OpenVMS
OpenVMS
ユーザーズ・マニュアル
第 9 章
ファイルのソートとマージ
本章では,OpenVMS の Sort/Merge ユーティリティ (SORT/MERGE) の使用方法について説明します。 Sort/Mergeユーティリティは,次の 2 種類の作業を実行します。
- 選択した フィールド に従い, 1 つまたは複数の入力ファイルからレコードを読み込んでソートし,順序変更した出力ファイルを生成する。
- あらかじめ同じ
キー・フィールドでソートした入力ファイルを,最高で 10 ファイルをマージし, 1 個の出力ファイルを生成する ( 高性能 Sort/Merge ユーティリティの場合,最高で 12 個の入力ファイルがサポートされている )。
Alpha システムでは, 高性能 Sort/Merge ユーティリティ を選択することもできます。このユーティリティでは,Alpha アーキテクチャを活用することにより,ほとんどの Sort 操作および Merge 操作で性能を向上させることができます。詳細は 第 9.1 節 を参照してください。
本章では,次のことを説明します。
- 高性能 Sort/Merge
- ファイルのソート
- 照合順序の指定
- バッチ・ジョブとしてのソートの実行
- ファイルのマージ
- ターミナルからのレコードの入力
- Sort/Merge 指定ファイルの使用方法
- ソートまたはマージ操作の最適化
- Sort/Merge の修飾子の要約
その他の情報については,次のマニュアルを参照してください。
- この章で使用するコマンドについては,『OpenVMS DCL ディクショナリ』を参照してください。
- Sort/Merge ユーティリティ使用時のシステム管理者による効率化については,『OpenVMS システム管理者マニュアル』を参照してください。
Alphaシステムでは,
高性能Sort/Mergeユーティリティ を選択することもできます。このユーティリティでは,Alphaアーキテクチャを活用することにより,ほとんどの Sort 操作および Merge 操作で性能を向上させることができます。
高性能 Sort/Merge ユーティリティは, SORT/MERGE と同じコマンド行インタフェースを使用します。高性能 Sort/Merge ユーティリティと SORT/MERGE との違いについては,本章で紹介します。
高性能 Sort/Merge ユーティリティを使用するときは,論理名 SORTSHR を使用します。次のように SORTSHR を定義して, SYS$LIBRARY にある高性能ソート実行可能プログラムを指定します。
$ define sortshr sys$library:hypersort.exe
|
SORT/MERGE に戻るときは,SORTSHR の割り当てを解除します。 SORTSHR が定義されていない場合, SORT/MERGE ユーティリティが省略時の値として設定されます。
 | 注意
メモリ割り当ての差分により,高性能 Sort/Merge ユーティリティで実行するときの性能は, Sort/Merge ユーティリティと同サイズの仮想メモリで実行可能なソート操作数と同数の操作回数に制限されることがあります。
この場合,プロセスに使用できる仮想メモリのサイズを増やすか,ワーキング・セットの範囲を減らします。システム・パラメータにより,仮想メモリのサイズ増加やワーキング・セット範囲の削減については,『 OpenVMS システム管理ユーティリティ・リファレンス・マニュアル』を参照してください。
|
高性能 Sort/Merge ユーティリティの動作は,ほとんど SORT/MERGE ユーティリティの動作と同じです。相違点は, 表 9-1 に示します。
サポートされていない修飾子を使用しようとしたり,サポートされていない値を修飾子に指定しようとしたりすると,高性能 Sort/Merge ユーティリティはエラーを表示します。
表 9-1 高性能 Sort/Merge ユーティリティ : SORT/MERGE との相違点
| キー・データ・タイプ
|
H-FLOATING および ZONED 10 進データ・タイプはサポートされていません。
BINARY データ・タイプ・キーのサイズは,1 バイト,2 バイト,4 バイト, 8 バイトのいずれかでなければなりません。 16 バイトのバイナリ・キーはサポートされていません ( これは OpenVMS Alpha の将来のリリースでサポートされる予定です)。
|
| 照合順序
|
NCS(National Character Set) 照合順序はサポートされていません ( これは OpenVMS Alpha の将来のリリースでサポートされる予定です)。/COLLATING_SEQUENCE 修飾子に NCS 照合順序を指定しないでください。 ASCII,EBCDIC,および MULTINATIONAL 照合順序はサポートされています。省略時の設定は ASCII です。
指定ファイルを使用して,照合順序を定義したり変更したりすることはできません ( これは OpenVMS Alpha の将来のリリースで解決される予定です)。
|
| 指定ファイル
|
指定ファイルはサポートされていません ( これは OpenVMS Alpha の将来のリリースでサポートされる予定です)。 /SPECIFICATION 修飾子は使用しないでください。
|
| 内部ソート・プロセス
|
