> EXIT
|
TP_SERVER プロセスを再起動する。
$ @SYS$STARTUP:DECDTM$STARTUP.COM
|
ディスクをディスマウントする。
$ DISMOUNT/CLUSTER DISK$LOG3:
|
ディスクを再度マウントしたいときは,クラスタ全体でマウントする。
MOUNT/CLUSTER/SYSTEM DUA3: LOG3
|
BLUE のトランザクション・ログの名前を変更する。
$ RENAME DISK$LOG3:[LOGFILES]SYSTEM$BLUE.LM$TEMP -
_$ DISK$LOG3:[LOGFILES]SYSTEM$BLUE.LM$JOURNAL
|
DECdtm サービスを使用するソフトウェアを再起動する。
OpenVMS Cluster に追加したすべてのノードで,新しいトランザクション・ログを作成する必要があります。
この節では,新規ノードでのトランザクション・ログの作成方法について説明します。
作業方法
この作業を実行するには,あらかじめ新規ノードをクラスタ内で構成しておく必要があります。
クラスタ内での新規ノードの構成方法については,『OpenVMS Cluster システム』を参照してください。
-
14.2 項 「トランザクション・ログの計画」 のガイドラインを使用して,新規ノードのトランザクション・ログのサイズと格納場所を決定する。
ディスクにはログを格納するのに十分な連続領域が存在する必要がある。
-
トランザクション・ログを作成するディスクが,クラスタ全体でマウントされていることを確認する。
-
新規トランザクション・ログを作成するディレクトリを決定する。
必要であれば,トランザクション・ログ専用のディレクトリを作成することもできる。
-
SYS$JOURNAL に新しいノードのトランザクション・ログを格納するディレクトリが定義されていることを確認する。
定義されていない場合は,SYSMAN を使用して SYS$JOURNAL をクラスタ全体で再定義する。
DO DEFINE/SYSTEM/EXECUTIVE_MODE SYS$JOURNAL ディレクトリ指定 [,...]
ディレクトリ指定は,トランザクション・ログを格納するディレクトリの完全指定である。
トランザクション・ログを含むすべてのディレクトリ (新規ノードのトランザクション・ログを作成するディレクトリも含める) を指定する。
ディレクトリの指定順序は自由である。
-
ステップ 4 で SYS$JOURNAL を再定義した場合は,SYS$MANAGER:SYLOGICALS.COM コマンド・プロシージャを変更して SYS$JOURNAL 定義を更新する。
ノード固有の SYLOGICALS.COM を作成した場合は,すべての SYLOGICALS.COM を変更する。
-
LMCP の CREATE LOG コマンドを使用してトランザクション・ログを作成する。
CREATE LOG [/SIZE= サイズ ] ディレクトリ指定 SYSTEM$ ノード.LM$JOURNAL
例
この例は,SCSNODE 名が WHITE である新規ノードで,トランザクション・ログを作成する方法を説明したものです。
この例では,クラスタ・メンバおよびそのトランザクション・ログの格納場所は次のとおりです。
ノード | ログを格納するディレクトリ |
|---|
BLUE | DISK$LOG3:[LOGFILES] |
RED | DISK$LOG2:[LOGFILES] |
どちらのノードもノード固有の SYLOGICALS.COM は持っていません。
WHITE のトランザクション・ログのサイズと格納場所を決定します。
ノード | ログのサイズ (ブロック数) | ディスク |
|---|
WHITE | 5000 | DUA4 |
DUA4 をクラスタ全体でマウントします。
MOUNT/CLUSTER/SYSTEM DUA4: LOG4
|
トランザクション・ログ用のディレクトリを作成します。
$ CREATE/DIRECTORY DISK$LOG4:[LOGFILES]
|
SYS$JOURNAL を再定義します。
$ RUN SYS$SYSTEM:SYSMAN
SYSMAN> SET ENVIRONMENT/CLUSTER
SYSMAN> DO DEFINE/SYSTEM/EXECUTIVE_MODE SYS$JOURNAL -
_SYSMAN> DISK$LOG2:[LOGFILES], DISK$LOG3[LOGFILES], DISK$LOG4:[LOGFILES]
