HP OpenVMS Systems Documentation |
Guide to OpenVMS File Applications
7.2.3 Handling Record-Locking ConflictsApplication programs that use shared files must handle record locking conflicts that may occur when two or more record streams try to access the same record. RMS provides three options for handling record locking conflicts:
The following table lists the options for having RMS handle record locking conflicts and how you select each option through the FDL and RMS interfaces.
The following sections describe each of these options.
When a service is denied record access because of a record conflict, it returns a record-locked error status (RMS$_RLK) that indicates the access attempt failed because the record was locked. One option is to have the application program pause briefly, and then try again to access the record. Example 7-1 contains a program fragment written in VAX MACRO that demonstrates one method of implementing a short pause between attempts to access a locked record.
For more information about process control techniques, see the
OpenVMS System Services Reference Manual.
Another option for handling record-locking conflicts is to use the wait-if-locked option to wait for the locked record to be released. When you take this option, the accessing service does not return until the record is released or until a specified wait period expires. The optional wait period is established using the wait-timeout-period option in conjunction with the wait-if-locked option. If the specified wait period expires before the requesting service obtains access to the locked record, the requesting service discards the request. The requesting service returns a completion status indicating that it waited for the locked record but was not granted access within the specified time period (RMS$_TMO).
If you select the wait-if-locked option and the requesting service must
wait to access the record, it returns an alternate success status that
indicates that it had to wait (RMS$_OK_WAT).
The third choice available to you for handling record-locking conflicts involves using the read-regardless (of lock) option. This option allows the accessing service to ignore a lock that prohibits read access. If a lock is granted under the specified record-locking option, access is granted and the service returns with the specified lock. If the lock is denied, the read-regardless option allows the accessing service, Get or Find, to read the record, regardless of the lock. The service returns without a lock for all three file organizations, but the returned status depends on the file organization:
An application program might use the read-regardless option to avoid record locking conflicts when a coordinated view of a record is not necessary. This option can also be used to continue sequential reads through a locked record.
Note that when you use the read-regardless option with the
wait-if-locked option and a wait timeout period, RMS acts on the
read-regardless option only after the wait timeout expires.
This section describes two miscellaneous record-locking options---the
manual-unlocking option and the lock-nonexistent-record option in a
relative file.
The manual-unlocking option gives the application program explicit control over releasing a record lock established by the Get service, the Find service, or the Put service as described in Section 7.2.1. Even if you select the manual-unlocking option, RMS unlocks affected records when a record stream is disconnected (Disconnect service), or when a file is closed (Close service). Other record operations, including operations that result in errors, do not unlock the record. To manually release record locks, the application program can invoke the Free service to unlock all record locks held by a record stream, or it can invoke the Release service to selectively release record locks, using the record's RFA. Manual unlocking is useful when you have to modify multiple records as part of a single transaction. For example, assume the application program must modify two related but separate records. Assume, too, that the modified first record must not be accessed by another record stream until modifications to the second record are completed.
While the program modifies the first record, it uses the
manual-unlocking option to hold the lock on the modified first record.
It then proceeds to modify the second record while still maintaining a
lock on the first record. By using manual unlocking, the application
program can restore the original contents of the first record if the
update to the second record fails, thereby maintaining data integrity.
The lock-nonexistent-record option applies only to random accessing of relative files. Relative files have a static physical structure made up of record cells in contrast to sequential files and indexed files, which have a dynamic structure. The record cells may or may not contain records. A record may have been deleted from a cell, or the cell may be empty (that is, it never contained a record). In either case, the record cells are accessible to the application program. Typically, if a record stream tries to access and lock an empty cell in a relative file using random access, the accessing service returns a record-not-found error status (RMS$_RNF). However, if the lock-nonexistent-record option is selected, the accessing service returns an alternative success status (RMS$_OK_RNF) indicating that the record stream accessed a cell that never contained a record. If the cell contains a deleted record, RMS returns the deleted record with an alternate success status (RMS$_OK_DEL) to indicate that a deleted record was accessed. The lock-nonexistent-record option prevents other record streams from putting a record into an empty cell until the locking record stream puts a record in it or releases the record lock. Any other record stream that tries to access the cell to put data into it receives a record-locked status (RMS$_RLK). If the record stream that has the lock puts a record into the cell, RMS returns an alternate success status (RMS$_OK_ALK) indicating that the cell was already locked. In general, the RMS$_OK_ALK status is returned when a service tries to lock a record that the current record stream has already locked. This also applies to the Put service, which locks and unlocks the record in one record operation. The next table lists miscellaneous record-locking options and how you select each option through the FDL and RMS interfaces:
7.2.5 Record-Locking DeadlocksA deadlock occurs when there is a set of processes and each process is waiting to access a record that is locked by another process in the set. The program stalls because none of the processes can acquire the record that it needs to complete its task and release its locks. The lock manager resolves the deadlock by denying one of the lock requests. When this occurs with a record lock, RMS returns an RMS$_DEADLOCK status. The RMS$_DEADLOCK status is only returned if the wait-if-locked option is selected. If your application program does its own wait and retry handling, the deadlock will occur, but the lock manager will not detect it.
