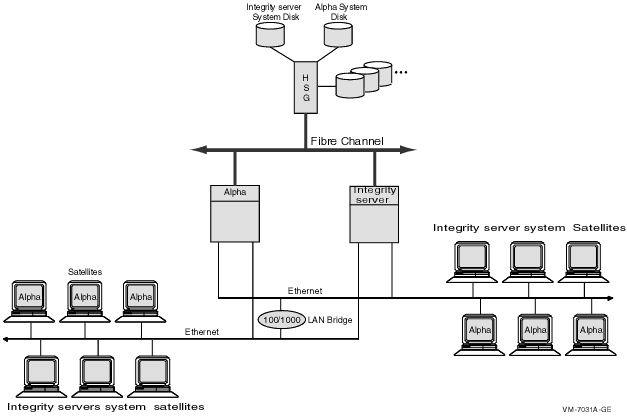
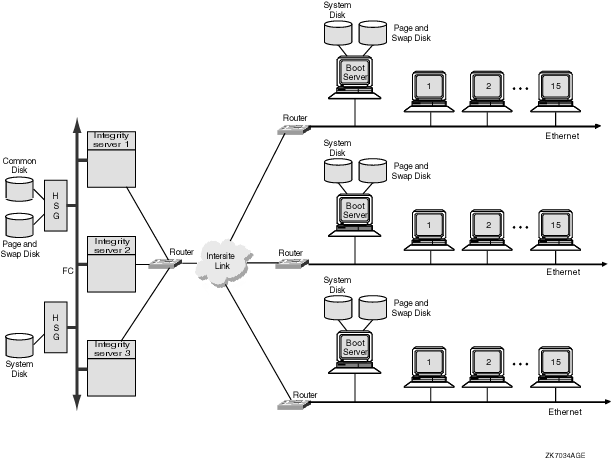
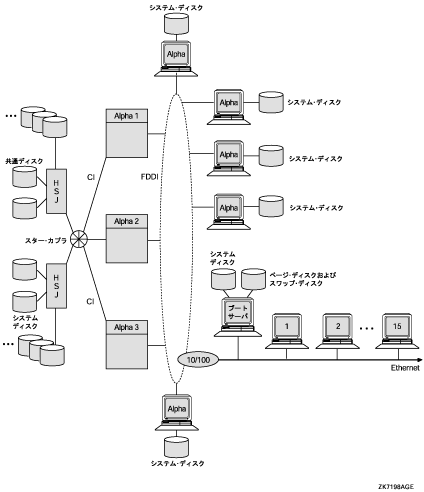
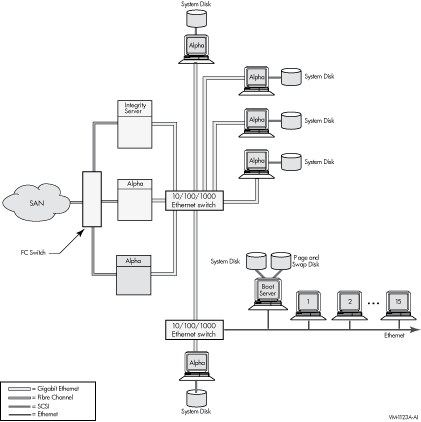
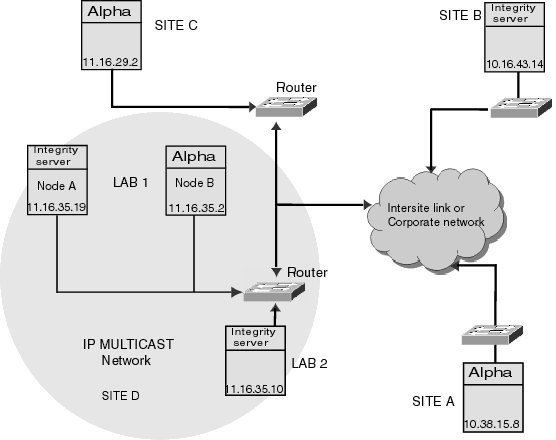
9.5.2 IP ベース・クラスタの構成上のガイドライン |
 |
以下に示すのは, IP クラスタ通信を使用してクラスタを構成する場合のガイドラインです。
- リモート・ノードの識別には IP ユニキャスト・アドレスが必要です。
- システム管理者が相手先を指定しクラスタ・グループ番号で動的に計算される IP マルチキャスト・アドレスが必要です。クラスタ構成については,『OpenVMS Cluster システム』を参照してください。
- ネットワーク・マスク・アドレスとともにローカル・マシンの IP アドレスが必要となります。
- IP アドレスを設定し SCS に使用されるローカル LAN アダプタが必要になります。
OpenVMS Cluster の拡張性にとって,I/O のスケーラビリティは重要な要素です。 OpenVMS Cluster に構成要素を追加する場合,追加した構成要素がボトルネックになったり,OpenVMS Cluster 全体のパフォーマンスが低下するのを防ぐため,高い I/O スループットが必要になります。I/O スループットに影響を与える要素は,以下のとおりです。
- ストレージに対する直接アクセスや MSCP サービスによるアクセス
- MSCP_BUFFER および MSCP_CREDITS システム・パラメータの設定
- Files-11 などのファイル・システム・テクノロジ
- 磁気ディスク,半導体ディスク,DECram などのディスク・テクノロジ
- 読み込み/書き込みの比率
- I/O サイズ
- キャッシュとキャッシュ "ヒット" 率
- "ホット・ファイル" 管理
- RAID ストラインピングとホスト方式のストラインピング
- ボリューム・シャドウイング
以上の要素は,I/O スケーラビリティそのものに影響する場合と,スケーラビリティの組み合わせに影響する場合があります。以下の項では,以上の要素について説明するとともに,アプリケーションに変更を加えずに I/O スループットとスケーラビリティを最大限に発揮する方法を説明します。
その他,I/O スループットに対しては,インターコネクトやストレージ・サブシステムの種類が影響します。
関連項目: インターコネクトの詳細については 第 4 章 を,ストレージ・サブシステムの詳細については 第 5 章 を参照してください。 MSCP_BUFFER および MSCP_CREDITS の詳細については,『OpenVMS Cluster システム』を参照してください。