SYSMAN> EXIT
|
SYS$MANAGER:SYLOGICALS コマンド・プロシージャを編集して,SYS$JOURNAL 定義を更新します。
次にトランザクション・ログを作成します。
$ RUN SYS$SYSTEM:LMCP
LMCP> CREATE LOG/SIZE=5000 DISK$LOG4:[LOGFILES]SYSTEM$WHITE.LM$JOURNAL
LMCP> EXIT
|
この節では,DECdtm サービスを使用している場合にノードを削除する方法について説明します。
作業方法
スタンドアロン・マシンを使用している場合は,ステップ 1 ~ 8 までだけを実行します。
-
削除したいノードにログインする。
-
DECdtm サービスを使用しているすべてのソフトウェアを終了する。
-
LMCP の DUMP/ACTIVE コマンドを使用して,ノードのトランザクション・ログに実行中のトランザクションが含まれているかどうかを確認する。
DUMP/ACTIVE SYSTEM$ ノード.LM$JOURNAL
ノードは削除したいノードの名前である。
このコマンドはすべての実行中のトランザクションの詳細を表示する。
最後の行には実行中のトランザクションの総数が表示される。
-
トランザクション・ログに実行中のトランザクションが含まれている場合は,以下のステップを実行する。
-
DECdtm サービスを使用しているすべてのソフトウェアで復旧プロシージャを実行する。
-
LMCP の DUMP/ACTIVE コマンドを使用して,ノードのトランザクション・ログに実行中のトランザクションがまだ含まれているかどうかを確認する。
-
トランザクション・ログに実行中のトランザクションがまだ含まれている場合は,弊社のサポート担当者に連絡する。
-
SYS$JOURNAL を再定義し,削除したいノードのトランザクション・ログを格納しているディレクトリを削除する。
ただし,ディレクトリに他のトランザクション・ログが含まれている場合を除く。
DEFINE/SYSTEM/EXECUTIVE_MODE SYS$JOURNAL ディレクトリ指定 [,...]
ここで,ディレクトリ指定 は 1 つまたは複数のトランザクション・ログを含むディレクトリの完全指定。
削除したいノードのトランザクション・ログを含むディレクトリだけでなく,トランザクション・ログを格納するすべてのディレクトリを指定する。
ディレクトリの指定順序は自由である。
クラスタの場合は,SYSMAN を使用して SYS$JOURNAL をクラスタ全体で再定義する。
-
ステップ 5 で SYS$JOURNAL を再定義した場合は,コマンド・プロシージャ SYS$MANAGER:SYLOGICALS.COM の SYS$JOURNAL の定義を更新する。
独自の SYLOGICALS.COM を使用しているノードがある場合は,そのようなノードのすべてでコマンド・プロシージャを更新する。
-
トランザクション・ログを保管する。
-
ノードをシャットダウンする。
-
DECdtm サービスを使用するソフトウェアを再起動する。
-
クラスタを再構成してノードを削除する。
クラスタの再構成に関しては,『OpenVMS Cluster システム』を参照。
例
この例は,ノード BLUE の削除方法を示しています。
クラスタ・メンバおよびトランザクション・ログの格納場所を次のように想定しています。
ノード | ログを格納するディレクトリ |
|---|
BLUE | DISK$LOG3:[LOGFILES] |
RED | DISK$LOG2:[LOGFILES] |
WHITE | DISK$LOG4:[LOGFILES] |
どのノードもノード固有の SYLOGICALS.COM コマンド・プロシージャは持っていません。
ノード BLUE にログインします。
DECdtm サービスを使用しているすべてのソフトウェアを終了します。
BLUE のトランザクション・ログに実行中のトランザクションが含まれているかどうかを確認します。
$ RUN SYS$SYSTEM:LMCP
LMCP> DUMP/ACTIVE SYSTEM$BLUE.LM$JOURNAL
Dump of log file DISK$LOG3:[LOGFILES]SYSTEM$BLUE.LM$JOURNAL
⋮
Total of 0 transactions active, 0 prepared and 0 committed.
