7.1.2 Alpha プロセッサ・ファミリの概要 |
 |
Alpha は 64 ビットのロード/ストア RISC アーキテクチャであり,パフォーマンスに最も影響を与える 3 つの要素に特に重点を置いて設計されています。 3 つの要素とは,クロック速度,複数のインストラクションの発行,および複数のプロセッサです。
Alpha の設計者たちは,最新の理論上の RISC アーキテクチャ設計要素を調査,分析し,ハイパフォーマンスな Alpha アーキテクチャを開発しました。
Alpha アーキテクチャは,特定のオペレーティング・システムやプログラミング言語に偏らないように設計されています。 Alpha ではオペレーティング・システムとして OpenVMS Alpha,Tru64 UNIX,および Linux がサポートされ,これらのオペレーティング・システムで動作するアプリケーションに対して簡単なソフトウェア移行がサポートされています。
Alpha は 64 ビット・アーキテクチャとして設計されました。すべてのレジスタのサイズが 64 ビットであり,すべての操作が 64 ビット・レジスタ間で実行されます。当初は 32 ビット・アーキテクチャとして開発され,後で 64 ビットに拡張されたのではありません。
インストラクションは非常に単純です。すべてのインストラクションが 32 ビットです。メモリ操作はロードとストアのいずれかです。すべてのデータ操作がレジスタ間で行われます。
Alpha アーキテクチャには特殊なレジスタや条件コードがないため,同じ操作の複数のインスタンスをパイプライン化するのは簡単です。
レジスタまたはメモリに書き込む 1 つの命令と,同じ場所から読み取りを行う別の命令とは相互に調整をします。このため,同時に複数の命令を実行する CPU の実装が簡単にできます。
Alpha では,複数のインプリメンテーション間でバイナリ・レベルの互換性を容易に維持でき,複数インストラクション発行のインプリメンテーションで完全な速度を簡単に維持できます。たとえば,インプリメンテーション固有のパイプライン・タイミングによる危険性,ロードディレイ・スロット,および分岐ディレイ・スロットはありません。
Alpha アーキテクチャでは,LDBU インストラクションと STB インストラクションを使用して,レジスタおよびメモリ間でバイトの読み書きを行います (Alpha では,LDWU および STW インストラクションによるワード読み書きもサポートされます)。バイト・シフトとマスキングは,通常の 64 ビット・レジスタ間インストラクションによって実行されます (インストラクション・シーケンスが長くならないように工夫されています)。
第 2 のプロセッサ (I/O デバイスを含む) から見ると, 1 つのプロセッサが発行した一連の読み取りと書き込みは,インプリメンテーションによって任意の順序に変更される可能性があります。このため,インプリメンテーションではマルチバンク・キャッシュ,バイパスされた書き込みバッファ,書き込みマージ,エラー発生時にリトライするパイプライン書き込みなどを使用できます。 2 つのアクセスの順序を厳密に維持しなければならない場合は,プログラムにメモリ・バリア命令を明示的に挿入できます。
基本的なマルチプロセッサ・インターロック機構は RISC スタイルの load_locked,modify, store_conditional シーケンスです。割り込みや例外,あるいは別のプロセッサからの妨害的な書き込みが発生せずに,シーケンスが実行されると,条件付きストアは正常終了します。割り込みや例外などが発生すると,ストア操作は失敗し,プログラムは最終的に元に戻って,シーケンスをリトライしなければなりません。このスタイルのインターロックは非常に高速のキャッシュにも対応できるため,複数のプロセッサが搭載されたシステムを構築するためのアーキテクチャとして, Alpha を特に魅力的なものにしています。
PALcode (privileged architecture library) は,特定の Alpha オペレーティング・システム・インプリメンテーションに固有のサブルーチンの集合です。これらのサブルーチンは,コンテキスト・スイッチング,割り込み,例外,およびメモリ管理のためのオペレーティング・システム・プリミティブを提供します。 PALcode は,パーソナル・コンピュータで提供される BIOS ライブラリのようなものです。
詳細については,『Alpha Architecture Handbook』(注文番号 EC-QD2KC-TE) を参照してください。
OpenVMS Alpha または OpenVMS VAX から OpenVMS I64 へのポーティングを行う場合,エンディアンに関する問題について考慮する必要はありません。どのプラットフォームでも,OpenVMS はデータの格納と操作でリトル・エンディアンを使用します。この章では,エンディアンが異なるハードウェア・アーキテクチャ間でポーティングを行う際に,一般に考慮しなければならない問題点について,わかりやすく説明しています。
エンディアンとは,データがストアされる方法のことであり,マルチバイト・データ・タイプで各バイトを配置する方法を定義します。エンディアンが重要なのは,データを書き込んだマシンと異なるエンディアンのマシンでバイナリ・データを読み込もうとすると,異なる結果になるからです。データベースをエンディアンの異なるアーキテクチャに移動しなければならない場合には,このことが特に重要な問題になります。
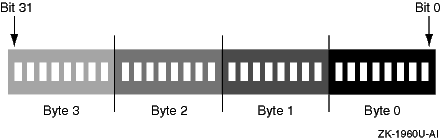
エンディアンには,ビッグ・エンディアン (順方向バイト順,つまり MSF (most significant first)) とリトル・エンディアン (逆方向バイト順,つまり LSF (least significant first)) の 2 種類があります。エンディアンについて考える場合は,「big end in」と「little end in」という覚え方をすると便利です。
図 7-1 と 図 7-2 は, 2 つのバイト順方式を比較しています。
図 7-1 ビッグ・エンディアン・バイト順
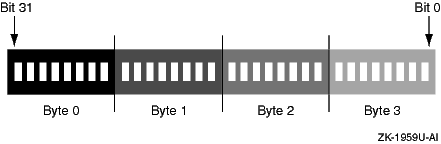
図 7-2 リトル・エンディアン・バイト順
Alpha マイクロプロセッサでは OpenVMS や Tru64 UNIX などのオペレーティング・システムでリトル・エンディアン環境を提供し, PA-RISC マイクロプロセッサでは HP-UX オペレーティング・システムでビッグ・エンディアン環境を提供しています。
OpenVMS などのリトル・エンディアン・オペレーティング・システムでは,リトル・エンド,つまり,最下位有効バイトが最下位アドレスに格納されます。たとえば,0x1234 という 16 進数は 0x34 0x12 としてメモリに格納されます。 4 バイト値の場合も同様です。たとえば,0x12345678 は 0x78 0x56 0x34 0x12 として格納されます。ビッグ・エンディアン・オペレーティング・システムではこれとは逆の順に格納されます。たとえば,0x1234 は 0x12 0x34 としてメモリに格納されます。
4 バイト整数として格納されている 1025 (2 の 10 乗 + 1) という数値について考えてみましょう。メモリでは,この数値は以下のように表現されます。
リトル・エンディアン: 00000000 00000000 00000100 00000001
ビッグ・エンディアン: 00000001 00000100 00000000 00000000
|
Intel Itanium プロセッサ・ファミリ・アーキテクチャでは,ビッグ・エンディアンとリトル・エンディアンの両方のメモリ・アドレッシングがサポートされます。 Itanium プロセッサで動作する OpenVMS I64 と OpenVMS Alpha の間には,データの読み込みおよびデータ交換に関する問題はありません。 Alpha または I64 システム上の OpenVMS と, PA-RISC または Itanium プロセッサ・ファミリの HP-UX の間でデータを交換する必要がある場合は,バイトの入れ換えが必要になることがあります。