The amount of time that lapses before RMS takes action on the deadlock
depends on the value specified in the DEADLOCK_WAIT system parameter.
The default value for this system parameter is 10 seconds. For further
details about how this parameter is set, see the OpenVMS System Manager's Manual.
RMS uses the distributed lock manager ($ENQ system service) for record locking. To help prevent false deadlocks, the distributed lock manager uses the following flags for lock requests.
1Improper use of these flags can result in the lock management services ignoring genuine deadlocks. For complete flag information, see the $ENQ section of the OpenVMS System Services Reference Manual: A--GETUAI. In previous releases to OpenVMS Version 7.2--1H1, RMS did not set these flags in its record lock requests. With OpenVMS Version 7.2--1H1, you can optionally request that RMS set these flags in record lock requests by setting the corresponding options RAB$V_NODLCKWT and RAB$V_NODLCKBLK in the new RAB$W_ROP_2 field. For more information about using these options, see the flag information in the $ENQ section of the OpenVMS System Services Reference Manual: A--GETUAI.
For more information about the lock manager, see the OpenVMS System Services Reference Manual.
One of the key performance factors is record buffering, that is, the
transfer of records between a storage device and an area of memory
accessible to the application program. Between the storage device and
the record buffer in the appliction program, however, is an
intermediate buffer area that RMS maintains. An intermediate buffer
area is usually associated with each process; you can also specify a
shared buffer area for a shared file.
For synchronous and asynchronous record operations, RMS provides two record transfer modes: move mode and locate mode. In move mode, RMS copies a record from an I/O buffer into a buffer that you specify. For input operations, data is first read into the I/O buffer from a peripheral device (such as a disk), then moved to your application program buffer for processing. For output operations, you first build the record in your application program buffer; then RMS moves the record to the I/O buffer that is used to transfer the record to disk. In locate mode, RMS allows the application program to access records in an I/O buffer by providing the address of the returned record as the internal buffer location instead of an application program buffer location (field RAB$L_RBF). Usually, this reduces program overhead because records can be processed directly within the I/O buffer. Locate mode is only available for input operations. Because it may not always be possible to use locate mode, you must supply an application program buffer for cases in which move mode must be used, even though you specify locate mode (see the OpenVMS Record Management Services Reference Manual).
Other RMS facilities allow programs to control I/O buffer space
allocation or to leave space management to RMS. The following sections
describe buffering.
Your program perceives RMS record processing as the movement of records between a file and the program itself. In fact, RMS uses internal memory areas called I/O buffers to read or write blocks or buckets of data. Transparent to your program, RMS transfers blocks or buckets of a file into or from an I/O buffer. Records within the I/O buffer are then made available to the program when RMS transfers the records between the I/O buffer and the application program's record buffer. The unit of data transfer between a file and the I/O buffers depends on the file organization. For the sequential organization, RMS reads and writes a block or series of blocks. For relative and indexed organizations, RMS reads and writes buckets. The relationship between the application program and the I/O buffers that RMS maintains is shown in Figure 7-2. As illustrated, the application program resides in the P0 region of process address space. The RMS-maintained buffer area, together with RMS-maintained control information, resides in the P1 region. Note that RMS normally overflows into P0 space and that the linker provides options for controlling the overflow. Note, too, that linker options are available for allocating additional buffer space in the P0 region, if needed. See the OpenVMS Linker Utility Manual for details. Figure 7-2 RMS Buffers and the Application Program 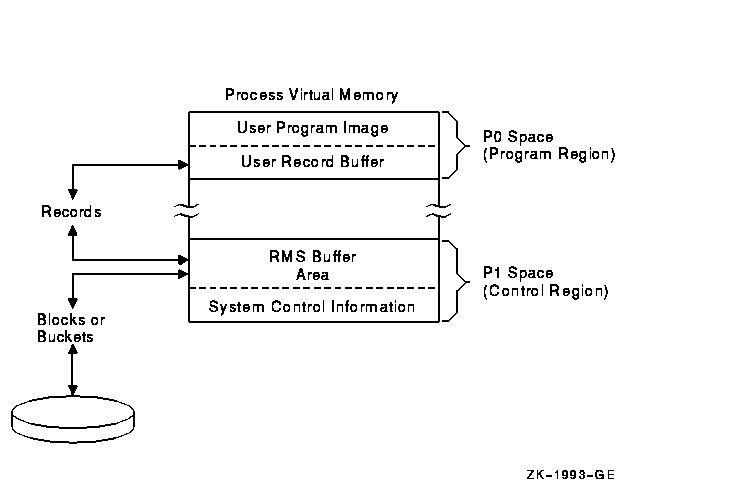
The specified record buffer contains the record to be read or written, and RMS maintains the rest of the block in application program process space in an RMS-controlled area of the program. For optimum performance, consider the number of buffers carefully. The defaults calculated by RMS are few and may be adequate for access to small files. For example, it is not unusual to specify many buffers when processing a large indexed file, yet the default number of buffers RMS provides is only two. The CONNECT secondary attribute MULTIBUFFER_COUNT establishes the number of local buffers, but the FILE secondary attribute GLOBAL_BUFFER_COUNT (FAB field FAB$W_GBC) specifies the number of global buffers as described in Section 7.3.6. Often the best way to achieve optimum buffering for a particular application program is to use combinations of buffer sizes and numbers of buffers. One approach is to time each combination and measure the number of I/O operations. Then consider the amount of memory used before you choose the one that improved application program performance the most. With buffering, the goal is to use a buffer size and number of buffers that improves application program performance without