LMCP> EXIT
|
SYS$JOURNAL を再定義します。
$ RUN SYS$SYSTEM:SYSMAN
SYSMAN> SET ENVIRONMENT/CLUSTER
SYSMAN> DO DEFINE/SYSTEM/EXECUTIVE_MODE SYS$JOURNAL -
_SYSMAN> DISK$LOG2:[LOGFILES], DISK$LOG4:[LOGFILES]
SYSMAN> EXIT
|
SYS$MANAGER:SYLOGICALS.COM
コマンド・プロシージャを編集してSYS$JOURNAL 定義を更新します。
BLUE のトランザクション・ログを保管し,ノード BLUE をシャットダウンします。
$ @SYS$SYSTEM:SHUTDOWN.COM
⋮
Should an automatic system reboot be performed [NO]? NO
|
DECdtm サービスを使用するソフトウェアを再起動します。
その後,クラスタを再構成します。
$ @SYS$STARTUP:CLUSTER_CONFIG.COM
Cluster Configuration Procedure
1. ADD a node to a cluster.
2. REMOVE a node from the cluster.
3. CHANGE a cluster member's characteristics.
4. CREATE a duplicate system disk for BLUE.
Enter choice [1]: 2
⋮
Updating network database...
The configuration procedure has completed successfully.
|
省略時の設定では,システムをブートすると DECdtm サービスが自動的に開始され,トランザクション・ログが 1 つ 見つかるまで DECdtm プロセスTP_SERVER がチェックします。
DECdtm サービスを利用するソフトウェアを現在使用しないか,使用する予定がない場合は,DECdtm サービスを停止します。
これでメモリと CPU 時間を節約することができます。
OpenVMS Cluster 内ではすべてのノードで DECdtm サービスを停止します。
作業方法
-
各ノードで以下を実行する。
-
ノードにログインする。
-
LMCP の CLOSE LOG コマンドを使用して TP_SERVER プロセスを停止する。
$ RUN SYS$SYSTEM:LMCP
LMCP> CLOSE LOG
|
CLOSE LOG コマンドは,どのソフトウェアも DECdtm サービスを使用していなければ,TP_SERVER プロセスを終了する。
CLOSE LOG コマンドが実行されなかった場合は作業を中断する。
クラスタ・システム内の別のノードで TP_SERVER プロセスの終了を完了している場合は,SYS$STARTUP:DECDTM$STARTUP.COM コマンド・プロシージャを使用してそのプロセスを再起動する。
-
次の行を SYS$MANAGER:SYLOGICALS.COM コマンド・プロシージャに追加する。
$ !
$ DEFINE/SYSTEM/EXECUTIVE_MODE SYS$DECDTM_INHIBIT yes
$ !