レコードのソート・プロセスのみサポートされています ( これは OpenVMS Alpha の将来のリリースで解決される予定です)。/PROCESS=RECORD 修飾子を指定することも,または /PROCESS 修飾子を省略することもできます。 /PROCESS 修飾子で TAG,ADDRESS,および INDEX を指定しないでください。
|
| 統計情報
|
現在サポートされているのは次の統計情報です。
Records read (読み込まれたレコード数)
Records sorted (ソートされたレコード数)
Records output (出力されたレコード数)
Input record length (入力レコード長)
次の統計情報は利用できません。
Internal length (内部長)
Output record length (出力レコード長)
Sort tree size (ソート・ツリー・サイズ)
Number of initial runs (初期実行回数)
Maximum merge order (最大マージ順)
Number of merge passes (マージ・パス回数)
Work file allocation (ワーク・ファイル割り当て)
この機能の完全な実装は将来の OpenVMS Alpha リリースで行われる予定です。
|
ファイルをソートするときは,DCLのSORTコマンドを使用します。ソートする入力ファイルを複数指定するときは,それぞれのファイルをコンマで区切り,最終的に作成されるソート済みの出力ファイルの名前をその後に続けます。
オプションとして,ソートに使用する各フィールドのキーを指定することができます。それぞれのキーには,次の情報が含まれます。
- レコード内にあるキー・フィールドの開始位置(必須)
- キーのサイズ(必須)
- キーのデータ型
- レコードのソート順
- キーの優先順位
キーを指定しないでソートを行う場合,キーが1つだけ存在しており,このキー・フィールドが次のようになっているものと想定されます。
- レコードの最初の位置から開始する。
- すべてのレコードが含まれる。
- 文字データが含まれる。
- 昇順にソートが行われる。
次の 2 つの例は,省略時のキーが使用されています。
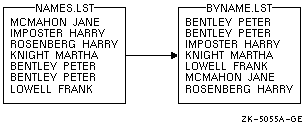
- 次の例では,NAMES.LST が昇順にソートされます。
$ SORT NAMES.LST BYNAME.LST
|
このコマンドは, 図 9-1 に示すように,出力ファイル BYNAME.LST を作成します。
図 9-1 昇順にソートした結果
- この例では,ファイル NAMES.LST と NAMES2.LST をソートして,出力ファイル BYNAME.LST に出力します。 2 つのファイルは,1 つの大きなファイルとして扱かわれ,ソートされます。
$ SORT NAMES.LST,NAMES2.LST BYNAME.LST
|
すべての SORTの修飾子の一覧については,
第 9.9 節 を参照してください。
9.2.1 キーの定義 |  |
キーを定義するときは,/KEY 修飾子を使用します。複数のキーを指定するときは,それぞれのキーごとに /KEY 修飾子を使用します。
表 9-2 は,キーを構成する5つの要素について説明しています。
表 9-2 /KEY修飾子の値
| キーの位置
|
POSITION:
n
|
レコード内にあるキー・フィールドの 1 バイト目の位置を表す。レコードの 1 バイト目が 1 になる。 POSITION:
n は必ず指定しなければならない。
|
| キー・サイズ
|
SIZE:
n
|
キー・フィールドの長さを表す。浮動小数データの場合を除き, SIZE:
n は必ず指定しなければならない。
キーに指定するデータ型により,サイズを指定するときに受け付けられる値が決まる。次の表は,それぞれのデータ型に対応する値と,キーのサイズを指定するときに使用する単位を表す。
| 文字
|
1〜32,767
|
文字
|
| バイナリ
|
1,2,4,8,16( 高性能 Sort/Merge ユーティリティでは,バイナリ・データ・タイプのサイズは 1 バイト,2 バイト,4 バイト,または 8 バイトでなければなるない。 16 バイトのバイナリ・データは OpenVMS Alpha の将来のリリースでサポートされる予定である。)
|
バイト
|
| 10進
|
1〜31
|
桁
|
| 浮動小数点
|
値は必要なし
|
10進データでは,10進記号が別のバイトに格納される場合,そのバイトはデータのサイズにカウントされない。 指定したキーがレコードの終わりを越えた場合,失われた文字は空文字として扱われる。
|
| データ型
|
CHARACTER
|
文字データ。CHARACTERが省略時のデータ型になる。
|
|
|
BINARY
|
バイナリ・データ。
SIGNED---符号付きバイナリ・データまたは符号付き10進データ。バイナリ・データおよび10進データの場合,SIGNEDが省略時の値になる。
UNSIGNED---符号なしバイナリ・データまたは符号なし10進データ。
|
|
|
F_FLOATING
|
F_FLOATING形式のデータ。
|
|
|
D_FLOATING
|
D_FLOATING形式のデータ。
|
|
|
G_FLOATING
|
G_FLOATING形式のデータ。
|
|
|
H_FLOATING
|
VAXシステムでは,H_FLOATING形式のデータになる (現在,高性能 Sort/Merge ユーティリティではサポートされていない)。
|
|
|
S_FLOATING