exhausting the virtual memory resources of your process or system. Keep in mind the trade-offs between file I/O performance and exhausting memory resources. The buffers used by a process are charged against the process's working set. You should avoid allocating so many buffers that the CPU spends excessive processing time paging and swapping. For performance-critical application programs, consider increasing the size of the process working set and adding additional memory. The system manager should monitor the paging and swapping activity of the application program's process and selected other processes to avoid improving the performance of the target application program at the expense of other application programs. Have your system manager consult the Guide to OpenVMS Performance Management 1 When records are accessed sequentially, a large buffer (or buffers) should be used. Contiguous records in a file are read into memory in one or more blocks for sequential files or in buckets (multiblock units) for relative and indexed files. After the blocks or buckets are read into the buffer area provided by RMS, later access to adjacent records would access records in the same block or bucket in the buffer. This eliminates additional I/O and improves performance. When a record is needed that is not in the current buffer cache, one of the buffers is replaced by the blocks or the bucket that contains the new record. When records in the file are repeatedly accessed, using more than one buffer can hold the previously accessed records in memory longer and eliminate an I/O operation when the program accesses the records again.
The buffers that the application program requests RMS to allocate for
its use are referred to as a buffer cache and can be
thought of as a buffer pool for your process. RMS uses buffer caches to
locate records first before attempting I/O to the target device. When
many processes share a file, the program can use a shared global buffer
cache. (See Section 7.3.6.)
With sequential files, the number of local buffers and the size of the local buffers can be specified at run time. You specify the number of local buffers with the FDL attribute CONNECT MULTIBUFFER_COUNT and you specify the buffer size with the FDL attribute CONNECT MULTIBLOCK_COUNT. Sequential files provide an option that uses two buffers. One buffer holds records to be read from the disk or written to the disk. The other buffer awaits I/O completion. This is called read-ahead and write-behind processing and should be considered for sequential access to sequential files. The number of buffers (CONNECT MULTIBUFFER_COUNT) should be specified as 2. The length of the buffers used for sequential files is determined by the specified multiblock count (CONNECT MULTIBLOCK_COUNT). For sequential access to a sequential file, the optimum number of blocks per buffer depends on the record size, but a value such as 16 is usually appropriate.
To see the default buffer count for the current process, use the DCL
command SHOW RMS_DEFAULT. To set the default buffer count for the
current process, use the DCL command SET
RMS_DEFAULT/SEQUENTIAL/BUFFER_COUNT=n, where n is the number
of buffers.
With relative files, buckets, not blocks, are the unit of transfer between the disk and memory. The bucket size is specified when the file is created, although the bucket size of an existing file can be changed by converting the file (see Chapter 10). The bucket size is specified by the FDL attribute FILE BUCKET_SIZE (VMS RMS control block field FAB$B_BKS or XAB$B_BKZ). When choosing this value, you should consider whether or not the file is usually accessed randomly (small bucket size), sequentially (large bucket size), or both (medium bucket size), as described in Chapter 2. You can specify the number of local buffers (CONNECT MULTIBUFFER_COUNT) at run time. The type of record access to be performed determines the best use of local buffers. The two extremes of record access are that records are processed completely randomly or completely sequentially. Also, there are cases in which records are accessed randomly but may be reaccessed (random with temporal locality), and cases in which records are accessed randomly but adjacent records are likely to be accessed (random with spatial locality). For completely random or sequential access, a single buffer should be specified. In a processing environment in which the program processes records randomly and sometimes reaccessed records, use multiple buffers to keep the reaccessed records in the buffer cache. When records are accessed randomly and adjacent records are apt to be accessed, you should specify a single buffer. However, if your program is processing a file with small bucket sizes, you should consider specifying more buffers. When the file is likely to be accessed by several methods, you should consider a compromise of the number of buffers and bucket sizes. When adding records to a relative file, consider choosing the deferred-write option (FDL attribute FILE DEFERRED_WRITE; FAB$L_FOP field FAB$V_DFW). With this option, the buffer (memory-resident bucket) into which the records have been moved is not written to disk until the buffer is needed for other purposes or until the file is closed. Note that if you use the deferred-write option, there is a risk that data may be lost if a system crash occurs before the records are written to disk. To see the current process-default buffer count, use the DCL command SHOW RMS_DEFAULT. To set the process-default buffer count, use the DCL command SET RMS_DEFAULT/RELATIVE/BUFFER_COUNT=n, where n is the number of buffers.
|