|
固有の SYLOGICALS.COM を使用しているノードがある場合は,そのすべてのプロシージャを変更する。
これにより TP_SERVER プロセスは,システムの次回のブート時から作成されなくなる。
ここで示す作業が必要になるのは,DECdtm サービスをいったん停止した後,DECdtm サービスを利用するソフトウェアを実行するようになった場合だけです。
作業方法
-
論理名 SYS$DECDTM_INHIBIT の指定を解除する。
$ DEASSIGN/SYSTEM/EXECUTIVE_MODE SYS$DECDTM_INHIBIT
|
OpenVMS Cluster 環境では,SYSMAN を使用してSYS$DECDTM_INHIBIT をクラスタ全体で指定解除する。
-
DECdtm サービス・プロセス TP_SERVER を起動する。
$ @SYS$STARTUP:DECDTM$STARTUP.COM
|
OpenVMS Cluster 環境では,SYSMAN を使用して TP_SERVER プロセスをクラスタ全体で起動する。
-
コマンド・プロシージャ SYS$MANAGER:SYLOGICALS.COM から,SYS$DECDTM_INHIBIT の定義を削除する。
これにより,次回のブート時から DECdtm サービスが自動的に起動されるようになる。
例
この例は,DECdtm サービスをクラスタ環境で開始する方法を説明しています。
SYS$DECDTM_INHIBIT の指定を解除してから TP_SERVER プロセスを起動します。
$ RUN SYS$SYSTEM:SYSMAN
SYSMAN> SET ENVIRONMENT/CLUSTER
SYSMAN> DO DEASSIGN/SYSTEM/EXECUTIVE_MODE SYS$DECDTM_INHIBIT
SYSMAN> DO @SYS$STARTUP.DECDTM$STARTUP.COM
SYSMAN> EXIT
|
SYS$MANAGER:SYLOGICALS.COM コマンド・プロシージャを編集して SYS$DECDTM_INHIBIT 定義を削除します。
制限事項
DECdtm は,作業を実行するために必要なオペレーティング環境がない場合,クラッシュの原因となる重大なシステム障害 (BUGCHECK) を引き起こします。
一般的な例は,仮想メモリの割り当ての障害です。
このようなエラーは,DECdtm の重大な例外として扱われるため,BUGCHECK で失敗し,結局はシステムがクラッシュします。
DECdtm は,主にそのデータ構造に依存して,トランザクションの完全性と一貫性を維持しています。
そのため,実行中にエラーや致命的な状況が発生すると,重大な矛盾として扱われます。
この結果,DECdtm は致命的な例外を発生させ,システムをクラッシュさせます。
オペレーティング環境では,仮想メモリや非ページング・プールなどのシステム・リソースに十分なバッファを確保することをお勧めします。
DECdtm を使用していない環境でクラッシュが発生した場合は,DECdtm を起動しないようにしてください。
(DECdtm を起動しないようにする方法については,14.12 項 「DECdtm サービスの停止」を参照してください。)
I64 プラットフォームでの「動的メモリ不足」に対処するための DECdtm 論理名の定義
KPB (Kernel Process Block) のメモリ割り当て中に発生する動的メモリ不足に対処するために,DECdtm 論理名が用意されています。
この設計ロジックは,リトライ・ロジックと呼ばれています。
このリトライ・ロジックでは,システム・テーブルの論理名 SYS$DECDTM_KPBALLOC_RETRYCNT を定義して,システム・サービス EXE$KP_ALLOCATE_KPB の呼び出しで戻り値が SS$_INSFMEM の場合にこのサービスを繰り返す回数 (リトライ・カウント) を設定できます。
システム論理名 SYS$DECDTM_KPBALLOC_RETRYCNT には,オプション文字列リテラル "MIN","DEF",または "MAX" を設定します。
この文字列リテラルは,リトライ・カウント MIN=25,DEF=50,および MAX=100 を示します。
論理名 SYS$DECDTM_KPBALLOC_RETRYCNT がシステム・テーブルに見つからない場合,リトライ・ロジックでは省略時のカウント DEF=50 が使用されます。
例
$ DEFINE/SYS/EXEC SYS$DECDTM_KPBALLOC_RETRYCNT MAX