|
Alphaシステムでは,IEEE S_FLOATING形式のデータになる。
|
|
|
T_FLOATING
|
Alphaシステムでは,IEEE T_FLOATING形式のデータになる。
|
|
|
DECIMAL
|
10進データ。
TRAILING_SIGN---後続符号10進データ。 10進データの場合,TRAILING_SIGNが省略時の値になる。
LEADING_SIGN---先行符号10進データ。先行符号はフィールドの最初になければならず,フィールドの残りのスペースにはゼロが埋め込まれる。
OVERPUNCHED_SIGN---オーバパンチ10進データ。 10進データの場合,OVERPUNCHED_SIGNが省略時の値になる。
SEPARATE_SIGN---分割符号10進データ。
|
|
|
ZONED
|
ゾーン10進データ ( 現在,高性能 Sot/Merge ユーティリティではサポートされていない)。
|
|
|
PACKED_DECIMAL
|
パック10進データ。
|
| ソート順
|
ASCENDING
|
ソート操作を,英数字の昇順でソートする。ASCENDINGが省略時の順序になる。
|
|
|
DESCENDING
|
ソート操作を,英数字の降順でソートする。
|
| キーの優先順位
|
NUMBER:
n
|
複数のキーが優先順位に従ってリストされていない場合,それぞれのキーの優先順位を指定する。1 〜 255 までの値が指定できる。
|
キー・フィールドのデータが文字データでない場合は,データ型を指定する必要があります。 Sort/Merge ユーティリティでは,次のデータ型が認識されます。
| BINARY, [SIGNED]
|
|
| BINARY, UNSIGNED
|
|
| CHARACTER
|
|
| DECIMAL, LEADING_SIGN, SEPARATE_SIGN [SIGNED]
|
|
| DECIMAL, LEADING_SIGN, [OVERPUNCHED_SIGN, SIGNED]
|
|
| DECIMAL [,SIGNED, TRAILING_SIGN, OVERPUNCHED_SIGN]
|
|
| DECIMAL, [TRAILING SIGN], SEPARATE_SIGN, [SIGNED]
|
|
| DECIMAL, UNSIGNED
|
|
| D_FLOATING
|
|
| F_FLOATING
|
|
| G_FLOATING
|
|
| H_FLOATING
|
|
| S_FLOATING, IEEE (Alpha システムのみ)
|
|
| T_FLOATING, IEEE (Alpha システムのみ)
|
|
| PACKED_DECIMAL
|
|
| ZONED
|
|
[ ] かっこ内の項目は省略時の値になるため,指定する必要はありません。
| 注意
10 進文字列データの場合,VAX システムや Alpha システムと違って, Sort/Merge ユーティリティが,入力文字列の無効な桁について報告します。 VAX システムの場合,比較のために無効な桁 ( または予約オペランド ) が有効な 10 進文字列に変換されたというメッセージが表示されます。 Alpha システムの場合,Sort/Merge ユーティリティによって同じ変換が行われますが,メッセージが表示されません。どちらの場合も,入力ファイルのデータがそのまま出力ファイルに記述されます。
|
各レコードが (1) 部門名,
(2) アカウント番号,
(3) 従業員名の 3 つのフィールドから構成される EMPLOYEE.LST ファイルを例として考えてみます。 図 9-2 にこの 3 つのフィールドを示します。
図 9-2 リストの中のレコード・フィールド

次に,EMPLOYEE.LST のレコードをソートする例を示します。
- 次の例では,EMPLOYEE.LST はアカウント番号によってソートされ,アカウント番号フィールドを記述するために /KEY 修飾子を使用しています。
$ SORT/KEY=(POSITION:5,SIZE:4,DECIMAL) EMPLOYEE.LST BILLING1.LST
|
このコマンドは,キー・フィールド (アカウント番号) が位置 5 から始まること,長さが 4 文字であること,10 進データが格納されていること,昇順 (省略時の設定) でソートすることを指定しています。ソート結果を 図 9-3 に示します。
図 9-3 キー・フィールドによるソート

- 次の例は,キー・フィールドを指定せずに,ファイル EMPLOYEE.LST をソートする方法を示しています。
$ SORT EMPLOYEE.LST BYDEPT.LST
|
キーを指定していないので省略時の特性が使用されます。ソートの結果を 図 9-4 に示します。
図 9-4 ソート済みリスト (キー・フィールドなし)
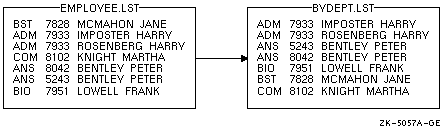
Sort は,EMPLOYEE.LST の中のそれぞれレコードを 1 つの文字データ・キーとして使用します。この例では,各レコードは,部門名,アカウント番号,従業員名で構成されています。重複する部門名がある場合,それらの部門名をアカウント番号の昇順にソートします。さらにアカウント番号もいくつか重複していた場合は,従業員名のアルファベット順にソートします。ここでアカウント番号はレコードの一部であることに注意してください。特に指定しない限り,アカウント番号は文字データとして処理されます。
|
