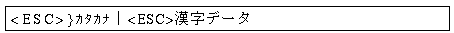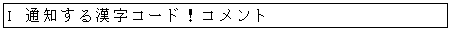7.4.2 1983 年版から 1978 年版への変換 |
 |
DEC 漢字1983 年版の漢字コードを DEC 漢字 1978 年版に変換する場合は,以下の変換テーブルを使用します。
JSY$SYSTEM:KCV83TO78.TABLE
|
このテーブルでは,次の項目が指定されています。
- 8区の罫線コードを 1978 年版の拡張領域の罫線コードに変換する
- 第1水準と第2水準の位置が交換された漢字コードを置換する
- 84 区の4つの漢字は 1978 年版のコードに変換する
- 字形が変わった漢字はそのまま(通知のみ)
- 1983 年版で追加された特殊文字はそのまま(通知のみ)
変換を行うには,次のようにします。
$ KCONVERT/TABLE=JSY$SYSTEM:KCV83TO78.TABLE [/修飾子] 入力ファイル名
[出力ファイル名]
|
日本語 OpenVMS が標準として提供するのは上の2つのテーブルのみです。変換を罫線コードに限定するなど変換内容を変える場合は,新たに変換テーブルを作成してください。
KCONVERT ユーティリティが使用しているルーチンがランタイム・ライブラリとして JSY$LIBRARY:JSYLIB.OLB
に入っています。また,ステータス定義ファイルとしては JSY$SYSTEM:JSYDEF.*
(* は FOR,H など各言語用) があります。
KCONVERT ユーティリティでは処理できない場合は,コード変換ルーチンを用いて専用の変換プログラムを作成してください。
各ルーチンについては『日本語ライブラリ 利用者の手引き』を参照してください。