DECdtm/XA は,XA を使用するトランザクションを調整し,管理するためのサポートを提供します。
XA Gateway を使用することにより,DECdtm/XA は,他のトランザクション・マネージャ (TM) によって管理されるトランザクション内の他のリソース・マネージャ (RM) を参加させることができます。
このセクションでは,DECdtm XA Gateway サポートを設定し,使用する方法について説明します。
DECdtm/XA を使用し,DECdtm/XA サービスのスタートアップおよびシャットダウンが確実に正しく実行されるようにするには,以下のファイルを起動する必要があります。
-
SYS$STARTUP:DDTM$XA_STARTUP.COM
-
SYS$STARTUP:DDTM$XA_SHUTDOWN.COM
コマンド @SYS$STARTUP:DDTM$XA_STARTUP.COM を,スタートアップ・データベースまたはコマンド・ファイル SYS$MANAGER:SYSTARTUP_VMS.COM に追加します。
コマンド @SYS$STARTUP:DDTM$XA_SHUTDOWN.COM をコマンド・ファイル SYS$MANAGER:SYSHUTDWN.COM に追加します。
以下の手順を実行して,DECdtm XA サービスが正しく実行されていることを確認します。
-
XGCP ユーティリティを使用して,ローカルの OpenVMS ノードと同じ名前のゲートウェイ・ログ・ファイルを作成する。
詳細は,14.14.1 項 「ゲートウェイの設定」および『OpenVMS システム管理 ユーティリティ・リファレンス・マニュアル』を参照。
-
SYS$TEST:DECDTM_XG_IVP.EXE を実行する。
-
XGCP ユーティリティを使用して,ゲートウェイ・サーバを終了し,再起動する。
ゲートウェイにローカルの OpenVMS ノードと異なる名前をつけて設定する場合には,この手順が必須である。
XGCP ユーティリティについての詳細は,『OpenVMS システム管理ユーティリティ・リファレンス・マニュアル (下巻) 』を参照。
14.14.1 ゲートウェイの設定 |
|
|
| |
|
 | 注記: HP DECdtm/XA Version 2.1 Gateway には現在,クラスタ単位のトランザクション回復サポートがあります。
クラスタ単位の DECdtm Gateway Domain Log を使用するアプリケーションのトランザクションは,どのような単一ノード障害からも回復できるようになりました。
障害が発生したノードの代わりに,残っているクラスタ・ノードで動作しているゲートウェイ・サーバが,トランザクション回復処理を起動できます。 |
|
| |
|
XA Gateway は,XA 対応のリソース・マネージャとして,各トランザクション処理 (TP) プロセスに設定されます。
XA Gateway は XA トランザクション・マネージャ (TM) からの XA 呼び出しを処理し,これらの呼び出しを DECdtm システム・サービスの呼び出しにマップします。
これにより,DECdtm は,1 つの TP プロセスで使用されるどの DECdtm 対応のリソース・マネージャ (RM) に対しても,正しいイベントを送信できるようになります。
XA Gateway の操作は,RM からは透過的です。
このため,DECdtm の RM は,何も変更することなく XA Gateway で使用することができます。
XA Gateway では,ログ・ファイルを使用して,XA のトランザクションと DECdtm のトランザクションとのマッピングを記録します。
このログ・ファイルは,ゲートウェイ・サーバ・プロセス DDTM$XG_SERVER によって管理されます。
ゲートウェイ・ログ・ファイルは,XGCP ユーティリティを使用して作成します
(『OpenVMS システム管理 ユーティリティ・リファレンス・マニュアル』を参照)。
ゲートウェイ・ログ・ファイルのサイズは,同時にアクティブになっているトランザクションの数によって決まります。
サイズは,XA TM が使用するトランザクション ID (TID) のサイズによって異なりますが,アクティブな各トランザクションごとに,最大で 600 バイトが必要です。
このゲートウェイ・ログ・ファイルは,必要に応じて自動的に拡張されます。
