9.4.2 入力レコードの包含 |
 |
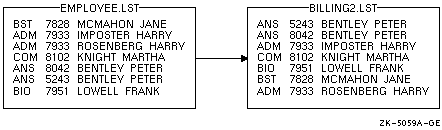
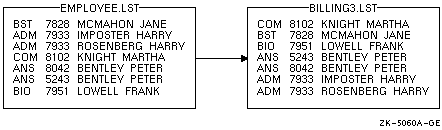
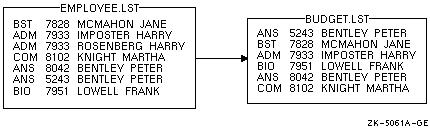
バッチ・ジョブには,入力レコードを含めておくことができます。これには,SORT コマンドの後に入力レコードを 1 行に 1 つずつ指定します。ただし,個々のソート・レコードは 2 行以上になってもかまいません。
レコードをターミナルから入力する場合と同様に,入力ファイル・パラメータには SYS$INPUT を指定します。その後に /FORMAT 修飾子を使用して,レコード・サイズ ( バイト数 ) とおおよそのファイル・サイズ(ブロック数)を指定します。 80 文字の行が 6 行で 1 ブロックとほぼ等しくなります。
次の例は,入力レコードを含めたコマンド・プロシージャを示しています。
! SORTJOB.COM
!
$ SET DEFAULT [USER.PER]
$ SORT/KEY=(POSITION:10,SIZE:15) -
SYS$INPUT-
/FORMAT=(RECORD_SIZE:24,FILE_SIZE:10) -
BYNAME.LST
$ DECK
BST 7828 MCMAHON JANE
ADM 7933 ROSENBERG HARRY
COM 8102 KNIGHT MARTHA
ANS 8042 BENTLEY PETER
BIO 7951 LOWELL FRANK
$ EOD
|
MERGE コマンドは,最大で 10 個 ( 高性能 Sort/Merge ユーティリティの場合は,最高で 12 個 ) のソート済みのファイルをまとめて,レコードが順に並べられた 1 つの出力ファイルを作成します。マージする入力ファイルは,同じ形式を持ち,同じキー・フィールドに基づいてソートされていなければなりません。
省略時の設定では,Merge は,入力ファイルの中のレコードをチェックして,正しい順序で並べられているかどうかを確認します。 Merge で順序をチェックする必要がなければ, /NOCHECK_SEQUENCE 修飾子を指定します。 /CHECK_SEQUENCE 修飾子を指定し,レコードの順序が正しくない場合, ( たとえば,入力ファイルのどれかをソートしていなかった場合 ), Merge では以下のエラーをレポートします。
%SORT-W-BAD_ORDER, merge input is out of order
|
MERGE コマンドと SORT コマンドは,同じ修飾子を使用できます。ただし,次の 2 つの例外があります。
- マージ操作にはプロセス (/PROCESS) を指定できない。
- /CHECK_SEQUENCE 修飾子はマージ操作にだけ使用される。
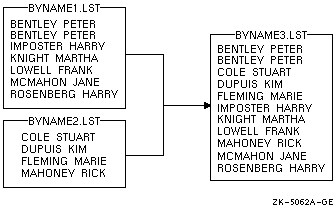
次の例では,ファイル BYNAME1.LST と BYNAME2.LST は,従業員名によってすでに昇順にソートされています。ここに示したコマンドは,これらをマージします。
$ MERGE BYNAME1.LST,BYNAME2.LST BYNAME3.LST
|
出力ファイル BYNAME3.LST には,次の図に示すように, BYNAME1.LST と BYNAME2.LST の両方のファイルのすべてのレコードが含まれます。