ゲートウェイ・ログ・ファイルは,論理名 SYS$JOURNAL によって指定されたディレクトリに常駐し,フォームの名前は SYSTEM$name.DDTM$XG_JOURNAL になります。
性能の最適化のために,各ゲートウェイ・ログ・ファイルおよび DECdtm ログ・ファイルを,個別の物理デバイスに移動し,物理デバイスのセットに対する検索リストとして SYS$JOURNAL を定義します。
XA Gateway では,各 OpenVMS Cluster ノードごとに,XA トランザクション・マネージャと XA Gateway ログ・ファイルとの間に関連付けが必要です。
この関連付けは,ゲートウェイ名を以下のように指定することによって管理されます。
-
XGCP ユーティリティを使用して,ゲートウェイ名と同じ名前のゲートウェイ・ログ・ファイルを作成する (『OpenVMS システム管理 ユーティリティ・リファレンス・マニュアル』を参照)。
-
ゲートウェイ名は,XA TM の制御下で実行されるアプリケーション内で Gateway RM が設定されるときに,xa_open 情報文字列内で指定される (XA RM の設定については,『OpenVMS Programming Concepts Manual, Volume II』を参照)。
-
XA TM によって実行される最初の XA アプリケーションにより,ゲートウェイ名が OpenVMS Cluster のローカル・ノードに結び付けられる。
ゲートウェイ・サーバが終了するまで,ゲートウェイ名は,そのノードに結び付けられたままになる。
同じローカル・ノードで実行されるすべての XA アプリケーションは,同じゲートウェイ名を使用して設定する必要があります。
同じ名前を使用している複数の XA アプリケーションを,他の OpenVMS Cluster ノードで実行することはできません。
したがって,通常は OpenVMS Cluster の各ノードごとに,1 つのゲートウェイ名を定義し,1 つのゲートウェイ・ログ・ファイルを作成します。
ゲートウェイ名の関連付けを変更して,ゲートウェイ名を別の OpenVMS Cluster ノードに結び付けることができます。
ただし,そのノードがゲートウェイ・ログ・ファイルにアクセスできることが必要条件です。
ゲートウェイ名の関連付けを変更するには,以下の手順を実行します。
-
元のノードで実行中のすべての XA アプリケーションを終了する。
-
XGCP ユーティリティを使用して,元のノードで実行中のゲートウェイ・サーバを終了する。
-
新しいノードで実行中のすべての XA アプリケーションを終了する。
-
新しいノードで実行中のゲートウェイ・サーバを終了し,ゲートウェイを再起動する。
-
新しいノードで,元の XA アプリケーションを実行する。
ゲートウェイ・ログ・ファイルはサイズが大きいので,できるだけ削除しないようにしてください。
不要なゲートウェイ・ログ・ファイルをどうしても削除する場合には,まず DECdtm XGCP ユーティリティを使用して,このゲートウェイがもうどの用意されたトランザクションの参加者にもなっていないことを確認します。
このゲートウェイの参加者名は DDTM$XG/name です。
ゲートウェイ・サーバは,以下のシステム論理名を使用します。
-
SYS$DECDTM_XG_REQS
サーバによって処理される同時要求の数で,範囲は 100 ~ 100,000 です。
この数により,DDTM$XG がサーバとやりとりするために使用するグローバル・セッションのサイズと,サーバで必要とされる制限値が決まります。
このパラメータは,論理名 SYS$DECDTM_XG_REQS を定義することによって指定されます。
このパラメータへの変更は,サーバとすべてのクライアント・プロセスが終了されるまで,有効になりません。
処理中にこのパラメータの値が制限値を超えた場合には,クライアント要求は,並行して処理されるのではなく,ブロックされます。
-
SYS$DECDTM_XA_TRANS
XA の同時トランザクションの予想される数の範囲は,1000 ~ 1,000,000 です。
これにより,サーバ内部で使用されるインデックス・テーブルのサイズが決まります。
このパラメータは,論理名 SYS$DECDTM_XA_TRANS を定義することによって指定されます。
このパラメータへの変更は,サーバが終了されるまで有効になりません。
処理中にこのパラメータの値が制限値を超えた場合には,サーバによる CPU の使用量が増加します。
しかしながら,その影響は,このパラメータの値が制限値の 10 倍以上にならないと目立ちません。